Representations
The same graph can be stored three completely different ways, and picking wrong costs you either memory or speed — sometimes both. Most competitive programmers default to adjacency lists without thinking. That's usually right. But "usually" isn't "always," and the exceptions matter.
The Three Representations
Consider this undirected graph with 4 nodes and 4 edges:
Edges: (0,1), (1,2), (2,3), (3,0).
1. Adjacency List
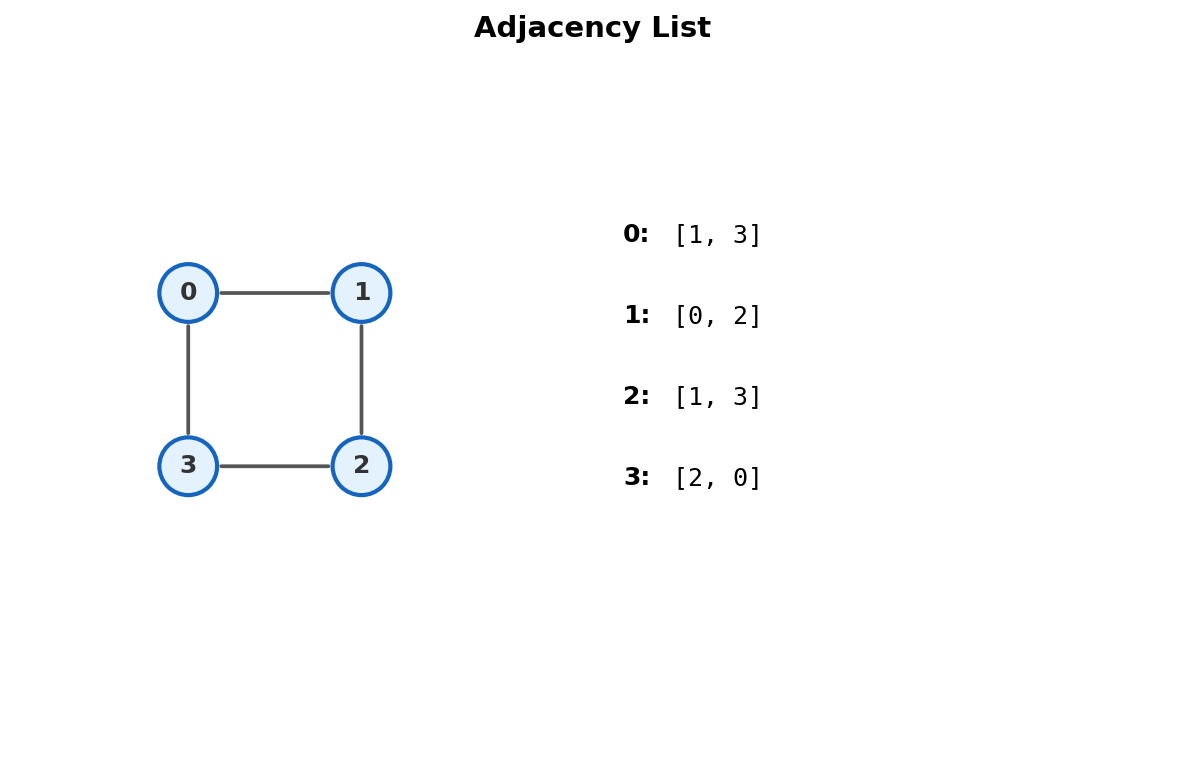
For each node, store the list of its neighbors.
vector<vector<int>> adj(4);
// After adding all edges (both directions):
// adj[0] = {1, 3}
// adj[1] = {0, 2}
// adj[2] = {1, 3}
// adj[3] = {2, 0}
Each edge appears twice (once per endpoint) for undirected graphs, once for directed.
