Common Mistakes
TL;DR
Most API design mistakes fall into predictable categories: verbs in URLs, user IDs in request bodies, no pagination, inconsistent naming, and ignoring idempotency. Knowing these anti-patterns helps you avoid them in interviews and spot them in code reviews.
Learning what not to do is just as valuable as learning what to do. Here are the most common API design mistakes, why they're problems, and how to fix them.
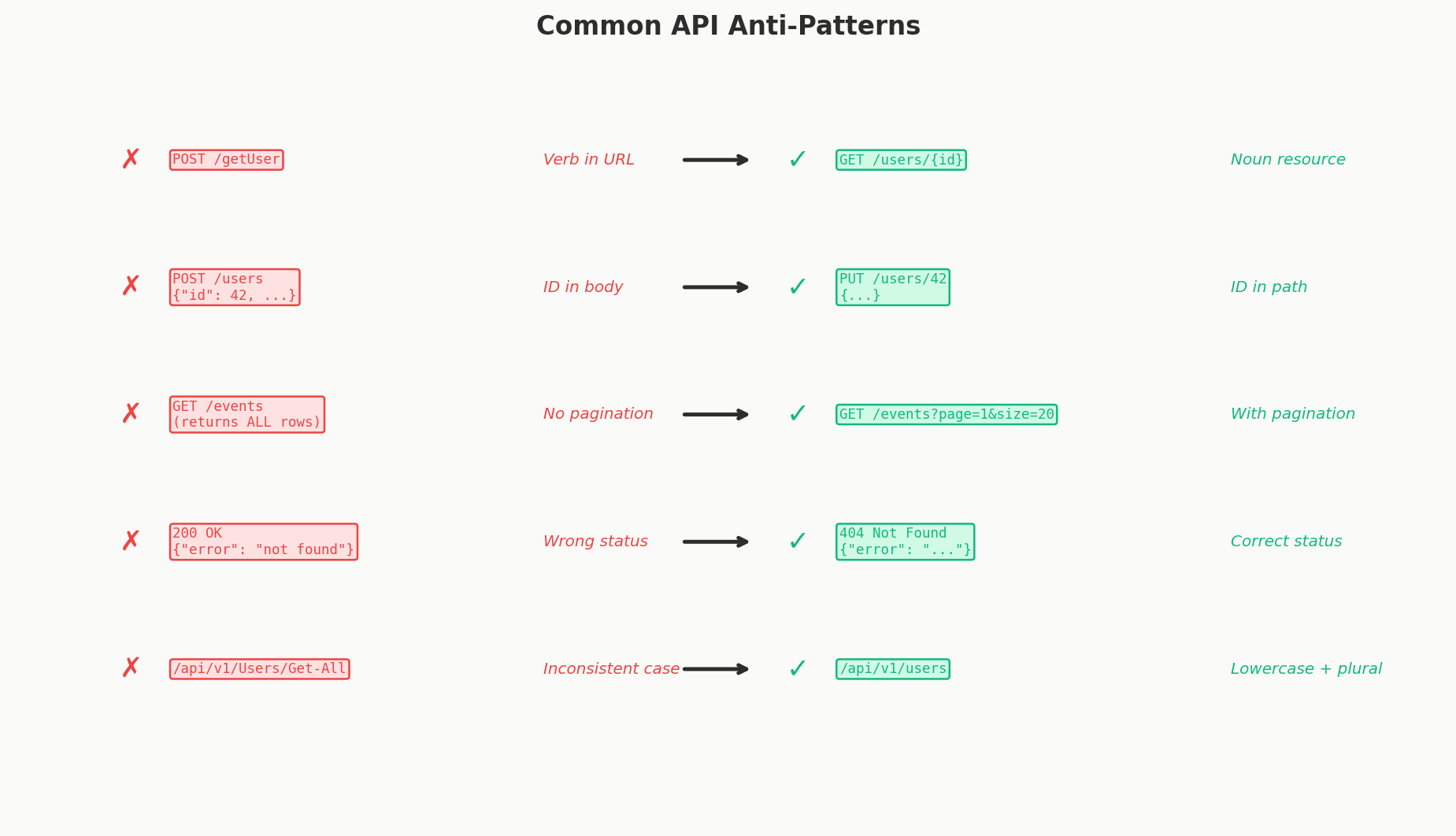
Anti-Pattern 1: Verbs in URLs
The mistake:
Why it's wrong: REST resources should be nouns. The HTTP method is the verb. Using verbs in URLs means you're duplicating information and breaking REST semantics.
The fix:
GET /users/{id} # Instead of POST /getUser
POST /bookings # Instead of POST /createBooking
DELETE /events/{id} # Instead of POST /deleteEvent
GET /events # Instead of GET /fetchAllEvents
Interview Tip
This is the most common beginner mistake. If you catch yourself writing /getX or /createY, stop and restructure.
Anti-Pattern 2: User ID in Request Body
The mistake:
Why it's wrong: Anyone can change the user_id in the request body. If your server trusts this field, any user can create bookings as any other user. This is a spoofing vulnerability.
