Caching
TL;DR
A cache stores frequently accessed data in fast memory so you don't hit the database for every read. The hard part isn't adding a cache — it's keeping it consistent with the database when data changes. Four strategies exist (cache-aside, read-through, write-through, write-behind), each with different consistency and performance trade-offs. Cache versioning solves the subtle but devastating stale-cache-poisoning problem that trips up even experienced engineers.
The Sticky Note on Your Monitor
A cache is a sticky note on your monitor.
Need a coworker's phone number? Check the sticky note first. If it's there — cache hit — you get the answer instantly. If it's not — cache miss — you open the filing cabinet (the database), find the number, write it on a sticky note for next time, and carry on.
That's it. That's caching. You're trading a small amount of fast storage (sticky note, RAM) to avoid repeatedly accessing slow storage (filing cabinet, disk).
Request Flow With Cache
─────────────────────────────────────────
Client
│
▼
Check sticky note (cache)
│
├── HIT → return instantly (~1ms)
│
└── MISS → open filing cabinet (database, ~10-50ms)
→ write sticky note for next time
→ return data
The numbers make the case by themselves. A Redis cache serves reads in 0.1-1ms. A PostgreSQL query on indexed data takes 5-50ms. On unindexed data? 100ms+. When you multiply that difference across thousands of concurrent users, caching is the difference between a snappy app and one that buckles under load.
