2D Monotonic Queue
Chapter 3 extended the 1D histogram to 2D matrices. Now let's extend the 1D sliding window to 2D: find the maximum (or minimum) in every K x K subgrid of an N x M matrix.
The Naive Approach
There are (N - K + 1) * (M - K + 1) subgrids. For each one, scan all K * K elements to find the max. That's O(N * M * K^2). For a 1000 x 1000 matrix with K = 100, you're looking at 10^10 operations. Not happening.
You might try to be clever with prefix maximums or sparse tables, but they don't compose well in 2D for sliding windows. The right approach is simpler than you'd expect.
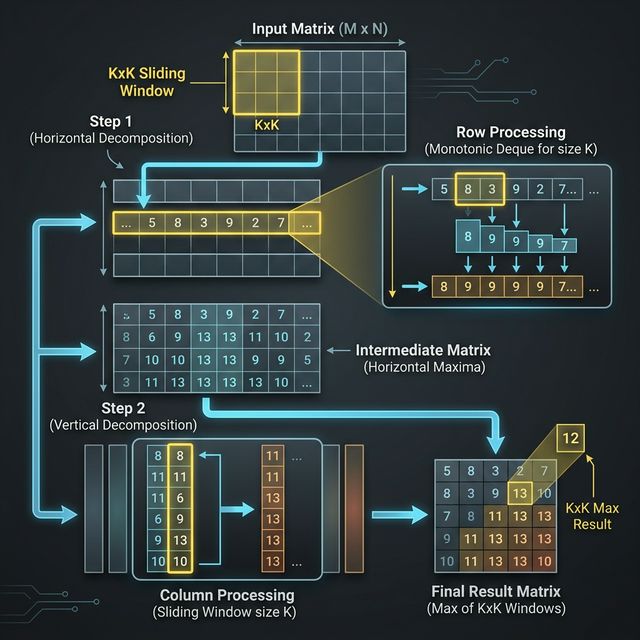
The Two-Pass Decomposition
The trick: decompose the 2D problem into two 1D problems. You already know how to compute the sliding window max in 1D from Chapter 2. Do it twice:
Pass 1 — Horizontal. For each row, run the 1D sliding window max of size K across columns. This produces an intermediate matrix hmax of size N x (M - K + 1). Each cell hmax[i][j] stores the maximum of K consecutive elements in row i, starting at column j:
Pass 2 — Vertical. For each column of hmax, run the 1D sliding window max of size K down the rows. This produces the final answer matrix of size (N - K + 1) x (M - K + 1). Each cell stores the maximum of K consecutive values in the intermediate matrix, going downward:
That's it. Two passes of 1D sliding window max. No new data structures. No new ideas. Just composition.
Why This Works
Expand what answer[r][c] actually computes:
answer[r][c] = max over i in [r, r+K-1] of hmax[i][c]
= max over i in [r, r+K-1] of (max over j in [c, c+K-1] of grid[i][j])
= max over i in [r, r+K-1], j in [c, c+K-1] of grid[i][j]
That last line is exactly the maximum of the K x K subgrid with top-left corner at (r, c). The horizontal pass compressed each row by taking maximums over K-wide windows. The vertical pass then took maximums over K-tall windows of the already-compressed values. The two passes compose into the full K x K window.
This is the same idea behind 2D prefix sums: compute row-wise prefix sums, then column-wise prefix sums of the result. Separable operations decompose cleanly across dimensions.
Concrete Example
Let's trace through a 5 x 6 matrix with K = 3.