The fix:
POST /bookings
Authorization: Bearer eyJhbGciOi...
{
"event_id": "456",
"ticket_ids": ["t1", "t2"]
}
# Server extracts user_id from the JWT token
user_id = jwt.decode(token)["sub"]
The server must extract user identity from the verified JWT token, never from the request body. Even if you include user_id in the body for convenience (e.g., admin endpoints), never rely on it server-side for authentication.
Anti-Pattern 3: Tenant ID in URL Path
The mistake:
Why it's wrong: In multi-tenant systems, putting the tenant ID in the URL path is error-prone and can lead to cross-tenant data leakage. A misconfigured client or a simple typo could expose one company's data to another.
The fix: The tenant ID should be encoded in the JWT token, extracted server-side:
GET /events
Authorization: Bearer eyJ... # JWT contains tenant_id: "acme-corp"
# Server:
tenant_id = jwt.decode(token)["tenant_id"]
events = db.query("SELECT * FROM events WHERE tenant_id = ?", tenant_id)
This makes cross-tenant access physically impossible through the API. One senior engineer described putting tenant IDs in path params as an "immediate disqualification" in interviews.
Anti-Pattern 4: Inconsistent Naming
The mistake:
GET /users # Plural, lowercase
GET /Event/{id} # Singular, capitalized
GET /get_all_tickets # Snake case, verb prefix
POST /createBookings # Camel case, verb prefix
GET /VENUE/{venue-id} # ALL CAPS
Why it's wrong: Inconsistency forces developers to check documentation for every endpoint. It increases cognitive load and causes bugs.
The fix: Pick one convention and apply it everywhere:
GET /users
GET /users/{id}
GET /events
GET /events/{id}
GET /events/{id}/tickets
POST /events/{id}/bookings
GET /venues/{id}
Rules:
- Always plural: /events, not /event
- Always lowercase: /events, not /Events
- Always kebab-case for multi-word: /event-categories, not /eventCategories
- Never verbs: /events, not /getEvents
Anti-Pattern 5: No Pagination on List Endpoints
The mistake:
Why it's wrong: Without pagination, a single API call can: - Overwhelm the server's memory - Saturate the network - Crash the client trying to parse the response - Take minutes to respond
The fix:
GET /events?limit=20&cursor=abc123
{
"data": [...], # 20 events
"next_cursor": "def456", # For next page
"has_more": true
}
Always paginate list endpoints. There is no legitimate use case for returning unbounded lists in a production API.
Interview Tip
Simply adding ?limit=20 to your list endpoints signals production awareness. Interviewers care more about including pagination than about which type you choose.
Anti-Pattern 6: Nested Pagination
The mistake:
GET /posts?page=3&per_page=20
# Each post includes comments:
{
"data": [
{
"id": "post_1",
"title": "...",
"comments": {
"data": [...], # Only first 5 comments
"page": 1,
"total_pages": 12 # How do you paginate these?
}
},
// ... 19 more posts, each with nested comment pagination
]
}
Why it's wrong: You end up with a combinatorial explosion of pagination states. Which page of comments are you on for which post? How do you navigate to page 3 of comments for post 7 while viewing page 2 of posts?
The fix: Flatten nested collections into separate endpoints:
# Posts
GET /posts?limit=20&cursor=abc
# Comments for a specific post (separate request)
GET /posts/{postId}/comments?limit=20&cursor=xyz
Each resource paginates independently. The client fetches posts first, then fetches comments for specific posts as needed.
Anti-Pattern 7: Boolean Fields That Should Be Enums
The mistake:
Why it's wrong: What happens when you need a third state? "suspended", "pending_verification", "deactivated"? You can't extend a boolean. You'd have to add new fields (is_suspended, is_pending), creating a mess of conflicting booleans.
The fix: Use enums from the start:
This is a forward compatibility principle: design fields that can grow without breaking changes.
Anti-Pattern 8: Exposing Auto-Increment IDs
The mistake:
Why it's wrong: Auto-increment IDs leak information:
- Total count: ID 50,000 means ~50,000 users exist
- Creation order: ID 100 was created before ID 200
- Enumeration: An attacker can scrape /users/1 through /users/50000
- Business intelligence: Competitors can track your growth by creating accounts and watching their ID
The fix: Use UUIDs or other non-sequential identifiers for public-facing IDs:
You can still use auto-increment IDs internally in your database for performance. Just don't expose them in the API.
Anti-Pattern 9: No Versioning Strategy
The mistake:
# Version 1: returns name as a string
GET /users/123 → { "name": "Jane Doe" }
# "Version 2": name is now an object (BREAKING CHANGE)
GET /users/123 → { "name": { "first": "Jane", "last": "Doe" } }
Why it's wrong: Clients that depend on name being a string will crash. You've broken backward compatibility with no migration path.
