DSU Applications
DSU Isn't Just for "Are They Connected?"

Most people learn DSU, solve two connectivity problems, and move on. That's missing half the power. DSU detects cycles, builds minimum spanning trees, processes deletions backwards, and handles grid connectivity. The core operation -- merge two sets -- shows up in surprisingly many disguises.
Application 1: Cycle Detection
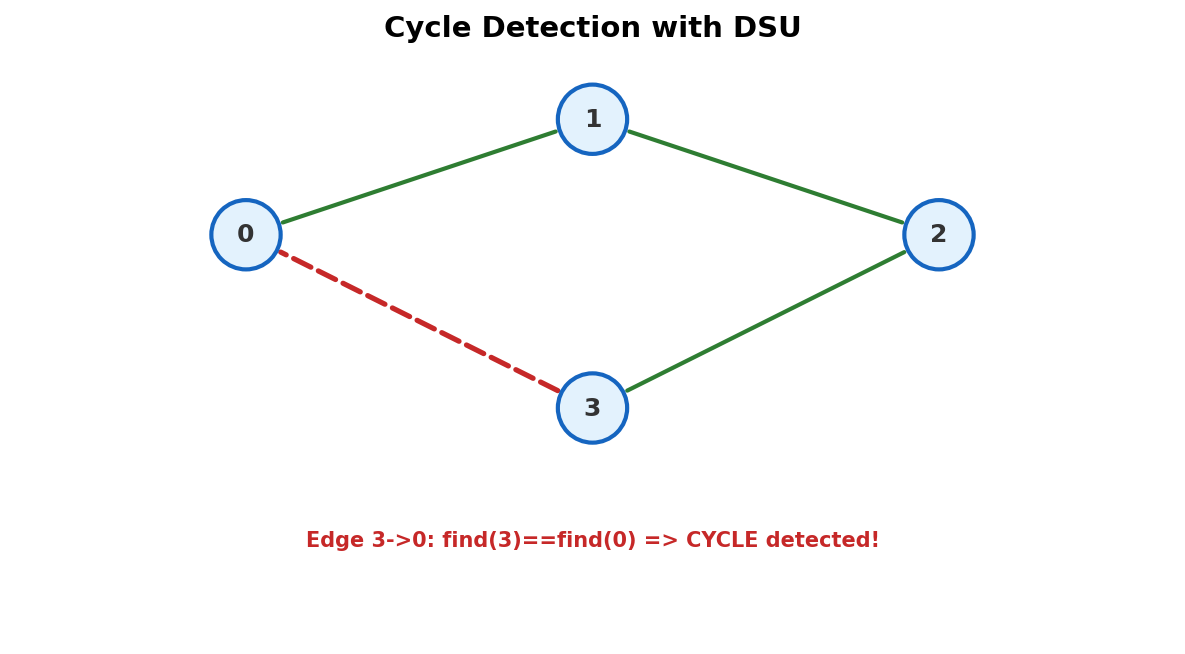
A graph with N nodes and N-1 edges is a tree. Add one more edge and you create exactly one cycle. Which edge is it?
Process edges one by one. Before each unite(u, v), check: is find(u) == find(v)? If yes, u and v are already connected. Adding this edge creates a cycle.
#include <bits/stdc++.h>
using namespace std;
int par[200005], rnk[200005];
int find(int x) {
if (par[x] != x) par[x] = find(par[x]);
return par[x];
}
void unite(int a, int b) {
a = find(a); b = find(b);
if (a == b) return;
if (rnk[a] < rnk[b]) swap(a, b);
par[b] = a;
if (rnk[a] == rnk[b]) rnk[a]++;
}
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i++) { par[i] = i; rnk[i] = 0; }
for (int i = 0; i < n; i++) {
int u, v;
cin >> u >> v;
if (find(u) == find(v)) {
cout << u << " " << v << "\n";
return 0;
}
unite(u, v);
}
}
Trace
Graph with 4 nodes, edges: (1,2), (2,3), (3,4), (4,2).
| Edge | find(u) | find(v) | Same? | Action |
|---|---|---|---|---|
| (1,2) | 1 | 2 | no | unite(1,2) |
| (2,3) | 1 | 3 | no | unite(1,3) |
| (3,4) | 1 | 4 | no | unite(1,4) |
| (4,2) | 1 | 1 | yes | Cycle found! |
Edge (4,2) is redundant. Both endpoints already share root 1.
💡 Key insight. DSU detects cycles in O(n * alpha(n)) without building an adjacency list. DFS can also detect cycles, but DSU does it edge-by-edge as you read input.
