Distributed Coordination
TL;DR
When multiple services or databases share a resource, single-DB locks don't work. Distributed locks (Redis SETNX, ZooKeeper, etcd), fencing tokens, and queue-based serialization provide coordination across services. Each tool has a different safety guarantee — pick the one that matches the stakes.
Why Single-DB Locks Break Down
In the previous lessons, every concurrency strategy assumed one database. SELECT FOR UPDATE works because all transactions go through the same PostgreSQL instance, which can coordinate them internally.
But the moment your architecture looks like this, single-DB locks are useless:
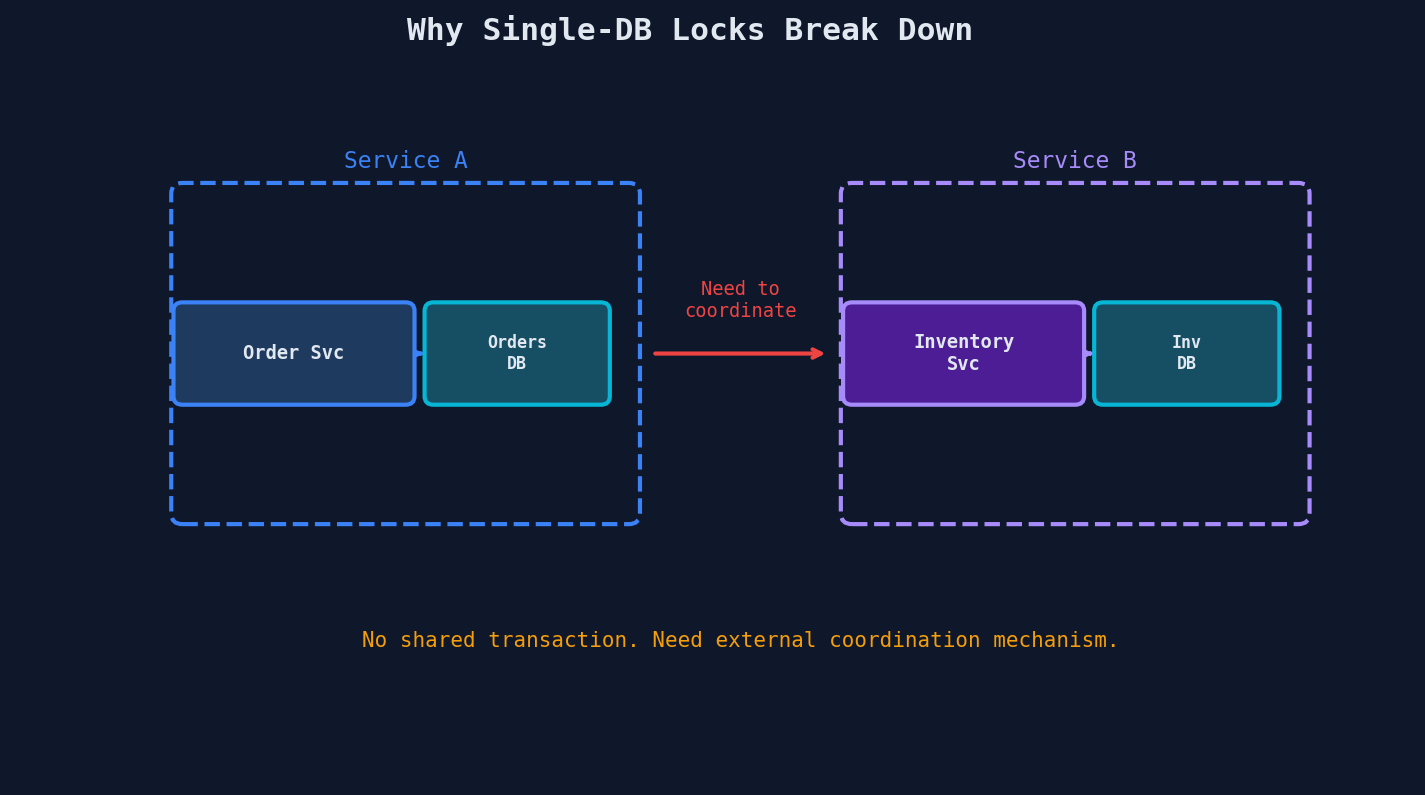
Service A holds a lock in Orders DB. Service B holds a lock in Inventory DB. Neither database knows about the other. There's no shared transaction coordinator, no shared lock table, no shared anything. You need an external coordination mechanism — something both services can talk to that acts as the single source of truth for "who owns this resource right now."
