Async, Caching, and Concurrency
TL;DR
Not every API call completes instantly. Long-running operations use 202 Accepted with a status polling endpoint. ETags enable optimistic concurrency (preventing lost updates) and HTTP caching (avoiding redundant downloads). These are production-critical patterns that separate toy APIs from real ones.
Asynchronous Operations
The Problem: Long-Running Requests
Some operations take seconds, minutes, or even hours to complete. Think about:
- Video processing: User uploads a video, server needs to transcode it into multiple resolutions
- Report generation: User requests a CSV export of 10 million records
- Bulk operations: Admin triggers a mass email to 500,000 users
- Payment processing: Credit card charge needs to go through fraud detection, bank approval, and settlement
If you make the client wait synchronously, the HTTP connection will time out, the user will think it's broken, and they'll retry — potentially triggering the operation twice.
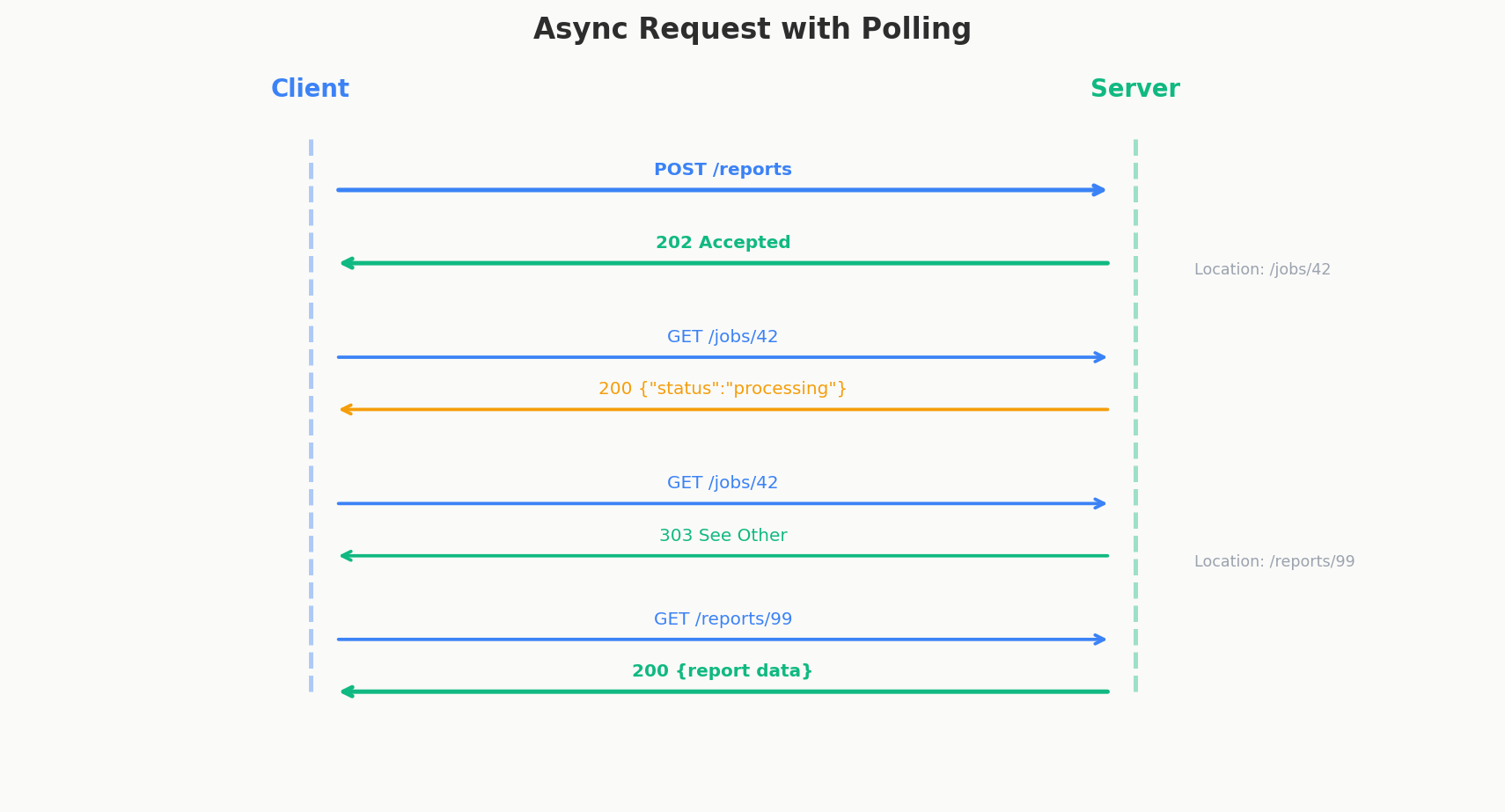
The Pattern: 202 Accepted + Status Polling
The solution is a two-step dance:
Step 1: Accept the request and return immediately
POST /reports
{
"type": "sales_summary",
"date_range": { "from": "2024-01-01", "to": "2024-12-31" }
}
HTTP/1.1 202 Accepted
Location: /jobs/report-abc123
Content-Type: application/json
{
"job_id": "report-abc123",
"status": "accepted",
"status_url": "/jobs/report-abc123",
"estimated_completion": "2024-03-15T14:35:00Z"
}
Key elements: - 202 Accepted — not 200 OK or 201 Created. The request was accepted for processing, not completed. - Location header — points to a status endpoint the client can poll. - Estimated completion — optional but helpful for UX (progress bars, "check back in 5 minutes").