2. Adjacency Matrix
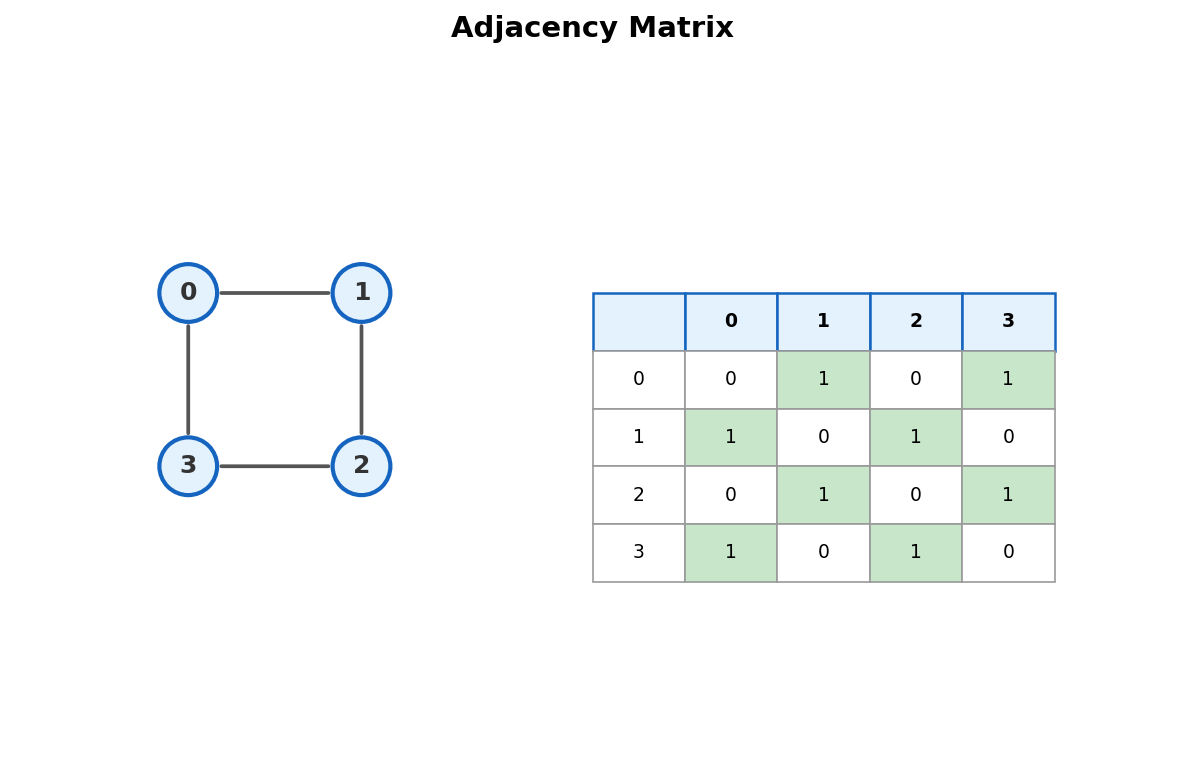
A \(V \times V\) grid where mat[u][v] = 1 if edge \((u,v)\) exists.
Symmetric for undirected graphs. For weighted graphs, store the weight instead of 1.
3. Edge List
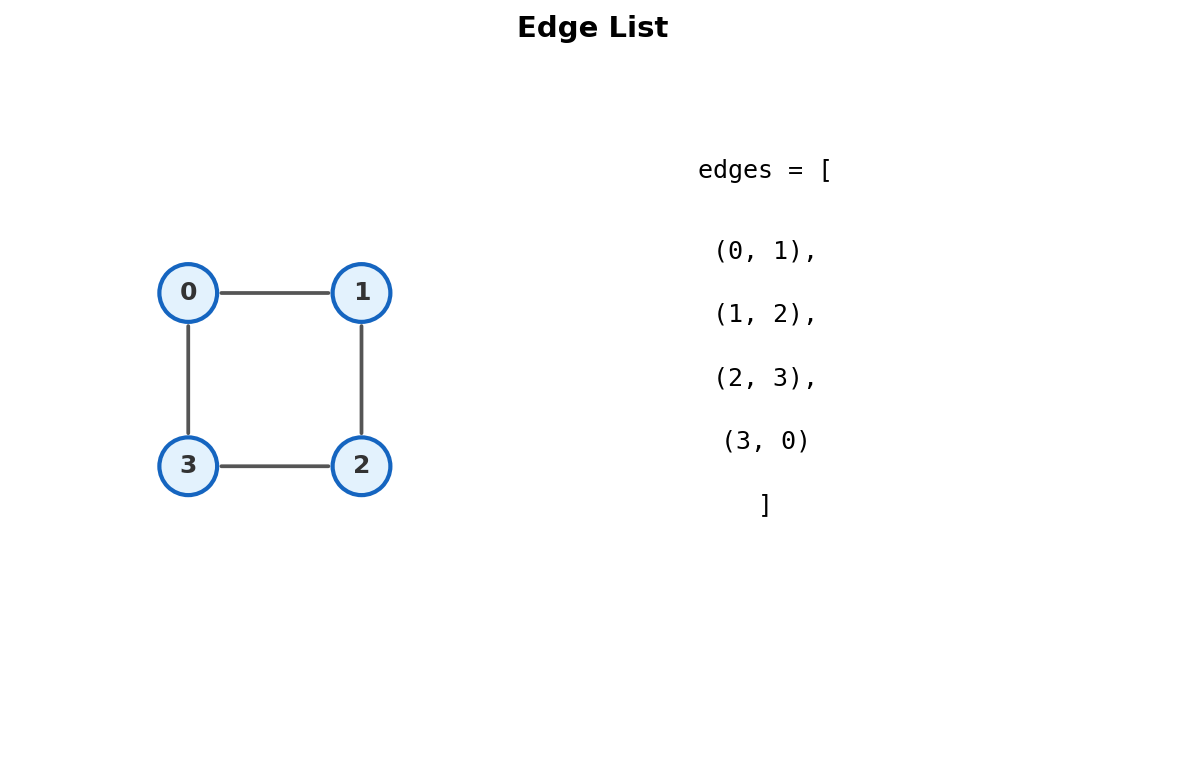
A flat list of all edges.