Three main approaches:
- Distributed locks — Redis, ZooKeeper, etcd
- Fencing tokens — monotonically increasing tokens that prevent stale writes
- Queue-based serialization — route all updates through a single ordered queue
Redis Distributed Lock
Redis is the most common choice for distributed locks because it's fast, widely deployed, and the implementation is straightforward.
The Basic Pattern
import redis
import uuid
import time
r = redis.Redis(host='localhost', port=6379)
def acquire_lock(lock_key: str, ttl_seconds: int = 30) -> str | None:
"""
Attempt to acquire a distributed lock.
Returns a unique token if successful, None if lock is held.
"""
token = str(uuid.uuid4())
# SET lock_key token NX EX 30
# NX = only set if key doesn't exist (atomic check-and-set)
# EX = expire after 30 seconds (prevents deadlock if holder crashes)
acquired = r.set(lock_key, token, nx=True, ex=ttl_seconds)
if acquired:
return token
return None
def release_lock(lock_key: str, token: str) -> bool:
"""
Release the lock ONLY if we still own it.
Uses Lua script for atomic check-and-delete.
"""
# Why Lua? Because we need to CHECK the value and DELETE the key
# in a single atomic operation. If we did GET then DEL separately,
# another client could acquire the lock between our GET and DEL,
# and we'd delete THEIR lock.
lua_script = """
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
"""
result = r.eval(lua_script, 1, lock_key, token)
return result == 1
Why the Unique Token Matters
Without a unique token, you get this disaster:

Client A's operation took longer than the TTL. The lock expired. Client B acquired it. Then Client A finished and deleted the lock — but it deleted Client B's lock, not its own. Now Client B is running without protection.
The unique token prevents this: Client A's release_lock checks if the stored value matches its token. It doesn't (Client B's token is stored now), so the DEL doesn't execute. Client B's lock stays intact.
Usage Pattern
def process_order(order_id: str):
lock_key = f"lock:order:{order_id}"
token = acquire_lock(lock_key, ttl_seconds=30)
if token is None:
raise ConflictError("Order is being processed by another service")
try:
# Do the critical work
charge_payment(order_id)
reserve_inventory(order_id)
send_confirmation(order_id)
finally:
release_lock(lock_key, token)
The Redlock Controversy
Redis locks have a known weakness: they rely on a single Redis instance. If that instance goes down, all locks are lost. Martin Kleppmann (author of Designing Data-Intensive Applications) published a thorough analysis arguing that even Redlock — Redis's multi-node locking algorithm that acquires locks on N/2+1 nodes — isn't safe under clock skew or network partitions.
Antirez (Redis creator) disagreed, arguing the failure scenarios are unlikely in practice.
The practical takeaway:
| Lock Type | Use When |
|---|---|
| Single Redis lock | Short-lived locks, best-effort coordination. If the lock fails, the worst case is duplicate work (not data corruption). |
| ZooKeeper / etcd | Leader election, critical coordination where incorrect behavior causes data loss or financial impact. |
The Practical Reality
Most companies use Redis locks for things like rate limiting, deduplication, and preventing duplicate cron jobs. These are cases where the worst outcome of a failed lock is doing the same work twice — annoying but not catastrophic. For critical coordination (leader election, distributed consensus), use a system designed for it: ZooKeeper, etcd, or a database with proper serializable transactions.
ZooKeeper: Sequential Ephemeral Nodes
ZooKeeper provides a stronger locking primitive using sequential ephemeral nodes. The protocol gives you two properties Redis can't guarantee:
- Ephemeral: if the lock holder's session times out (process crashes, network partition), ZooKeeper automatically deletes the node. No TTL guessing required.
- Sequential: nodes are assigned monotonically increasing sequence numbers, enabling fair FIFO ordering.