Step 2: Client polls the status endpoint
While in progress:
HTTP/1.1 200 OK
{
"job_id": "report-abc123",
"status": "processing",
"progress": 65,
"started_at": "2024-03-15T14:30:00Z"
}
When complete:
HTTP/1.1 303 See Other
Location: /reports/final-xyz789
{
"job_id": "report-abc123",
"status": "completed",
"result_url": "/reports/final-xyz789"
}
The 303 See Other with a Location header redirects the client to the actual result. Alternatively, some APIs return 200 with the result embedded directly.
If the operation fails:
HTTP/1.1 200 OK
{
"job_id": "report-abc123",
"status": "failed",
"error": {
"code": "DATA_TOO_LARGE",
"message": "Report exceeds maximum size. Try narrowing the date range.",
"retryable": true
}
}
Alternatives to Polling
Polling works but wastes requests. Better options exist:
| Approach | How It Works | Best For |
|---|---|---|
| Polling | Client periodically calls GET on status URL | Simple, works everywhere |
| Webhooks | Server calls a client-provided URL when done | Server-to-server, Twilio/Stripe style |
| WebSockets | Server pushes status updates over persistent connection | Real-time UIs, progress bars |
| SSE | Server streams status updates over HTTP | Browser-friendly progress updates |
Interview Tip
Mentioning the 202 + polling pattern for operations like "generate a report" or "process a video upload" shows you've built production systems. Most candidates only think in synchronous request-response.
Real-World Example: AWS S3 Multipart Upload
AWS S3's multipart upload is a great example of async API design:
POST /uploads→ initiates upload, returnsupload_idPUT /uploads/{upload_id}/parts/{part_number}→ upload each chunkPOST /uploads/{upload_id}/complete→ finalize the upload- Server processes and assembles parts asynchronously
Each step is its own API call, the client can retry individual parts, and the overall operation is resilient to network failures.
ETags and Optimistic Concurrency
The Problem: Lost Updates
Imagine two editors working on the same document through an API:
- Alice:
GET /documents/1→ sees version with "Hello" - Bob:
GET /documents/1→ sees version with "Hello" - Alice:
PUT /documents/1→ changes to "Hello World" - Bob:
PUT /documents/1→ changes to "Hello Bob"
Bob's update overwrites Alice's change without knowing it existed. This is the lost update problem.
The Solution: ETags (Entity Tags)
An ETag is an opaque string that represents a specific version of a resource. Think of it as a fingerprint — it changes whenever the resource changes.
GET /documents/1
HTTP/1.1 200 OK
ETag: "a1b2c3d4"
Content-Type: application/json
{
"id": 1,
"title": "My Document",
"content": "Hello"
}
The ETag "a1b2c3d4" is typically a hash of the resource content or a version number. The client caches this ETag.
Optimistic Concurrency with If-Match
When updating, the client sends the ETag it received using the If-Match header:
PUT /documents/1
If-Match: "a1b2c3d4"
Content-Type: application/json
{
"title": "My Document",
"content": "Hello World"
}
The server checks: does the current ETag match "a1b2c3d4"?