No per-node structure. Just edges in a bag.
When to Use Each
| Representation | Space | Add edge | Check edge \((u,v)\)? | Iterate neighbors of \(u\) |
|---|---|---|---|---|
| Adjacency list | \(O(V + E)\) | \(O(1)\) | \(O(\text{deg}(u))\) | \(O(\text{deg}(u))\) |
| Adjacency matrix | \(O(V^2)\) | \(O(1)\) | \(O(1)\) | \(O(V)\) |
| Edge list | \(O(E)\) | \(O(1)\) | \(O(E)\) | \(O(E)\) |
Adjacency list — the default
Use it unless you have a specific reason not to. It's space-efficient, fast to iterate neighbors, and works for both sparse and moderately dense graphs.
DFS, BFS, Dijkstra, topological sort — all of these iterate neighbors of the current node. That's exactly what adjacency lists are optimized for.
Adjacency matrix — dense or small graphs
Use it when:
- \(V\) is small (\(V \leq 500\) or so) and you need \(O(1)\) edge lookups.
- The graph is dense (close to \(V^2\) edges), so the matrix doesn't waste much space.
- All-pairs problems like Floyd-Warshall, which operates directly on the matrix.
- Checking "is there an edge between \(u\) and \(v\)?" is a frequent operation.
Gotcha. An adjacency matrix for \(V = 10{,}000\) uses \(10^8\) entries. That's 400 MB for
int. You'll hit memory limits before time limits. Always check \(V\) before reaching for a matrix.
Edge list — when edges are the unit of work
Use it when:
- Kruskal's MST — you sort all edges by weight.
- Bellman-Ford — you iterate over all edges \(V-1\) times.
- The problem gives you edges and you don't need neighbor iteration.
Edge lists are terrible for "give me all neighbors of node 5" — you'd scan every edge. But they're perfect when you process edges independently.
Building the Adjacency List
This is the most common input pattern in competitive programming:
int n, m;
cin >> n >> m;
vector<vector<int>> adj(n);
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
adj[u].push_back(v);
adj[v].push_back(u); // remove for directed
}
Build Trace
| Edge read | adj[0] | adj[1] | adj[2] | adj[3] | adj[4] |
|---|---|---|---|---|---|
| (0,1) | {1} | {0} | {} | {} | {} |
| (0,3) | {1,3} | {0} | {} | {0} | {} |
| (1,2) | {1,3} | {0,2} | {1} | {0} | {} |
| (1,4) | {1,3} | {0,2,4} | {1} | {0} | {1} |
| (2,3) | {1,3} | {0,2,4} | {1,3} | {0,2} | {1} |
| (3,4) | {1,3} | {0,2,4} | {1,3} | {0,2,4} | {1,3} |
Gotcha. Many problems use 1-indexed nodes. If the input says "nodes are numbered 1 to N," either use
vector<vector<int>> adj(n + 1)or subtract 1 from every node when reading. Mixing 0-indexed and 1-indexed is one of the most common graph bugs.
Directed vs Undirected: The One-Line Difference
For an undirected edge \((u, v)\), add it both ways:
For a directed edge \(u \to v\), add it once:
Forgetting the second line for undirected graphs means DFS from \(u\) finds \(v\), but DFS from \(v\) doesn't find \(u\). Your component count will be wrong. Your shortest paths will be wrong. Everything will be wrong.
Key insight. Read the problem statement carefully. "There is a road between cities \(u\) and \(v\)" is undirected. "There is a flight from city \(u\) to city \(v\)" is directed. The adjacency list code differs by exactly one line.