The Locking Recipe
Step 1: Client creates an ephemeral sequential node
/locks/order-123/lock-0000000001
Step 2: Client lists all children of /locks/order-123/
→ [lock-0000000001, lock-0000000002, lock-0000000003]
Step 3: If my node has the LOWEST sequence number → I hold the lock
If not → watch the node with the next-lower sequence number
Step 4: When the watched node is deleted (holder releases or crashes)
→ re-check if I'm now the lowest → if yes, I hold the lock
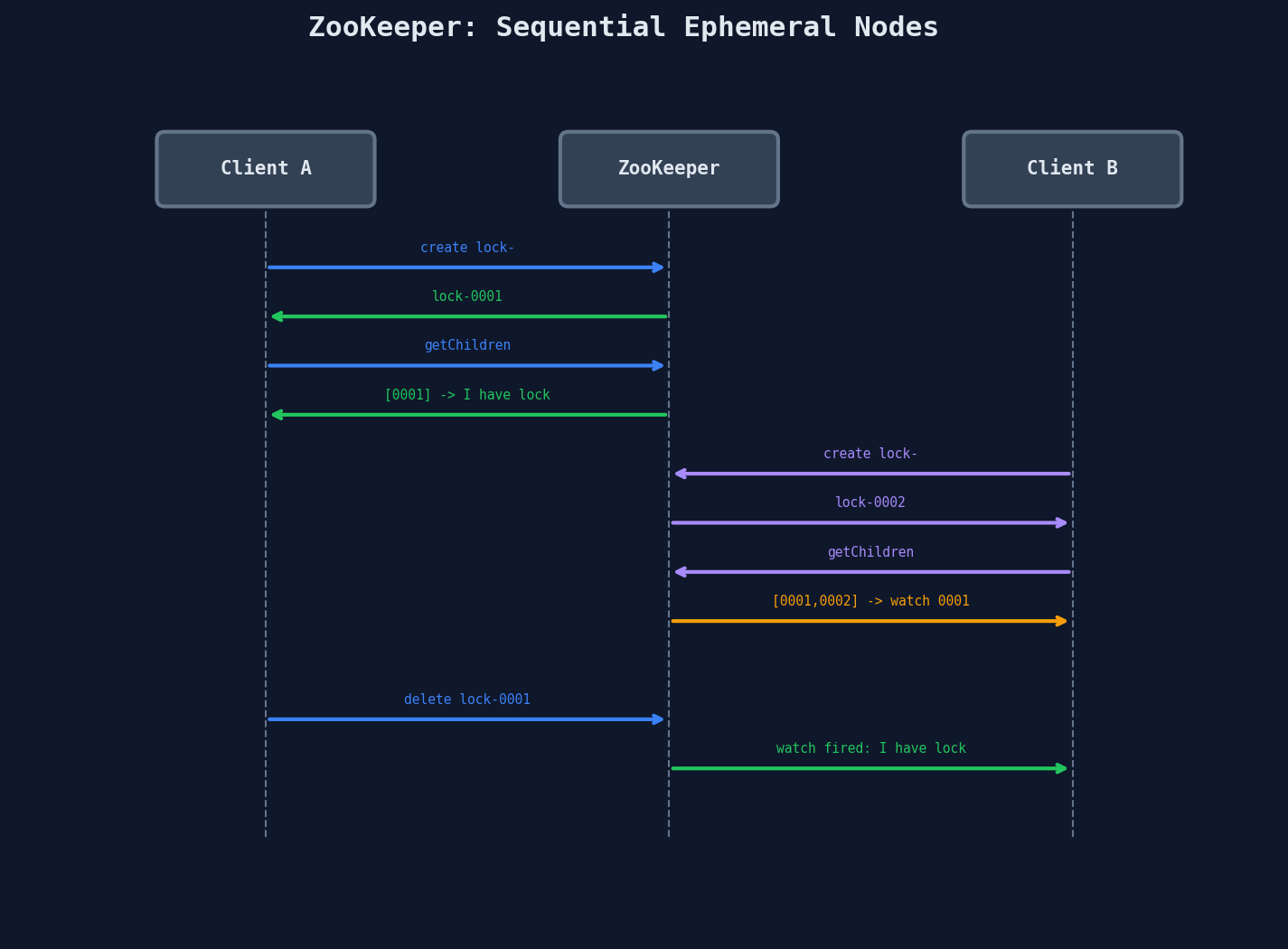
Each client only watches the node immediately before it (not all nodes). This prevents the herd effect — when the lock is released, only the next client in line wakes up, not all waiting clients.
Why Ephemeral Nodes Beat TTLs
With Redis, you guess a TTL: "30 seconds should be enough." If the operation takes 35 seconds, the lock expires and another client grabs it. You're back to a race condition.