Application 2: Kruskal's MST (Preview)
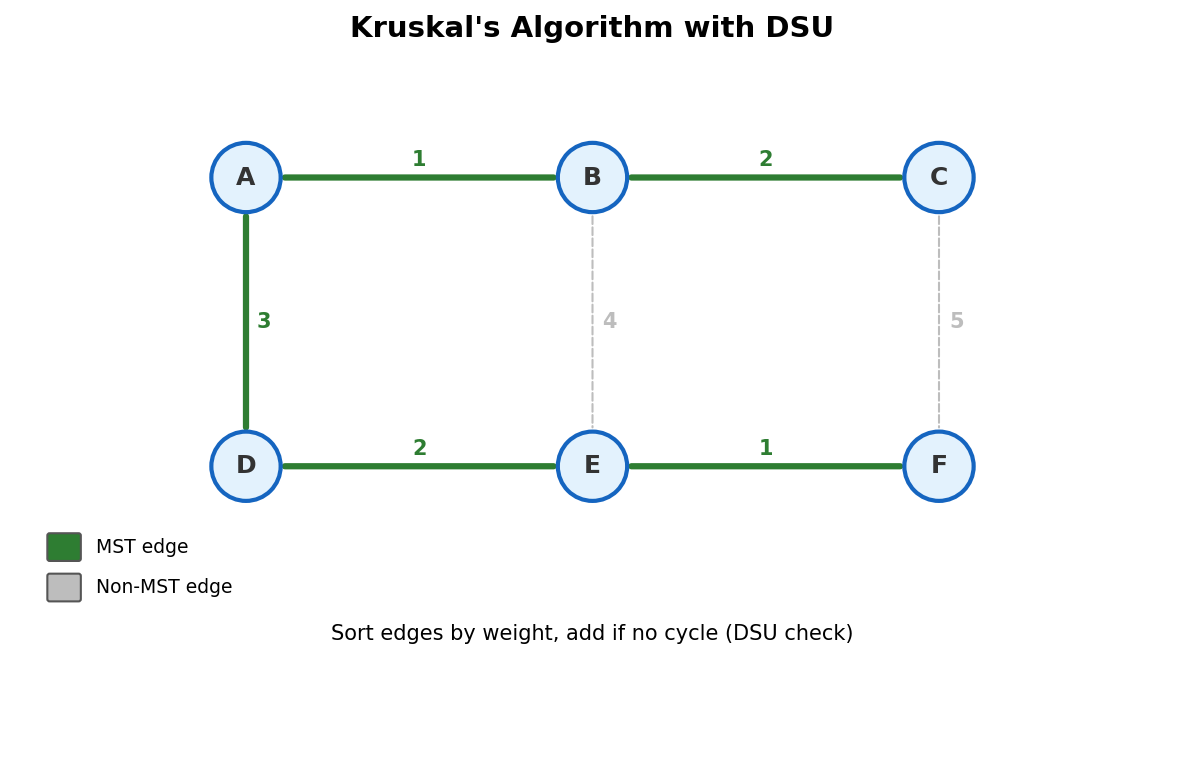
Kruskal's algorithm (covered in depth in Chapter 13) sorts edges by weight and greedily adds the cheapest edge that doesn't create a cycle. "Doesn't create a cycle" is exactly the DSU check.
struct Edge { int u, v, w; };
long long kruskal(vector<Edge>& edges, int n) {
sort(edges.begin(), edges.end(),
[](auto& a, auto& b) { return a.w < b.w; });
for (int i = 1; i <= n; i++) { par[i] = i; rnk[i] = 0; }
long long cost = 0;
int taken = 0;
for (auto [u, v, w] : edges) {
if (find(u) != find(v)) {
unite(u, v);
cost += w;
if (++taken == n - 1) break;
}
}
return cost;
}
Three lines of DSU inside a loop. That's the entire MST algorithm.
⚠ Gotcha. Kruskal's needs sorting, which is O(E log E). The DSU part is nearly linear. Don't blame DSU for Kruskal's time complexity.
Application 3: Offline Trick — Deletions as Additions
DSU can merge sets but can't split them. So how do you handle edge deletions?
Process queries in reverse. Deletions become additions. Additions become deletions (which you ignore since you're building forward).
Pattern: 1. Read all edges and all queries. 2. Mark which edges are deleted at some point. 3. Build the initial DSU with only the edges that are never deleted. 4. Process queries from last to first. Each "delete edge" becomes "add edge." 5. Store answers in reverse order.
Forward: add(1,2), add(2,3), delete(1,2), query(1,3)
Reverse: query(1,3), add(1,2), delete(2,3) [ignore], delete(1,2) [ignore]
In the reverse pass, when we hit the query, edges (2,3) is present but (1,2) hasn't been re-added yet. So 1 and 3 are not connected. Correct.