But here's the catch: sticky notes go stale. Your coworker changes their phone number — your sticky note still has the old one. Cache invalidation — keeping the cache in sync with the database — is where all the complexity lives.
The Four Caching Strategies
There are exactly four ways to wire a cache into your system. Each makes a different trade-off between simplicity, consistency, and performance.
Strategy 1: Cache-Aside (Lazy Loading)
The application controls everything. It checks the cache, handles misses by querying the database, and populates the cache itself. The cache is a dumb key-value store — it has no idea the database exists.
This is the most common strategy in production systems. If someone says "we added caching" without specifying a strategy, they almost certainly mean cache-aside.
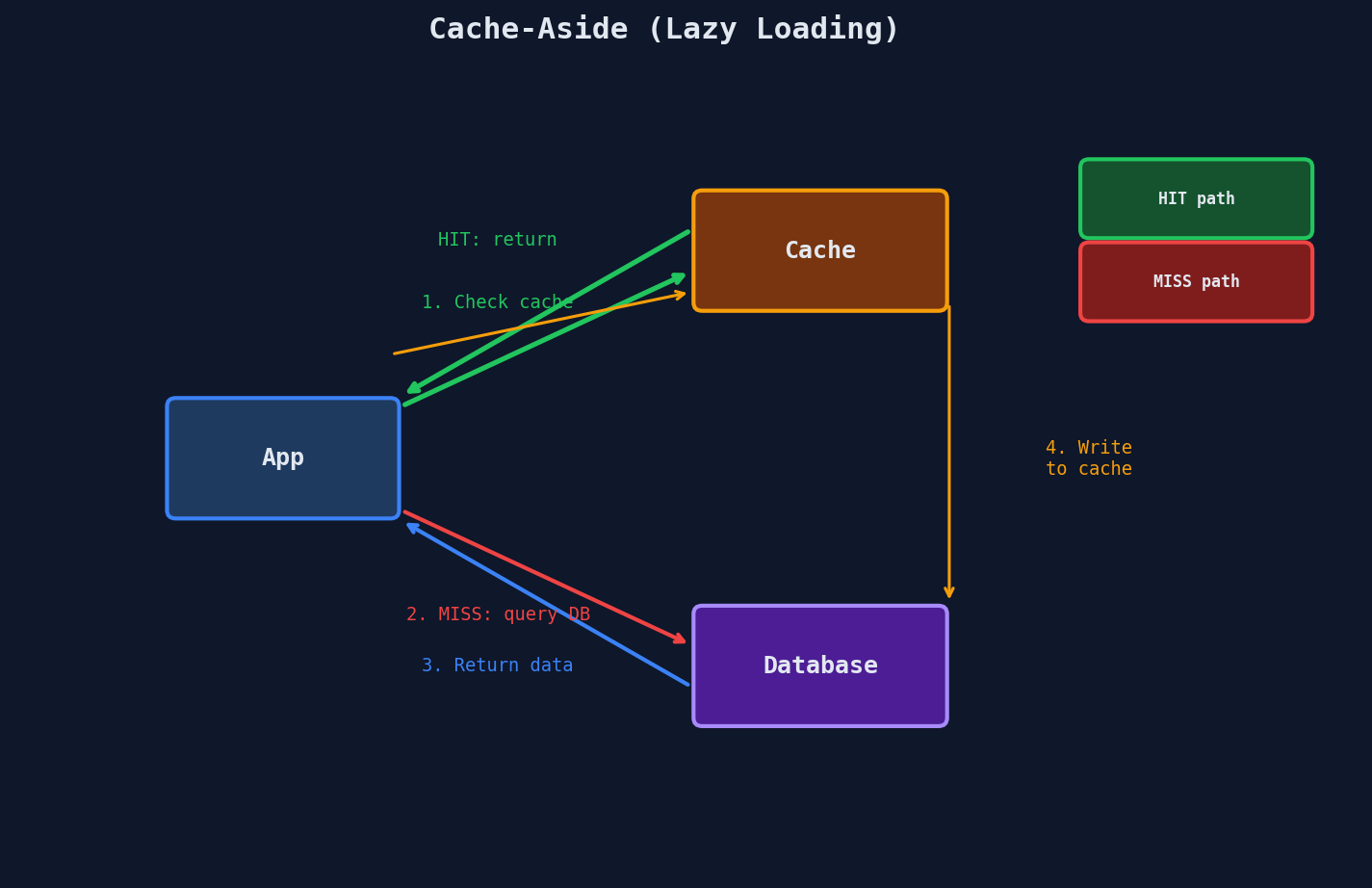
The code is dead simple:
def get_user(user_id):
# 1. Check cache first
data = cache.get(f"user:{user_id}")
if data is None:
# 2. Cache miss — hit the database
data = db.query("SELECT * FROM users WHERE id = %s", user_id)
# 3. Populate cache for next time
cache.set(f"user:{user_id}", data, ttl=300)
# 4. Return data (from cache or DB)
return data
Pros:
- Only caches data that's actually requested — no wasted memory on unread rows
- Cache failure doesn't break reads — you fall back to the database
- Simple to implement and reason about
Cons:
- First request for every key always misses (cold start penalty)
- Data can be stale until TTL expires
- Application code carries the caching logic — every read path needs the check-miss-populate pattern
When to Use