With ZooKeeper, the lock lives as long as the client's session. The session stays alive via heartbeats. If the client crashes (no more heartbeats), ZooKeeper detects the session timeout and deletes the ephemeral node automatically. No guessing required.
| Problem | Redis TTL | ZooKeeper Ephemeral |
|---|---|---|
| Operation takes longer than expected | Lock expires prematurely. Another client enters the critical section. | Lock persists. Session heartbeats keep it alive. |
| Client crashes | Lock expires after TTL. Could be seconds of unprotected time. | Lock deleted on session timeout. ZooKeeper detects quickly. |
| Clock skew | TTL may expire early on some nodes. Redlock safety is debated. | ZooKeeper uses its own session tracking. No dependence on wall clocks. |
Fencing Tokens
Even with distributed locks, there's a fundamental problem: a lock holder can be delayed by a GC pause, network timeout, or page fault, and by the time it executes its write, the lock has already been given to someone else.
A fencing token is a monotonically increasing number issued each time a lock is acquired. The protected resource (database, storage service) checks the token on every write and rejects any write with a token lower than the last one it accepted.
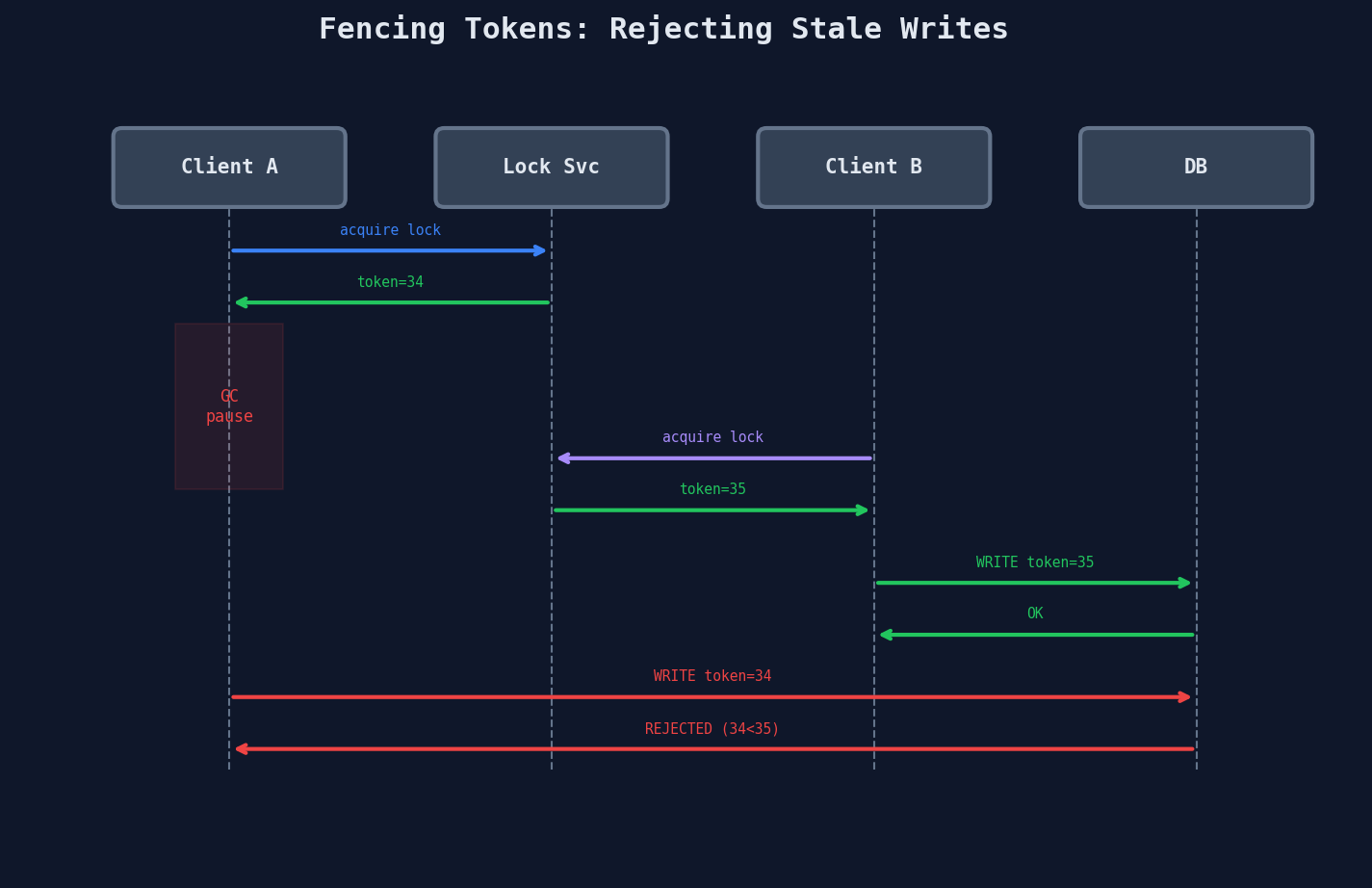
The key insight: the lock service alone can't prevent stale writes, because it can't control when a client actually executes its write. The resource itself must enforce ordering using the fencing token. This pushes the safety guarantee to the last line of defense — the storage layer.