Original matrix:
After horizontal pass (sliding max of size 3 across each row, producing 5 x 4):
8 8 5 7 <- max of (2,8,3), (8,3,5), (3,5,1), (5,1,7)
9 9 9 8 <- max of (6,4,9), (4,9,2), (9,2,8), (2,8,3)
7 7 6 9 <- max of (1,7,5), (7,5,6), (5,6,4), (6,4,9)
8 8 8 7 <- max of (3,2,8), (2,8,7), (8,7,5), (7,5,1)
9 6 4 8 <- max of (9,6,4), (6,4,3), (4,3,2), (3,2,8)
After vertical pass (sliding max of size 3 down each column, producing 3 x 4):
9 9 9 9 <- max of (8,9,7), (8,9,7), (5,9,6), (7,8,9)
9 9 9 9 <- max of (9,7,8), (9,7,8), (9,6,8), (8,9,7)
9 8 8 8 <- max of (7,8,9), (7,8,6), (6,8,4), (9,7,8)
Verification: answer[0][0] should be the max of the 3 x 3 subgrid at (0,0): {2,8,3,6,4,9,1,7,5}. Max is 9. Correct. Check answer[1][2]: subgrid at (1,2) is {9,2,8,5,6,4,8,7,5}. Max is 9. Correct.
Complexity Analysis
Horizontal pass: For each of the N rows, run the 1D sliding window on M elements. The deque processes each element once. Cost per row: O(M). Total: O(N * M).
Vertical pass: For each of the (M - K + 1) columns of the intermediate matrix, run the 1D sliding window on N elements. Cost per column: O(N). Total: O(N * (M - K + 1)) = O(N * M).
Overall: O(N * M). No dependence on K at all.
Read that again. Whether K is 3 or 3000, the algorithm takes the same time. A 10000 x 10000 matrix with K = 5000? Still just O(N * M) = 10^8 operations. The deque handles arbitrary window sizes in O(1) amortized per element, and that property carries through to 2D.
The Minimum Variant
Need the minimum of every K x K subgrid instead? Flip the comparison in the deque's eclipse step:
- For max: pop from the back while
back <= current(smaller elements can't win). - For min: pop from the back while
back >= current(larger elements can't win).
Everything else stays identical. You can even compute both simultaneously — run two deques per pass, one for min and one for max. Still O(N * M).
Where This Shows Up
Image processing. Dilation (local max) and erosion (local min) are building blocks of morphological image processing. Both are K x K sliding window operations.
Terrain analysis. Finding the highest point in every K x K tile of a digital elevation model is exactly this problem. Useful for watershed detection and flood modeling.
Game AI. Evaluating the max resource density or min threat level across every possible K x K region of a game map. The 2D sliding window lets the AI check all placements in linear time.
Connection to Earlier Chapters
This is the natural 2D generalization of the sliding window from Chapter 2. The key technique — decompose a 2D operation into two 1D passes — is something you'll see repeatedly:
- 2D prefix sums: row-wise prefix sums, then column-wise prefix sums.
- 2D convolutions: separable filters decompose into row-wise then column-wise passes.
- 2D FFT: row-wise FFT, then column-wise FFT.
The monotonic deque fits right into this pattern. Any 1D sliding window operation that's O(N) extends to 2D in O(N * M) by doing row-pass then column-pass. The 2D problem doesn't require any new machinery — just the discipline to see the decomposition.
Try It
The starter code reads N, M, K, then the N x M matrix. It should output the (N - K + 1) x (M - K + 1) matrix of sliding window maximums.
The slidingMax function is provided but incomplete — fill in the expire and eclipse steps. The two-pass structure in main is already wired up: it calls slidingMax horizontally on each row, then vertically on each column of the intermediate result. Get slidingMax right and the rest follows.
If you want an extra challenge after that: modify the code to output both the K x K maximum and the K x K minimum for each subgrid. You'll need a slidingMin function (same logic, flipped comparison) and a second pair of passes.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| LC 962 — Maximum Width Ramp | leetcode.com/problems/maximum-width-ramp | Medium |
| LC 1793 — Max Score of Good Subarray | leetcode.com/problems/maximum-score-of-a-good-subarray | Hard |
| LC 1504 — Count Submatrices With All Ones | leetcode.com/problems/count-submatrices-with-all-ones | Medium |