Cache-aside is your default choice. Use it for general-purpose read-heavy workloads where eventual consistency (within your TTL window) is acceptable. Social media profiles, product catalogs, configuration data — all classic cache-aside use cases.
Strategy 2: Read-Through
The cache itself fetches from the database on a miss. The application only ever talks to the cache — it has no idea whether data came from memory or from a database lookup behind the scenes.
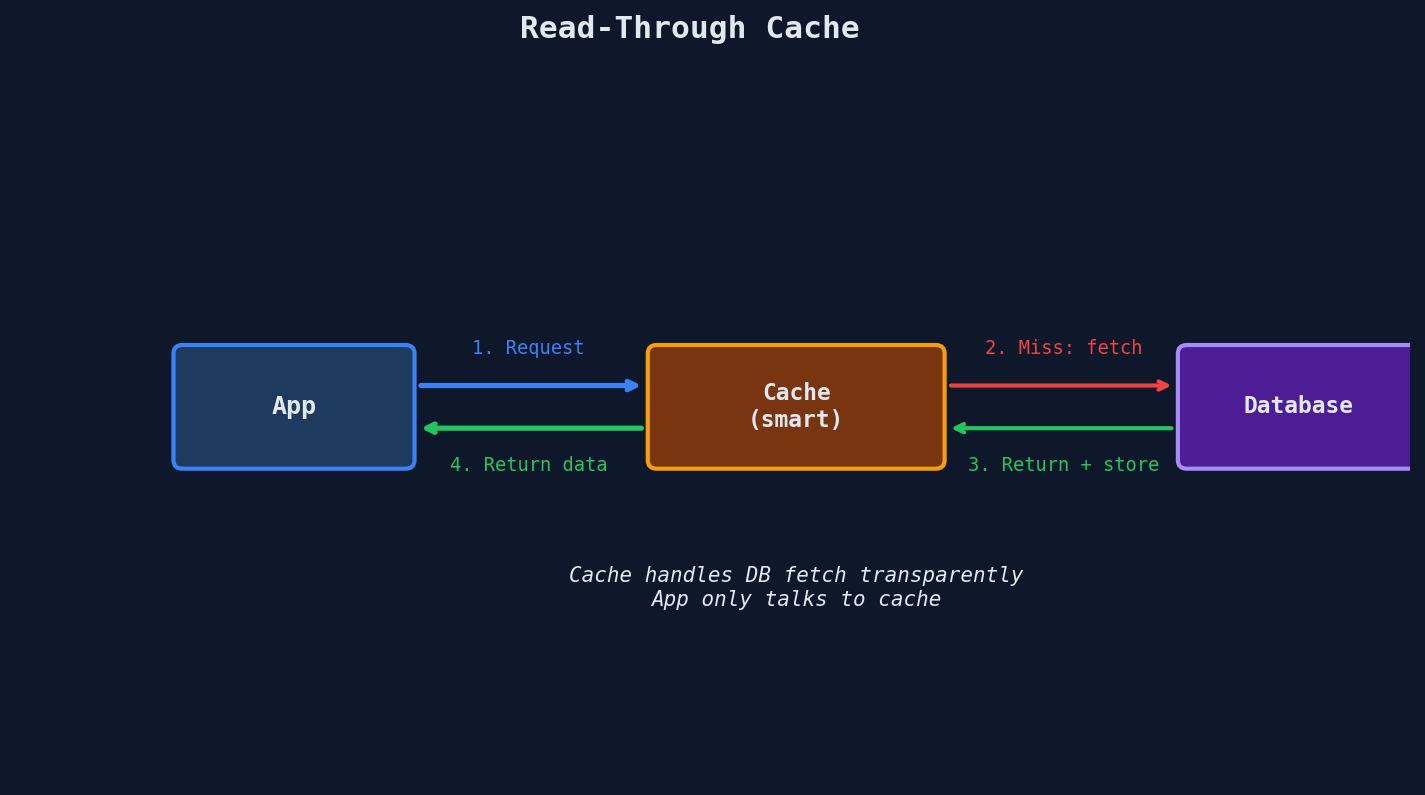
The difference from cache-aside is subtle but important: the cache handles the miss, not the application. Your app code shrinks to:
def get_user(user_id):
# Cache handles miss internally — app doesn't know or care
return cache.get(f"user:{user_id}")
Pros:
- Simpler application code — no miss-handling logic scattered across your codebase
- Cache layer is the single source of truth for read behavior
Cons:
- The cache must understand your database schema and how to query it
- Most off-the-shelf caches (Redis, Memcached) don't support this natively — you need a wrapper library or a managed service like Amazon DynamoDB Accelerator (DAX)
- Same cold start penalty as cache-aside
Strategy 3: Write-Through
Every write goes through the cache and the database synchronously. The cache is updated at write time, not at read time. By the time the write returns, both the cache and the database are guaranteed to have the new data.
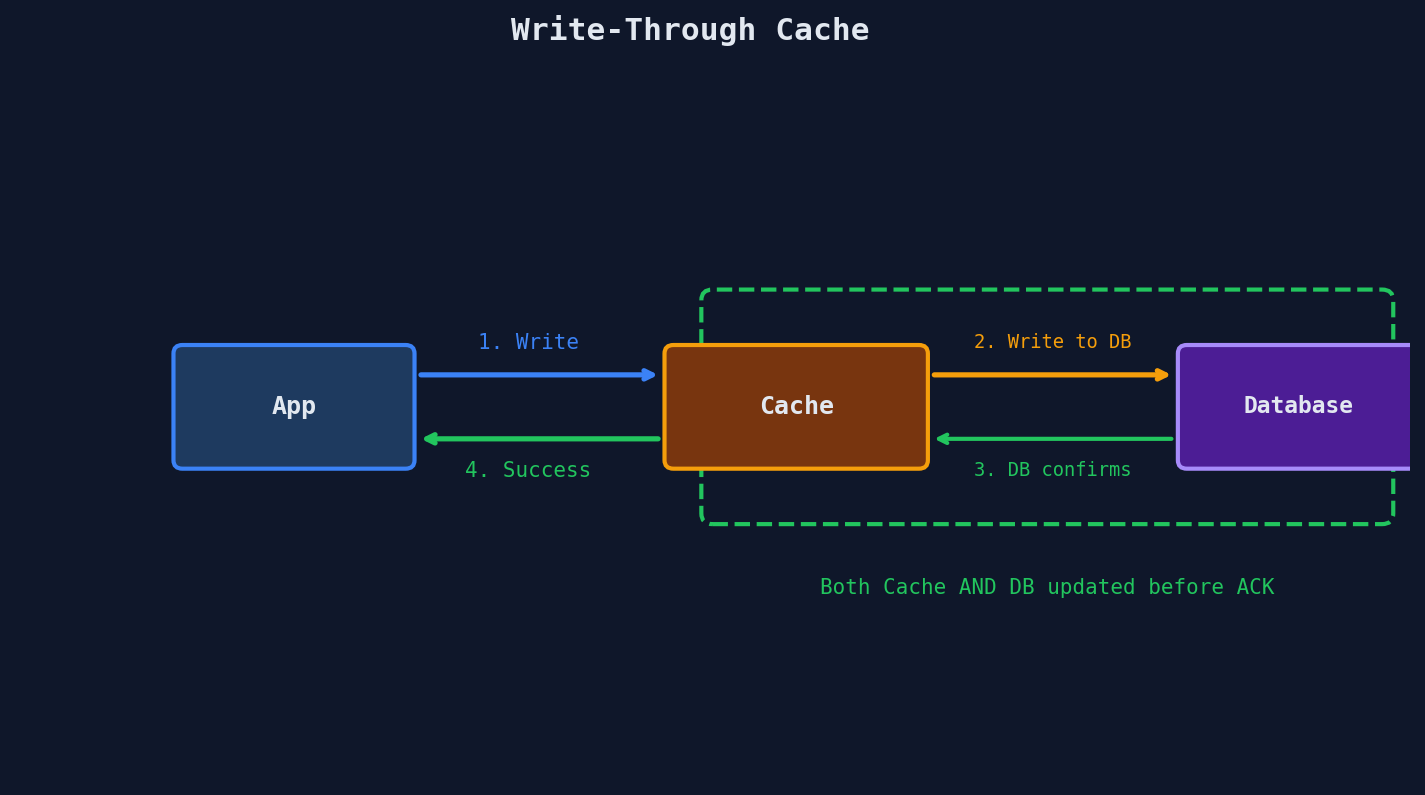
def update_user(user_id, new_data):
# Write to cache AND database before returning
cache.set(f"user:{user_id}", new_data)