Fencing Requires Resource Cooperation
Fencing tokens only work if the resource (database, API, storage) checks the token on every write. If you're writing to a third-party service that doesn't support fencing, you can't use this pattern. In that case, you need to serialize access through a queue instead.
Implementation Sketch
-- Add a fencing column to the protected table
ALTER TABLE orders ADD COLUMN last_fence_token BIGINT DEFAULT 0;
-- Every write includes the fencing token
UPDATE orders
SET status = 'confirmed', last_fence_token = 35
WHERE order_id = 'order-123'
AND last_fence_token < 35;
-- If another client already wrote with token 35 or higher,
-- this UPDATE matches 0 rows → the stale write is rejected.
Queue-Based Serialization
Sometimes the cleanest solution is to avoid locks entirely. Instead of coordinating who can access a resource, route all updates for that resource through a single ordered queue.
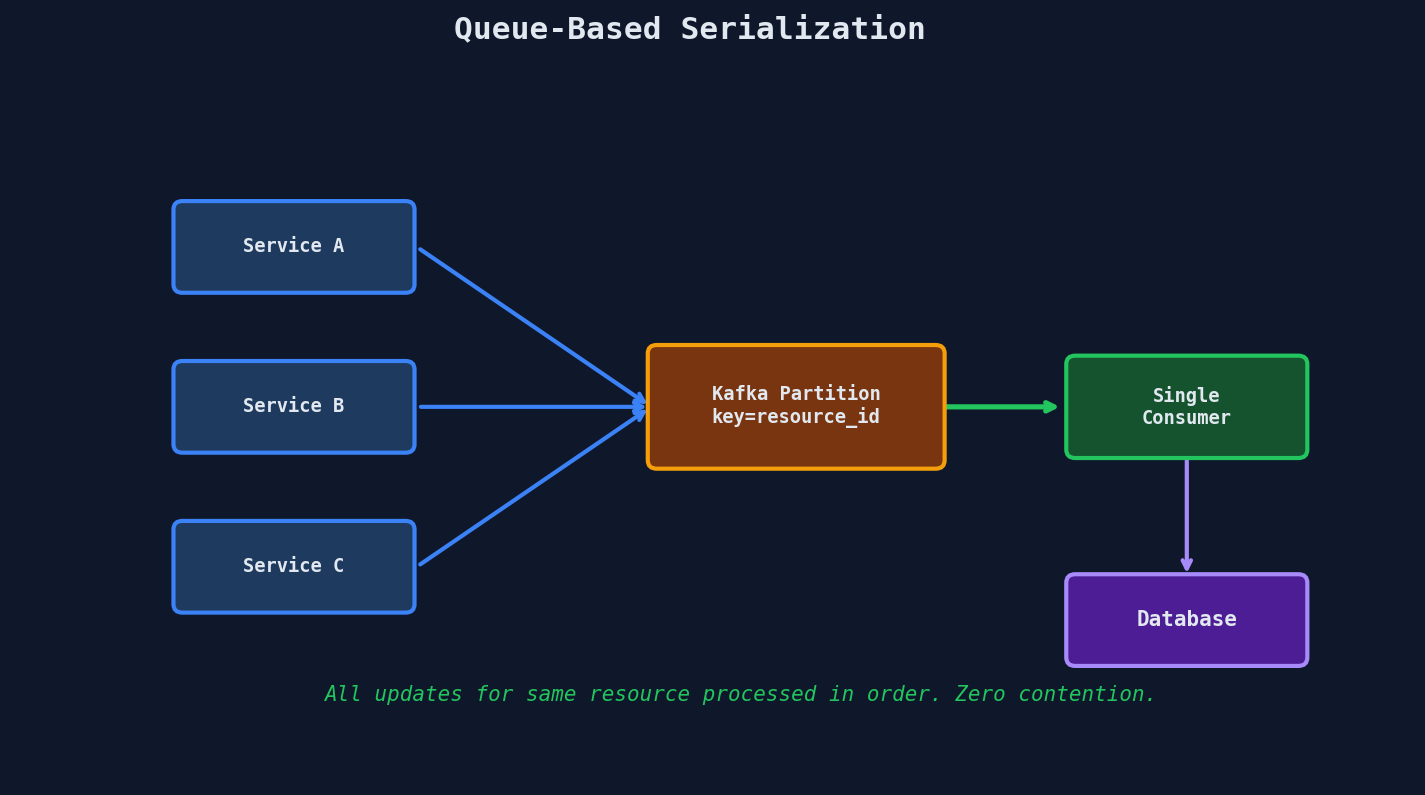
How It Works
Kafka guarantees ordering within a single partition. If you use the resource ID as the partition key, all updates for the same resource land in the same partition and are processed by the same consumer, in order.
