Iterative DFS with State
The Final Connection
You've used recursion for every tree algorithm in this course. The call stack handled everything: visiting children, storing intermediate results, combining answers. But recursion has limits — deep trees can overflow the stack, and some environments restrict recursion depth.
This lesson shows you how to do everything recursion does, but with an explicit stack. Not the basic iterative traversal you might have seen (push right, push left, pop, print). That only handles traversal. We need to handle computation — specifically, postorder computation where you aggregate children's results.
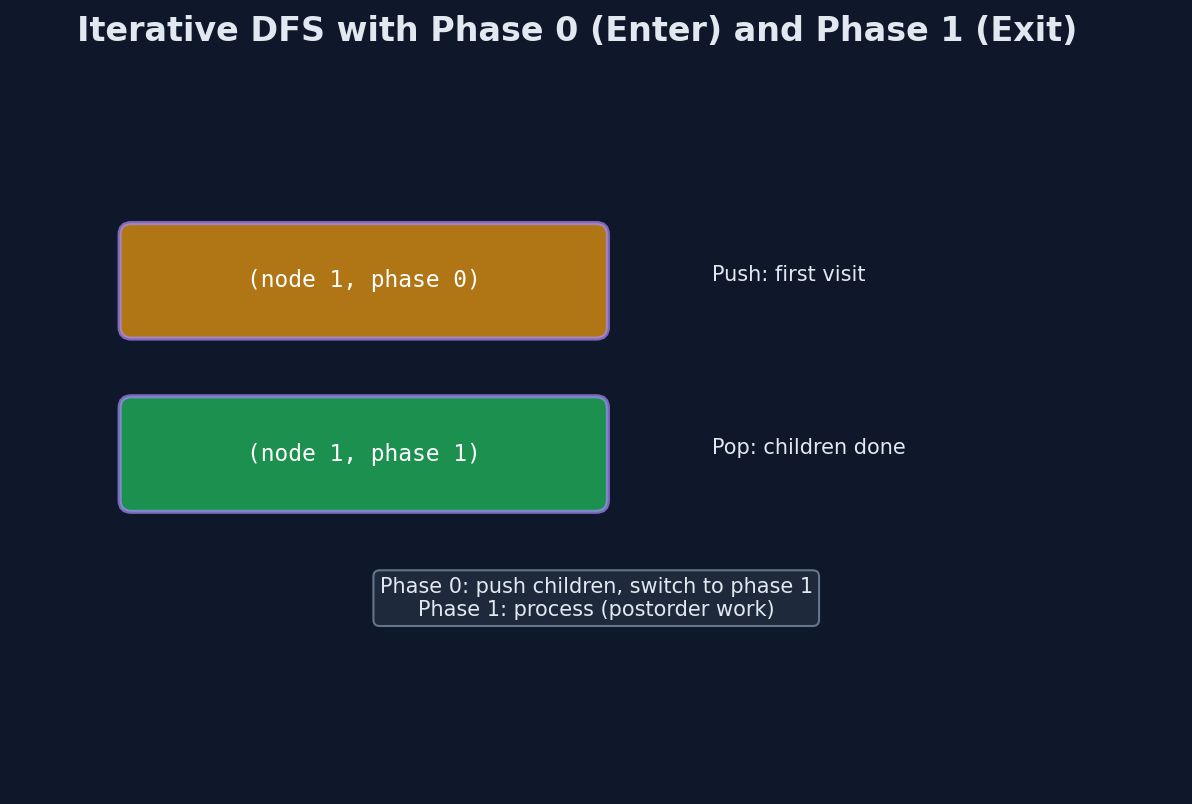
The technique: push (node, phase) pairs onto the stack. Phase 0 means "going down" (schedule children). Phase 1 means "coming back up" (aggregate results).
The Phase Trick
In recursive postorder, the function does two things at different times:
- Before processing children: push children onto the call stack.
- After children return: combine their results.
The call stack handles this automatically — when a child returns, execution resumes in the parent's function body after the recursive call.
With an explicit stack, you need to simulate this. The trick: push the same node twice. First with phase 1 (the "coming back" work), then push the children with phase 0. Since a stack is LIFO, the children are processed first, and by the time you reach the phase-1 entry, the children's results are already in the hashmap.
Push (node, 1) ← will be processed LAST (after children)
Push (right_child, 0) ← will be processed second
Push (left_child, 0) ← will be processed FIRST
Example: Subtree Sums
Compute the sum of all values in every subtree. The recursive version is trivial:
int solve(TreeNode* root) {
if (!root) return 0;
return root->val + solve(root->left) + solve(root->right);
}
Now do it iteratively.
We need: result[4] = 4, result[5] = 5, result[2] = 11, result[3] = 3, result[1] = 15.
Full Trace
Stack is shown top-to-bottom. We also maintain a result hashmap.