db.execute("UPDATE users SET ... WHERE id = %s", user_id, new_data)
return new_data
Pros:
- Cache is always up-to-date — no staleness window
- Read-after-write consistency guaranteed (write a value, immediately read it back, get the new value)
Cons:
- Write latency increases — every write now hits two systems synchronously
- Caches data that may never be read — if you update 10,000 user profiles, all 10,000 land in the cache even if only 50 are ever read again
- Both cache and DB must succeed — introduces a coordination problem
Write-Through Doesn't Mean Write-Only
Write-through is almost always combined with cache-aside or read-through for the read path. Write-through handles writes; you still need a read strategy for cache misses on data that was never written through this path (e.g., data that existed before caching was added).
Strategy 4: Write-Behind (Write-Back)
Write to the cache and return immediately. The cache asynchronously flushes to the database in the background, often batching multiple writes together.
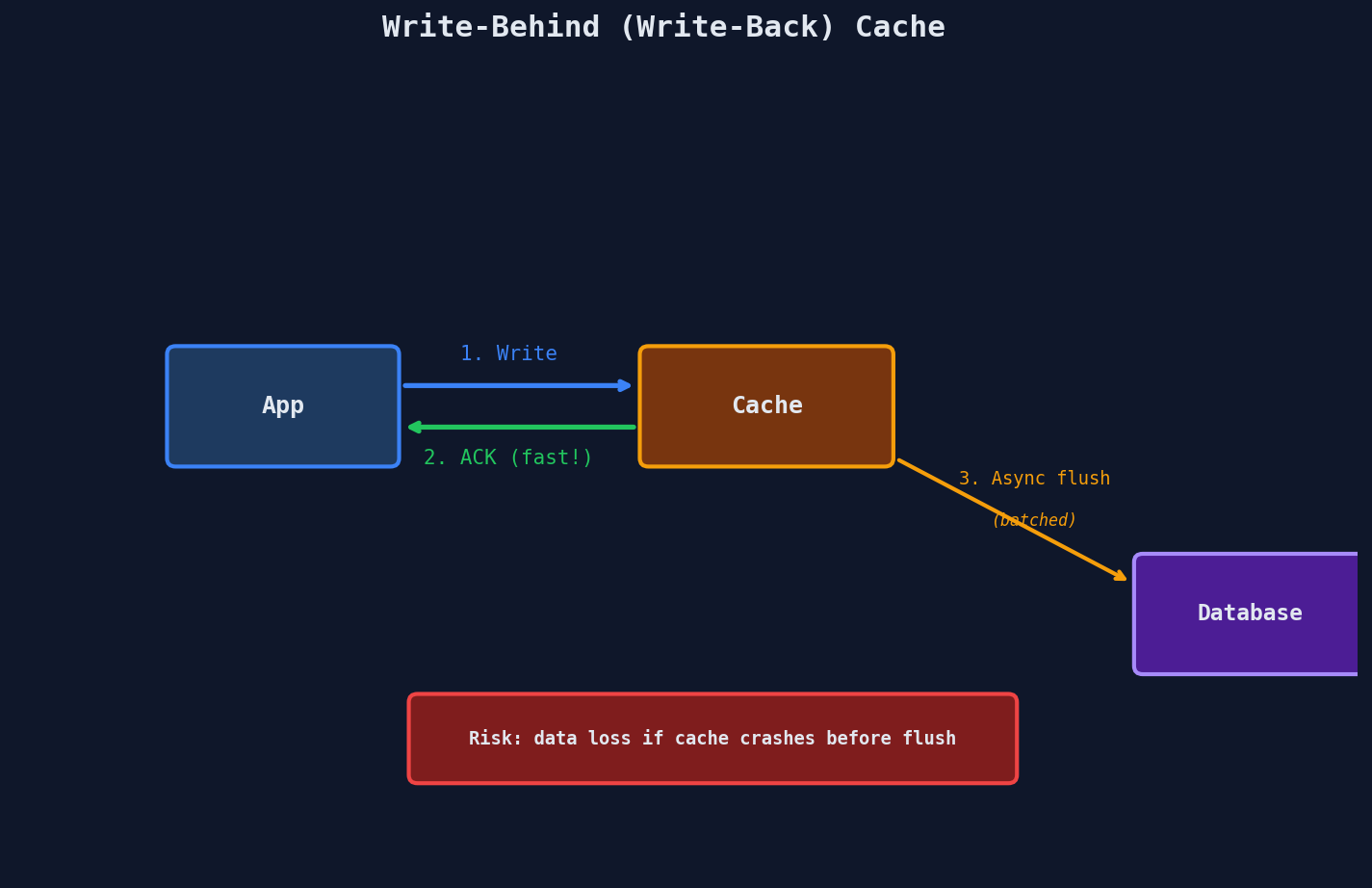
Pros:
- Fastest writes possible — the app never waits for the database
- Batch flushes reduce total database write operations (10 individual writes become 1 batch)
- Great for write-heavy bursts (analytics events, view counters, activity logs)
Cons:
- Data loss risk — if the cache crashes before flushing to the database, those writes are gone forever
- Harder to debug — writes succeed from the app's perspective but may fail at the DB level later