from kafka import KafkaProducer
import json
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
key_serializer=lambda k: k.encode('utf-8')
)
def submit_inventory_update(product_id: str, quantity_change: int):
"""
All updates for the same product_id go to the same Kafka partition.
Single consumer processes them in order. Zero lock contention.
"""
event = {
"product_id": product_id,
"quantity_change": quantity_change,
"timestamp": time.time()
}
# partition_key = product_id → same partition → ordered processing
producer.send(
topic="inventory-updates",
key=product_id,
value=event
)
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
'inventory-updates',
bootstrap_servers=['localhost:9092'],
group_id='inventory-processor',
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
def process_updates():
"""
Single consumer per partition. No locks needed.
Events for the same product arrive in order.
"""
for message in consumer:
event = message.value
product_id = event["product_id"]
quantity_change = event["quantity_change"]
# This runs single-threaded for each product_id.
# No race conditions. No locks. Just sequential processing.
current = db.get_inventory(product_id)
new_quantity = current + quantity_change
if new_quantity < 0:
publish_event("inventory-insufficient", event)
continue
db.update_inventory(product_id, new_quantity)
publish_event("inventory-updated", event)
The Trade-Off
Queue serialization eliminates contention entirely, but it introduces latency and limits throughput:
| Aspect | Lock-Based | Queue-Based |
|---|---|---|
| Latency | Immediate (if lock is free) | Queued — depends on consumer lag |
| Throughput per resource | Limited by lock contention | Limited by single consumer speed |
| Total throughput | Scales with more DB connections | Scales with more partitions (different resources in parallel) |
| Complexity | Lock management, deadlock risk | Consumer group management, exactly-once semantics |
| Failure mode | Deadlock, stale locks | Consumer lag, reprocessing on crash |
When to Use Queues
Queue serialization works best when updates don't need immediate confirmation. Inventory systems, analytics pipelines, event sourcing — these can tolerate milliseconds of queue delay. Payment authorization, where the user is waiting on screen for a result, usually needs synchronous lock-based coordination.
Decision Table
| Approach | Best For | Avoid When |
|---|---|---|