| Step | Stack (top first) | Action | result map |
|---|---|---|---|
| 0 | (1, 0) | Pop (1, 0). Push (1, 1), (3, 0), (2, 0). | {} |
| 1 | (2, 0), (3, 0), (1, 1) | Pop (2, 0). Push (2, 1), (5, 0), (4, 0). | {} |
| 2 | (4, 0), (5, 0), (2, 1), (3, 0), (1, 1) | Pop (4, 0). Push (4, 1), (null, 0), (null, 0). | {} |
| 3 | (null, 0), (null, 0), (4, 1), (5, 0), ... | Pop (null, 0). Skip. | {} |
| 4 | (null, 0), (4, 1), (5, 0), ... | Pop (null, 0). Skip. | {} |
| 5 | (4, 1), (5, 0), (2, 1), (3, 0), (1, 1) | Pop (4, 1). Left=0, right=0. result[4] = 4+0+0 = 4. | {4: 4} |
| 6 | (5, 0), (2, 1), (3, 0), (1, 1) | Pop (5, 0). Push (5, 1), (null, 0), (null, 0). | {4: 4} |
| 7-8 | Pop two nulls. Skip. | — | {4: 4} |
| 9 | (5, 1), (2, 1), (3, 0), (1, 1) | Pop (5, 1). result[5] = 5+0+0 = 5. | {4: 4, 5: 5} |
| 10 | (2, 1), (3, 0), (1, 1) | Pop (2, 1). Left=result[4]=4, right=result[5]=5. result[2] = 2+4+5 = 11. | {4:4, 5:5, 2:11} |
| 11 | (3, 0), (1, 1) | Pop (3, 0). Push (3, 1), (null, 0), (null, 0). | {4:4, 5:5, 2:11} |
| 12-13 | Pop two nulls. Skip. | — | {4:4, 5:5, 2:11} |
| 14 | (3, 1), (1, 1) | Pop (3, 1). result[3] = 3+0+0 = 3. | {4:4, 5:5, 2:11, 3:3} |
| 15 | (1, 1) | Pop (1, 1). Left=result[2]=11, right=result[3]=3. result[1] = 1+11+3 = 15. | {4:4, 5:5, 2:11, 3:3, 1:15} |
Stack empty. Done.
Verify: result[1] = 15 = 1+2+3+4+5. Correct.
Phase 0 = "I need to go deeper." Phase 1 = "My children are done, time to combine." The hashmap stores intermediate results that the recursive version kept on the call stack.
The Code
unordered_map<TreeNode*, int> subtreeSumsIterative(TreeNode* root) {
unordered_map<TreeNode*, int> result;
if (!root) return result;
stack<pair<TreeNode*, int>> stk;
stk.push({root, 0});
while (!stk.empty()) {
auto [node, phase] = stk.top();
stk.pop();
if (!node) continue;
if (phase == 0) {
stk.push({node, 1});
stk.push({node->right, 0});
stk.push({node->left, 0});
} else {
int leftSum = node->left ? result[node->left] : 0;
int rightSum = node->right ? result[node->right] : 0;
result[node] = node->val + leftSum + rightSum;
}
}
return result;
}
Complexity: \(O(n)\) time, \(O(n)\) space (stack + hashmap).
Recursive vs Iterative: What You Gain and Lose
| Recursive | Iterative (phase trick) | |
|---|---|---|
| Readability | Clear and natural | Harder to follow |
| Stack depth | Limited by call stack (often ~10K) | Limited by heap memory (millions) |
| State management | Automatic (local variables) | Manual (hashmap) |
| Speed | Slightly faster (no hashmap overhead) | Slightly slower |
| When to use | Almost always | Deep trees, stack overflow risk |
For interviews, recursive is almost always preferred — it's cleaner and interviewers expect it. The iterative version exists for two situations:
- The tree can be very deep (e.g., a linked-list-shaped tree with \(10^5\) nodes).
- You need to understand what recursion actually does — and the iterative version forces you to see every detail the call stack was hiding.
The Deeper Point
Every recursive algorithm can be made iterative by managing your own stack. This isn't just a tree fact — it's a computer science fact. The call stack IS a stack. Recursion IS stack operations with syntactic sugar.
When you write the iterative version, you see the raw mechanics: - Phase 0 = the function call (entering) - Phase 1 = the return (exiting) - The hashmap = the return values that recursion passes back automatically
If you can convert a recursive tree algorithm to an iterative one with a stack, you truly understand what the recursion is doing. The stack isn't simulating recursion — recursion was always a stack.
Try It
Predict before running: How many times does each node appear on the stack? Exactly twice — once with phase 0, once with phase 1. So the total number of push/pop operations is \(2n\) (plus nulls).
Challenge: Convert the balanced-tree check (Ch3) to iterative. Each phase-1 step needs to check if \(|\text{leftHeight} - \text{rightHeight}| > 1\) and propagate \(-1\) if so. Store heights in the hashmap.
Challenge 2: Convert House Robber III (Ch8 L1) to iterative. Store pairs (skip, take) in the hashmap. The phase-1 step reads children's pairs and computes the current node's pair.
Edge Cases to Watch For
- All null children: Every phase-0 push of a null is immediately skipped; verify the
continueguard works correctly. If null children are not filtered, the phase-1 handler will attempt to read results for nonexistent nodes. - Negative node values: Subtree sums can be negative; if your phase-1 aggregation uses unsigned types or assumes non-negative intermediates, results will be wrong.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| LC 145 — Binary Tree Postorder Traversal | leetcode.com/problems/binary-tree-postorder-traversal | Easy |
| LC 590 — N-ary Tree Postorder Traversal | leetcode.com/problems/n-ary-tree-postorder-traversal | Easy |
| LC 889 — Construct Binary Tree from Preorder and Postorder | leetcode.com/problems/construct-binary-tree-from-preorder-and-postorder-traversal | Medium |
| LC 1130 — Min Cost Tree From Leaf Values | leetcode.com/problems/minimum-cost-tree-from-leaf-values | Medium |
| LC 394 — Decode String | leetcode.com/problems/decode-string | Medium |
What's Next?
You now fully understand the stack-tree duality. The next leap: what if you could flatten the entire tree into an array, turning subtree queries into range queries? Chapter 11 teaches tree linearization -- the bridge from trees to segment trees.