If yes — the resource hasn't changed since the client last read it. Safe to update.
If no — someone else modified it. Return 412 Precondition Failed.
HTTP/1.1 412 Precondition Failed
Content-Type: application/json
{
"error": {
"code": "CONFLICT",
"message": "The resource was modified by another client. Please re-fetch and retry.",
"current_etag": "x9y0z1a2"
}
}
Now the client knows it has stale data. It can re-fetch, show the user the conflict, and retry.
Why "Optimistic"?
It's called optimistic concurrency because it assumes conflicts are rare. Instead of locking the resource before editing (pessimistic), it lets everyone read and write freely, then detects conflicts at write time.
This is perfect for APIs because: - No locks — no risk of deadlocks or forgotten locks - High throughput — reads are never blocked - Stateless — the server doesn't track who's editing what - Conflict detection — you find out immediately if something went wrong
ETag Types
| Type | How It's Generated | Use Case |
|---|---|---|
| Strong ETag | Hash of entire resource content ("a1b2c3") |
Byte-for-byte identity, safe for Range requests |
| Weak ETag | Semantic version (W/"v42") |
Equivalent content, may differ in formatting |
Most APIs use strong ETags for simplicity.
HTTP Caching
The Problem: Redundant Data Transfer
A mobile app showing event details might call GET /events/123 every time the user opens the screen. If the event hasn't changed, the server is doing work and sending bytes for nothing.
Cache-Control Headers
The server tells clients how to cache responses using the Cache-Control header:
GET /events/123
HTTP/1.1 200 OK
Cache-Control: max-age=600, private
Content-Type: application/json
ETag: "abc123"
{ "id": 123, "name": "Taylor Swift Concert", ... }
| Directive | Meaning |
|---|---|
max-age=600 |
Cache this response for 600 seconds (10 minutes) |
private |
Only the requesting client can cache it (not CDNs/proxies) |
public |
CDNs and proxies can cache it too |
no-store |
Never cache this response at all |
no-cache |
You can cache it, but must revalidate with the server before using it |
Common Gotcha
no-cache does NOT mean "don't cache." It means "always check with the server first." Use no-store if you truly want no caching (e.g., for sensitive data).
Conditional Requests with If-None-Match
After the cached response expires, the client can check if the resource actually changed using the ETag:
If the resource hasn't changed:
No response body — the client uses its cached copy. This saves bandwidth and server processing time.
If the resource has changed:
HTTP/1.1 200 OK
ETag: "def456"
Cache-Control: max-age=600, private
{ "id": 123, "name": "Taylor Swift Concert - SOLD OUT", ... }
New data with a new ETag.
Caching Strategy by Resource Type
| Resource Type | Cache Strategy | Why |
|---|---|---|
| Static assets (images, CSS) | public, max-age=31536000 |
Rarely change, safe to cache aggressively |
| User-specific data | private, max-age=300 |
Only for this user, moderate freshness |
| Real-time data (stock prices) | no-store |
Stale data is dangerous |
| Event listings | public, max-age=60 |
Changes sometimes, CDN-cacheable |
| Auth tokens | no-store |
Never cache sensitive credentials |
Interview Tip
Mentioning Cache-Control headers and ETags shows you think about performance at the HTTP layer, not just application logic. This is especially relevant for CDN-heavy architectures.
Content Negotiation
When clients and servers need to agree on data format, they use content negotiation headers.
How It Works
The client says what it can accept:
The q value (0-1) indicates preference. JSON is preferred (q=1.0 by default), XML is acceptable (q=0.9).
The server responds in the best matching format:
When Negotiation Fails
| Status Code | Meaning |
|---|---|
| 406 Not Acceptable | Server can't produce any format the client accepts |
| 415 Unsupported Media Type | Server doesn't understand the format the client sent |
POST /events
Content-Type: application/xml ← Server only accepts JSON
HTTP/1.1 415 Unsupported Media Type
{
"error": "This API only accepts application/json"
}
In Practice
Most modern APIs only support JSON, making content negotiation less relevant than it once was. But it still matters for:
- APIs that support both JSON and XML (enterprise/government systems)
- APIs that serve different representations (HTML for browsers, JSON for APIs)
- Binary resources (images in different formats: JPEG, PNG, WebP)
JSON Patch vs JSON Merge Patch
When we talked about PATCH in Chapter 2, we said it does "partial updates." But how does the client describe those partial updates? There are two standard formats.