Weighted Adjacency List
When edges have weights, store pairs:
vector<vector<pair<int,int>>> adj(n); // {neighbor, weight}
for (int i = 0; i < m; i++) {
int u, v, w;
cin >> u >> v >> w;
adj[u].push_back({v, w});
adj[v].push_back({u, w}); // undirected
}
Iterating neighbors now gives you both the destination and the cost:
This is the format used by Dijkstra (Chapter 5) and Prim's MST (Chapter 13).
Implicit Graphs
Not every graph is given as a list of edges. Some graphs are defined by rules.
Grids. A 2D grid where each cell connects to its 4 (or 8) neighbors is a graph. The nodes are \((r, c)\) pairs. The edges are implicit — you compute them from the grid coordinates.
int dr[] = {-1, 1, 0, 0};
int dc[] = {0, 0, -1, 1};
// Neighbors of (r,c): (r+dr[i], c+dc[i]) for i=0..3
You never build an adjacency list for a grid. You compute neighbors on the fly.
Word ladders. Each word is a node. Two words are connected if they differ by one character. You could precompute all edges, but that's \(O(N^2 \cdot L)\). Instead, you generate neighbors by trying all character substitutions.
State spaces. A Rubik's cube has \(4.3 \times 10^{19}\) states. You can't store the graph. You generate neighbors (valid moves) from the current state.
We'll work with grids extensively in Chapter 2 and revisit implicit graphs in Chapter 11. For now, just know: a graph doesn't need to be stored to be traversed.
Adjacency Matrix Construction
For completeness, here's how you build an adjacency matrix:
int n, m;
cin >> n >> m;
vector<vector<int>> mat(n, vector<int>(n, 0));
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
mat[u][v] = 1;
mat[v][u] = 1; // undirected
}
For weighted graphs, store the weight and use a sentinel (like 0 or INT_MAX) for non-edges:
vector<vector<int>> mat(n, vector<int>(n, INT_MAX));
for (int i = 0; i < n; i++) mat[i][i] = 0;
mat[u][v] = w;
mat[v][u] = w;
This is exactly the setup for Floyd-Warshall all-pairs shortest paths.
Edge List Construction
struct Edge {
int u, v, w;
};
int m;
cin >> m;
vector<Edge> edges(m);
for (int i = 0; i < m; i++) {
cin >> edges[i].u >> edges[i].v >> edges[i].w;
}
// Sort by weight for Kruskal's
sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {
return a.w < b.w;
});
You'll see this exact pattern in Chapter 13 (MST) and Chapter 5 (Bellman-Ford).
Choosing a Representation: Decision Flowchart
- Is \(V > 2000\)? Don't use adjacency matrix. Space is \(O(V^2)\).
- Do you need to check "does edge \((u,v)\) exist?" in \(O(1)\)? Adjacency matrix. Or use
unordered_setinside your adjacency list. - Do you need to sort/iterate all edges as a batch? Edge list.
- Everything else? Adjacency list.
In practice, you'll use adjacency lists for 90% of problems, adjacency matrices for Floyd-Warshall and small dense graphs, and edge lists for Kruskal's.
Exercises
-
By hand. Given edges
(0,1), (0,2), (1,3), (2,3), (2,4)on 5 nodes: write out the adjacency list, the adjacency matrix, and the edge list. Verify the adjacency list has 10 entries total (5 undirected edges, each stored twice). -
1-indexed trap. A problem says: "N=4 nodes, numbered 1 to 4. Edges: 1-2, 2-3, 3-4." You write
vector<vector<int>> adj(4). What goes wrong when you read edge3-4and doadj[4].push_back(3)? -
Space calculation. A social network has 1 million users. Each user has ~150 friends on average. How much memory does the adjacency list use? How much would an adjacency matrix use? Which one fits in RAM?
-
Matrix to list. You're given a problem where the input IS an adjacency matrix (like LC 547 — Number of Provinces). How do you convert it to an adjacency list? Is conversion even necessary, or can you DFS directly on the matrix?
Problems
| Problem | Link | Difficulty |
|---|---|---|
| LC 997 — Find the Town Judge | leetcode.com/problems/find-the-town-judge | Easy |
| LC 547 — Number of Provinces | leetcode.com/problems/number-of-provinces | Medium |
| CSES — Building Roads | cses.fi/problemset/task/1666 | Easy |
| LC 1615 — Maximal Network Rank | leetcode.com/problems/maximal-network-rank | Medium |