- Ordering and conflict resolution become complex in distributed setups
Data Loss Is Real
Write-behind is a calculated risk. Use it for data you can afford to lose (view counts, analytics) or data you can reconstruct. Never use it for financial transactions, user credentials, or anything where losing a write is unacceptable.
Decision Table — When to Use Which Strategy
| Strategy | Best For | Consistency | Write Latency | Risk |
|---|---|---|---|---|
| Cache-aside | General purpose, read-heavy | Eventual (TTL) | No impact | Stale reads |
| Read-through | Simpler app code | Eventual | No impact | Cache complexity |
| Write-through | Read-after-write needed | Strong | Higher | Caching unread data |
| Write-behind | Write-heavy + fast reads | Eventual | Lowest | Data loss on crash |
In practice, most production systems use cache-aside and bolt on TTL-based invalidation. The other three strategies appear in specific scenarios — managed caching layers (read-through), financial systems that need read-after-write (write-through), and high-throughput metrics pipelines (write-behind).
Cache Invalidation — "The Two Hard Problems"
There's a famous joke in computer science:
There are only two hard things in computer science: cache invalidation and naming things.
It's funny because it's true. Adding a cache takes an afternoon. Keeping the cache consistent with the database is a career-long struggle.
Approach 1: TTL-Based Expiry
The simplest approach. Set a time-to-live on every cache entry. After the TTL expires, the key is deleted and the next read triggers a fresh fetch from the database.