💡 Key insight. The offline trick works for any monotone data structure. If your structure can only grow (add elements, merge sets), process removals in reverse to turn them into additions.
Application 4: Grid Problems
Grids are graphs. Each cell is a node, adjacent cells sharing the same value (or satisfying some condition) are connected by edges. DSU handles this naturally.
int rows, cols;
int id(int r, int c) { return r * cols + c; }
int dx[] = {0, 0, 1, -1};
int dy[] = {1, -1, 0, 0};
int countRegions(vector<vector<int>>& grid) {
int n = rows * cols;
for (int i = 0; i < n; i++) { par[i] = i; rnk[i] = 0; }
for (int r = 0; r < rows; r++)
for (int c = 0; c < cols; c++)
for (int d = 0; d < 4; d++) {
int nr = r + dx[d], nc = c + dy[d];
if (nr >= 0 && nr < rows && nc >= 0 && nc < cols
&& grid[r][c] == grid[nr][nc])
unite(id(r, c), id(nr, nc));
}
set<int> roots;
for (int i = 0; i < n; i++)
roots.insert(find(i));
return roots.size();
}
This counts regions of equal values, identical to flood fill but without recursion or a queue.
⚠ Gotcha. When iterating over all 4 neighbors, each edge gets processed twice (once from each side). That's fine --
uniteignores same-component merges. But don't count edges twice if you're tracking edge counts.
Application 5: AtCoder abc350_d — New Friends
Problem: N people, M friendships. Two people become friends if they share a mutual friend. Repeat until no new friendships form. How many new friendships are created?
Insight: "Friends of friends become friends" means every connected component becomes a complete graph. A component of size k has k*(k-1)/2 edges in the complete graph. New edges = complete graph edges - original edges.
#include <bits/stdc++.h>
using namespace std;
int par[200005], sz[200005];
int find(int x) {
if (par[x] != x) par[x] = find(par[x]);
return par[x];
}
void unite(int a, int b) {
a = find(a); b = find(b);
if (a == b) return;
if (sz[a] < sz[b]) swap(a, b);
par[b] = a;
sz[a] += sz[b];
}
int main() {
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i++) { par[i] = i; sz[i] = 1; }
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
unite(u, v);
}
long long ans = 0;
for (int i = 1; i <= n; i++) {
if (find(i) == i) {
long long s = sz[i];
ans += s * (s - 1) / 2;
}
}
ans -= m; // subtract existing friendships
cout << ans << "\n";
}
Trace
5 people, 3 friendships: (1,2), (2,3), (4,5).
| Edge | Action | Components |
|---|---|---|
| (1,2) | unite(1,2) | {1,2}, {3}, {4,5} |
| wait -- process all edges first | ||
| (2,3) | unite(2,3) | {1,2,3}, {4}, {5} |
| (4,5) | unite(4,5) | {1,2,3}, |
Component {1,2,3}: complete graph has 32/2 = 3 edges, had 2 original, so 1 new. Component {4,5}: complete graph has 21/2 = 1 edge, had 1 original, so 0 new. Total new friendships: 1.
When to Choose DSU vs DFS/BFS
| Scenario | Best tool | Why |
|---|---|---|
| Edges arrive online, need connectivity after each | DSU | Incremental merging |
| Need to find all nodes in a component | DFS/BFS | DSU doesn't store adjacency |
| Cycle detection during edge processing | DSU | One check per edge |
| Need shortest path or distances | BFS/Dijkstra | DSU has no notion of distance |
| Process deletions offline | DSU (reverse) | Turn deletions into merges |
| Need MST | DSU (Kruskal's) | Greedy + cycle check |
| Grid flood fill with simple connectivity | Either | DSU avoids recursion depth issues |
💡 Key insight. DSU answers "are they connected?" but not "how are they connected?" If you need the actual path or distance, use BFS/DFS. If you only need the yes/no answer, DSU is almost always faster and simpler.
Try It
The starter code has DSU ready. Find the redundant edge in a graph with N nodes and N edges.
Test case 1:
Test case 2:
Challenge: Modify the solution to handle LC 685 (Redundant Connection II), where the graph is directed. This requires handling two extra cases: a node with two parents, and a cycle in a directed graph.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| LC 684 — Redundant Connection | leetcode.com/problems/redundant-connection | Medium |
| LC 1135 — Connecting Cities With Minimum Cost | leetcode.com/problems/connecting-cities-with-minimum-cost | Medium |
| AtCoder abc350_d — New Friends | atcoder.jp/contests/abc350/tasks/abc350_d | Medium |
| CSES Road Construction | cses.fi/problemset/task/1676 | Easy |