| Redis lock | Short-lived coordination (< 30s), deduplication, rate limiting. Worst case if lock fails = duplicate work. | Financial transactions, leader election, anything where incorrect behavior causes data loss. |
| ZooKeeper / etcd | Leader election, config coordination, critical mutual exclusion. Strong consistency guarantees. | Simple deduplication or rate limiting (overkill). High-throughput hot paths (ZK has lower throughput than Redis). |
| Fencing tokens | Any lock-based system where a stale holder might write after losing the lock. Layer on top of Redis or ZK. | Resources that don't support token checking (third-party APIs). |
| Queue serialization | High-throughput ordered processing where latency is acceptable. Eliminates contention entirely. | Low-latency synchronous operations where the user waits for immediate confirmation. |
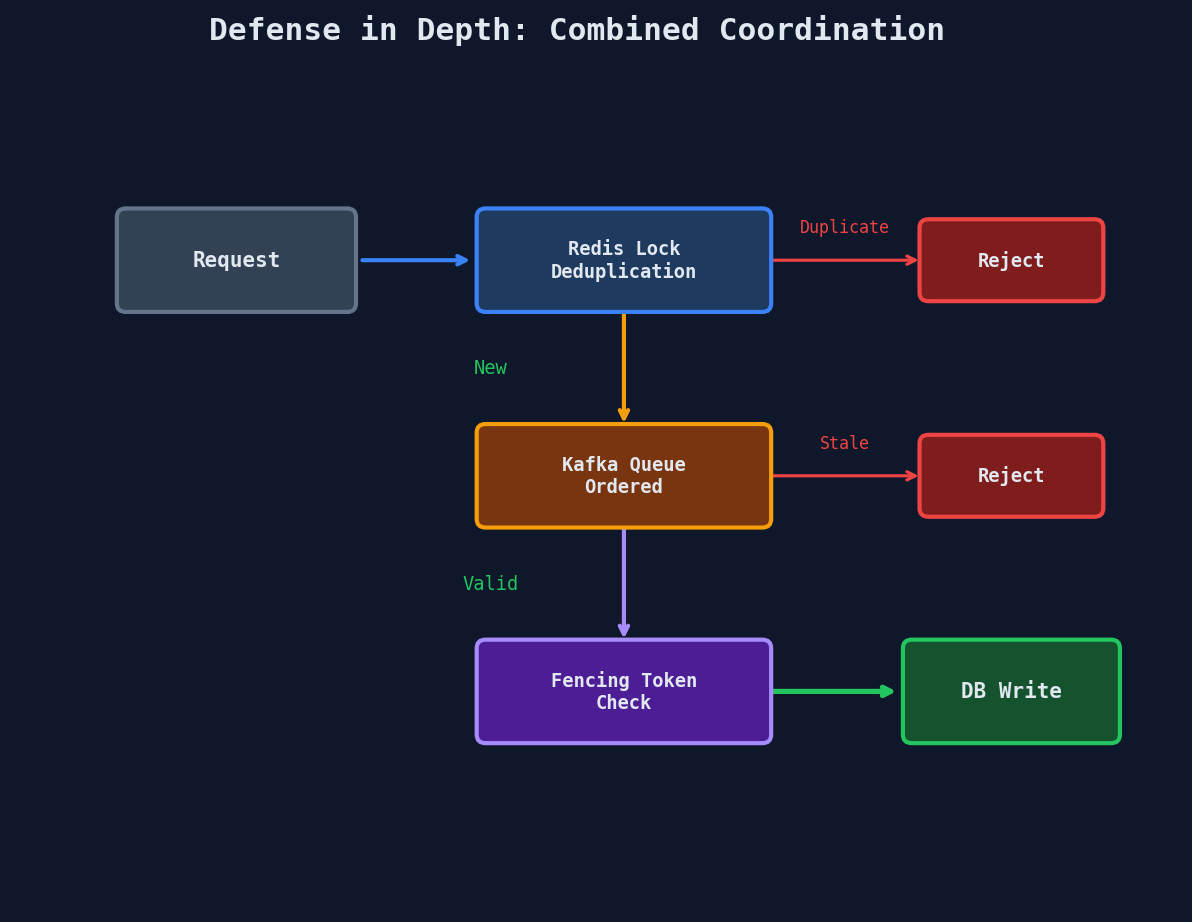
Combining Approaches
In practice, production systems combine these. A common pattern:
- Redis lock for deduplication — prevent duplicate order submissions
- Kafka queue for processing — serialize all inventory updates per product
- Fencing token on the database — reject stale writes that slip through
Each layer catches failures the previous layer might miss. Defense in depth.
Quick Recap
| Concept | Key Takeaway |
|---|---|
| Single-DB locks | Only work when all transactions go through the same database |
| Redis SETNX | Fast distributed lock. Use unique token + Lua script for safe release. Not safe under network partitions. |
| Redlock | Multi-node Redis locking. Debated safety. Fine for best-effort, not for critical coordination. |
| ZooKeeper | Sequential ephemeral nodes. Fair ordering, crash-safe (no TTL guessing). Use for leader election and critical locks. |
| Fencing tokens | Monotonically increasing token. Resource rejects writes with token < last seen. Safety at the storage layer. |
| Queue serialization | Route updates through Kafka partition by resource ID. Zero contention. Trade-off: added latency. |
Interview Tip
Distributed locks are a last resort. If you can redesign to avoid shared state — partition the data so each service owns its own slice, use CRDTs for eventually consistent merges, or serialize through a queue — do that first. When the interviewer describes cross-service coordination, start with "Can we avoid shared state?" before reaching for a lock. It shows architectural maturity.