This means your data can be up to 5 minutes stale. For a user profile, that's probably fine. For a stock price, it's catastrophic.
When it works: product catalogs, user profiles, configuration data, blog posts — anything where "slightly stale" is acceptable.
When it doesn't: real-time pricing, inventory counts, anything with financial implications.
Approach 2: Event-Driven Invalidation
When the database changes, publish an event that tells the cache to delete or update the affected key.
def update_user(user_id, new_data):
db.execute("UPDATE users SET ... WHERE id = %s", user_id, new_data)
cache.delete(f"user:{user_id}") # invalidate — next read will repopulate
This is more responsive than TTL — the cache is invalidated within milliseconds of the write, not minutes. But it requires discipline: every write path in your application must remember to invalidate the cache. Miss one, and you have a stale entry that persists until its TTL (if you even set one).
Approach 3: Cache Versioning — Solving The Poisoning Problem
This is the one that generates the most confusion. Over 30 questions from the community. Let's break it down carefully.
The Problem: Stale Cache Poisoning
Imagine you have a primary database and a read replica with a small replication lag. You're using cache-aside with event-driven invalidation.
Here's the disaster scenario, step by step:
Timeline:
─────────────────────────────────────────────────────────
t1: Writer updates DB primary: product:123 → price $29.99
t2: Writer deletes cache key: DELETE product:123
t3: Reader gets cache miss, reads from REPLICA
(replica still has old price $19.99 due to replication lag)
t4: Reader writes stale data to cache:
SET product:123 = {price: $19.99}
─────────────────────────────────────────────────────────
Result: Cache is now POISONED with $19.99
TTL won't save you — it could be stale for minutes
Every reader for the next TTL window gets the wrong price
The writer did everything right — updated the DB, invalidated the cache. But a reader racing against replication lag re-populated the cache with stale data. The cache is now poisoned with old data, and it will serve that stale value to every subsequent reader until the TTL expires.
This is particularly nasty because it's intermittent. It only happens when a read lands on a lagging replica at exactly the wrong moment. You can't reproduce it reliably, and it fixes itself after the TTL expires — so it looks like a ghost.
The Solution: Two Cache Entries Per Key
Instead of one cache entry per key, store two:
{key}:version— a pointer to the current version number{key}:v{N}— the actual data for version N
Before versioning (one entry):
product:123 → {"name": "Widget", "price": 29.99}
After versioning (two entries):
product:123:version → "v4"
product:123:v4 → {"name": "Widget", "price": 29.99}
How It Works: The Writer
When the writer updates the database, it bumps the version pointer and writes new data under the new version key:
# Writer updates product price to $29.99
SET product:123:version "v4"
SET product:123:v4 '{"name":"Widget","price":29.99}' EX 3600
The old version key (product:123:v3) is not deleted — it's left to expire naturally via its own TTL.
How It Works: The Reader
The reader always does a two-step lookup:
# Step 1: What's the current version?
GET product:123:version → "v4"
# Step 2: Fetch data for that version
GET product:123:v4 → hit! return data
If step 2 misses (the versioned key expired or was never populated), the reader fetches from the database and populates that specific version:
# Step 2 missed — fetch and populate
GET product:123:v4 → null (miss)
# Fetch from DB
SELECT * FROM products WHERE id = 123
# Populate ONLY the versioned key
SET product:123:v4 '{"name":"Widget","price":29.99}' EX 3600
Why Stale Readers Can't Poison the Cache
Here's the magic. Replay the disaster scenario with versioning:
Timeline (with versioning):
─────────────────────────────────────────────────────────
t1: Writer updates DB primary: product:123 → price $29.99
t2: Writer sets version pointer: SET product:123:version "v4"
t3: Writer sets versioned data: SET product:123:v4 = {price: $29.99}
t4: Stale reader (from lagging replica) reads version pointer
GET product:123:version → "v3" (got old version due to timing)
t5: Stale reader fetches: GET product:123:v3 → {price: $19.99}
Serves old data — BUT writes NOTHING to v4
─────────────────────────────────────────────────────────
Result: v4 still contains $29.99 ✓
Stale reader served old data once, but DIDN'T poison v4
Next reader gets version "v4" and sees correct price
The stale reader's old data lives in its own version bucket (v3). It physically cannot overwrite the current version's data (v4). The worst case is that one reader gets slightly old data — but it doesn't cascade to every subsequent reader.