JSON Merge Patch (RFC 7396)
The simpler approach. Send a JSON object with only the fields you want to change:
PATCH /users/123
Content-Type: application/merge-patch+json
{
"email": "new@example.com",
"phone": null
}
This sets email to the new value and deletes phone (null = remove). Fields not included are unchanged.
Limitation: You can't set a field to null without deleting it, because null means "remove." If your data model uses null values meaningfully, merge patch won't work.
JSON Patch (RFC 6902)
The more powerful approach. Send an array of operations:
PATCH /users/123
Content-Type: application/json-patch+json
[
{ "op": "replace", "path": "/email", "value": "new@example.com" },
{ "op": "remove", "path": "/phone" },
{ "op": "add", "path": "/addresses/1", "value": { "city": "NYC" } },
{ "op": "test", "path": "/version", "value": 5 }
]
Operations: add, remove, replace, move, copy, test.
The test operation is especially useful — it checks a precondition before applying changes, similar to optimistic concurrency.
Which to Use?
| Format | Simplicity | Power | Null Handling | Use When |
|---|---|---|---|---|
| Merge Patch | Very simple | Limited | null = delete | Simple field updates |
| JSON Patch | More complex | Full | Explicit operations | Complex mutations, arrays, conditions |
For interviews, merge patch is usually sufficient. Mention JSON Patch if the interviewer asks about complex partial updates or array manipulation.
Don't Mirror Your Database
This is a principle from Microsoft's API design guide that's worth calling out explicitly.
The anti-pattern:
# Database tables: users, user_addresses, user_preferences
GET /users
GET /user_addresses?user_id=123
GET /user_preferences?user_id=123
Why it's wrong: Your API is a leaky abstraction of your database schema. If you rename a table or split it, every client breaks. You're also exposing internal structure that attackers can exploit.
The fix: Design the API around business entities, not database tables:
GET /users/123
{
"id": 123,
"name": "Jane Doe",
"address": { "city": "NYC", "zip": "10001" },
"preferences": { "theme": "dark", "notifications": true }
}
The API is an abstraction layer between clients and your database. You're free to change your storage implementation without breaking the API contract.
OpenAPI / Swagger
In production, APIs are documented using the OpenAPI Specification (formerly Swagger). It's a machine-readable YAML/JSON file that describes your entire API:
openapi: 3.0.0
info:
title: Ticketmaster API
version: 1.0.0
paths:
/events:
get:
summary: List events
parameters:
- name: city
in: query
schema:
type: string
responses:
'200':
description: List of events
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/Event'
Why it matters: - Auto-generated documentation — tools like Swagger UI create interactive docs from the spec - Client SDK generation — generate TypeScript, Python, Java clients automatically - Contract-first development — teams agree on the API spec before writing code - Testing — validate requests/responses against the spec
You don't need to write OpenAPI specs in interviews, but mentioning it shows you know how APIs are documented and maintained in real organizations.
Interview Tip
If asked "how would you document this API?", saying "I'd define an OpenAPI spec that teams can use to auto-generate client SDKs and interactive documentation" is a strong answer.
Key Takeaways
| Pattern | When to Use | Status Code |
|---|---|---|
| Async operations | Video processing, report generation, bulk tasks | 202 Accepted → poll → 303 See Other |
| Optimistic concurrency | Collaborative editing, preventing lost updates | If-Match → 412 Precondition Failed |
| HTTP caching | Reducing redundant data transfer | Cache-Control → If-None-Match → 304 Not Modified |
| Content negotiation | Supporting multiple response formats | Accept header → 406 / 415 |
| JSON Patch | Complex partial updates | PATCH with application/json-patch+json |
| OpenAPI | API documentation and contracts | N/A — it's a spec, not a runtime pattern |
Interview Expectations: Junior vs. Senior
- Junior/Mid-level: Designs synchronous APIs entirely. Mentions caching via Redis but might not explain cache-control headers (ETag, max-age).
- Senior/Staff: Proactively makes heavy/slow operations asynchronous (HTTP 202 Accepted + Polling/Webhooks). Uses Optimistic Concurrency Control (ETags) or Pessimistic Locking to handle write conflicts. Discusses CDN caching strategies for read-heavy public APIs.