The fix: Use URL versioning and a deprecation strategy:
GET /v1/users/123 → { "name": "Jane Doe" } # Still works
GET /v2/users/123 → { "name": { "first": "Jane", "last": "Doe" } } # New format
When releasing a breaking change: 1. Release the new version alongside the old one 2. Announce deprecation of the old version with a timeline 3. Give clients time to migrate (months, not days) 4. Monitor usage of the old version before removing it
Anti-Pattern 10: Chatty APIs
The mistake:
# To render one user profile page:
GET /users/123 # Basic info
GET /users/123/posts?limit=10 # Recent posts
GET /users/123/followers/count # Follower count
GET /users/123/following/count # Following count
GET /users/123/posts/123/likes/count # Likes on each post
GET /users/123/posts/124/likes/count # ... for 10 posts = 10 more requests
# Total: 14 HTTP requests for one page!
Why it's wrong: Each HTTP request adds latency (connection setup, TLS handshake, round-trip time). On mobile networks with 100ms+ latency, 14 requests means the page takes seconds to load.
The fix: Several approaches:
- Composite endpoints:
GET /users/123/profilereturns everything needed for the profile page - Expansion:
GET /users/123?expand=posts,followers_count - GraphQL: Let the client specify exactly what it needs in one query
- BFF pattern: A backend-for-frontend that aggregates multiple services
Anti-Pattern 11: Ignoring Idempotency
The mistake:
# User clicks "Book" → network timeout → user clicks again
POST /bookings → 201 Created (booking #1)
POST /bookings → 201 Created (booking #2) ← DUPLICATE!
Why it's wrong: Network failures and client retries are inevitable. Without idempotency protection, you get duplicate bookings, double charges, and angry users.
The fix: Implement idempotency keys:
POST /bookings
Idempotency-Key: unique-request-id-abc123
# First call: creates booking, stores result keyed by Idempotency-Key
# Second call: sees same key, returns cached result without creating another booking
This is especially critical for: - Payment processing (double charges) - Booking systems (double bookings) - Message sending (duplicate messages) - Any operation with real-world side effects
Anti-Pattern 12: Leaky Error Messages
The mistake:
{
"error": "SQL Error: SELECT * FROM users WHERE email='admin@company.com' AND password_hash='5f4d...' - table 'users_production' not found",
"stack_trace": "at UserRepository.findByEmail(UserRepository.java:42)\n at AuthService.login(AuthService.java:18)\n ...",
"server": "prod-api-3.us-east-1.internal"
}
Why it's wrong: This error message exposes: - Database technology and table names - Internal code structure and file paths - Server names and regions - The raw SQL query being executed
Attackers use this information to craft targeted attacks.
The fix: Return generic errors externally, log detailed errors internally:
// Response to client:
{
"error": {
"code": "AUTHENTICATION_FAILED",
"message": "Invalid credentials."
}
}
// Server-side log (never exposed):
// [ERROR] AuthService.login: SQL Error on users_production table
// Query: SELECT * FROM users WHERE email=? - Stack: ...
Also note: use "Invalid credentials" instead of "User not found" or "Wrong password". Specific messages enable user enumeration attacks (attacker learns which emails are registered).
Summary: Anti-Pattern Quick Reference
| # | Anti-Pattern | Problem | Fix |
|---|---|---|---|
| 1 | Verbs in URLs | Breaks REST semantics | Use nouns + HTTP methods |
| 2 | User ID in body | Spoofing vulnerability | Extract from JWT |
| 3 | Tenant ID in path | Cross-tenant leakage | Encode in JWT |
| 4 | Inconsistent naming | Developer confusion | Plural, lowercase, kebab-case |
| 5 | No pagination | Memory bomb | Always paginate lists |
| 6 | Nested pagination | Combinatorial explosion | Flatten to separate endpoints |
| 7 | Booleans for state | Not forward-compatible | Use enums |
| 8 | Auto-increment IDs | Info leakage, enumeration | UUIDs for public IDs |
| 9 | No versioning | Breaking changes | URL versioning + deprecation |
| 10 | Chatty APIs | Excessive latency | Composite endpoints, BFF, GraphQL |
| 11 | No idempotency | Duplicates on retry | Idempotency keys |
| 12 | Leaky errors | Security exposure | Generic external, detailed internal |
| 13 | Mirroring database tables | Leaky abstraction, fragile coupling | Design around business entities, not tables |
| 14 | No async for long operations | Timeouts, retries, duplicate processing | 202 Accepted + status polling |
| 15 | Ignoring ETags / caching | Redundant data transfer, lost updates | Cache-Control, If-None-Match, If-Match |
Interview Tip
You don't need to list all 15. But if you avoid these patterns in your API design and can explain why when asked, you'll stand out as someone with production experience.
Interview Expectations: Junior vs. Senior
- Junior/Mid-level: Will recognize basic HTTP method violations or bad variable names.
- Senior/Staff: Identifies architectural anti-patterns instantly: API chattiness (N+1 over the network), leaking database schemas into UI components, lack of backward compatibility planning, and failing to define strict API contracts before starting backend implementation.