Full Redis Command Flow
# ── Writer Flow ──────────────────────────────────────
# Update database first
UPDATE products SET price = 29.99 WHERE id = 123;
# Bump version and write new versioned entry
SET product:123:version "v4"
SET product:123:v4 '{"name":"Widget","price":29.99}' EX 3600
# ── Reader Flow ──────────────────────────────────────
# Step 1: Get current version
GET product:123:version → "v4"
# Step 2: Fetch versioned data
GET product:123:v4 → '{"name":"Widget","price":29.99}'
# Hit! Return data.
# ── Reader Flow (version key miss) ──────────────────
GET product:123:version → null
# Fetch from DB, determine version from DB (e.g., updated_at timestamp)
SET product:123:version "v4"
SET product:123:v4 '{"name":"Widget","price":29.99}' EX 3600
# ── Old Versions ─────────────────────────────────────
# product:123:v1, v2, v3 expire naturally via TTL
# No manual cleanup needed
Why This Beats Write-Through for Consistency
Write-through guarantees consistency by synchronously updating cache and DB — but that requires coordinating two systems on every write. If either fails, you're in an inconsistent state unless you add two-phase commit (2PC) or distributed locks. That's heavy machinery.
Cache versioning achieves something almost as good with zero coordination:
- No 2PC needed
- No distributed locks
- Stale readers can't poison the current version
- Old versions expire automatically via TTL
The Trade-Off
Cache versioning adds a second Redis read to every request (one for the version pointer, one for the data). This is worth it when stale cache poisoning is a real risk — systems with read replicas, high write rates, and price/inventory-sensitive data. Don't add versioning to every key in your system. For a user's display name? TTL-based invalidation is fine.
Redis vs Memcached — Picking Your Cache
Two tools dominate the caching landscape. Here's how they compare:
| Feature | Redis | Memcached |
|---|---|---|
| Data structures | Strings, lists, sets, sorted sets, hashes | Strings only |
| Persistence | RDB snapshots + AOF log | None |
| Replication | Built-in leader-follower | None |
| Threading | Single-threaded (I/O threads in 6.0+) | Multi-threaded |
| Max value size | 512 MB | 1 MB |
| Eviction policies | 8 policies (LRU, LFU, random, volatile, etc.) | LRU only |
| Pub/Sub | Built-in | None |
| Lua scripting | Yes | None |
| Cluster mode | Redis Cluster (auto-sharding) | Client-side sharding only |
| Best for | Feature-rich caching, leaderboards, sessions, queues | Pure high-throughput key-value |
Rule of thumb: Use Redis unless you need raw multi-threaded throughput with simple key-value lookups and zero advanced features. In practice, Redis wins ~90% of the time because its richer data structures (sorted sets for leaderboards, hashes for partial updates, pub/sub for invalidation) save you from building that logic in your application.
Memcached still shines when you have a massive, simple key-value workload and need to squeeze every microsecond out of multi-threaded performance. Facebook's Memcached deployment handles billions of requests per day across hundreds of servers — but they also built an entire custom ecosystem around it.
Interview Shortcut
Unless the interviewer specifically asks about Memcached, default to Redis in your designs. It's the safer, more versatile choice and shows you understand the broader feature set. If they press you, mention that Memcached can outperform Redis on pure key-value throughput due to multi-threading.
Quick Recap
| Concept | Key Takeaway |
|---|---|
| Cache-aside | App checks cache, handles misses, populates cache. Most common strategy. |
| Read-through | Cache handles misses internally. Simpler app code, more complex cache. |
| Write-through | Writes update cache + DB synchronously. Strong consistency, slower writes. |
| Write-behind | Writes go to cache, async flush to DB. Fast writes, data loss risk. |
| TTL invalidation | Set expiry on cache entries. Simple, accept bounded staleness. |
| Event-driven invalidation | Delete cache key on write. Responsive, but every write path must remember. |
| Cache versioning | Two entries per key (version pointer + versioned data). Prevents stale cache poisoning. |
| Redis vs Memcached | Redis for features, Memcached for raw throughput. Default to Redis. |
Interview Tip
Always mention your cache invalidation strategy. Saying "I'll add a cache" without explaining HOW you keep it consistent is a red flag. Interviewers want to hear you wrestle with staleness — TTL windows, invalidation events, or versioning — because that's where the real engineering lives. The cache itself is easy. The consistency is hard.