CQRS, Event Sourcing & Materialized Views
TL;DR
CQRS separates your read and write models so each can be optimized independently. Event sourcing stores every change as an immutable event instead of overwriting state. Materialized views pre-compute query results for fast reads. Together, they solve the problem of wildly different read and write requirements — but they add significant complexity.
The Problem: Reads and Writes Want Different Things
Imagine a banking application. For writes, you need strict ACID transactions — "transfer $100 from account A to account B" must be atomic, consistent, and isolated. A normalized schema with proper constraints is essential.
For reads, the same bank needs dashboards showing "total transactions this month," "average balance by region," "suspicious activity patterns." These queries need denormalized data with pre-computed aggregates — the opposite of what writes want.
Trying to serve both through the same data model is like using the same vehicle for Formula 1 racing and cross-country hauling. You end up with a compromised design that's mediocre at both.
From Denormalization to CQRS — A Spectrum
If you've read the Schema Design chapter, you already know the basics of this pattern. In Chapter 2, we denormalized a like_count onto the posts table to avoid a COUNT(*) join on every read. That was a simple, manual optimization: one denormalized field, updated atomically on writes.
CQRS is the same idea taken to its logical conclusion. Instead of sprinkling denormalized fields across your existing tables, you build an entirely separate read model — purpose-built for your query patterns — alongside the write model. Think of it as a progression:
Level 1: Denormalized column (like_count on posts) ← Chapter 2
Level 2: Materialized view (pre-computed query result) ← This lesson
Level 3: Separate read database (Elasticsearch, Redis) ← Full CQRS
Level 4: Event-sourced writes + derived read models ← CQRS + Event Sourcing
Each level adds complexity but solves a wider gap between read and write requirements.
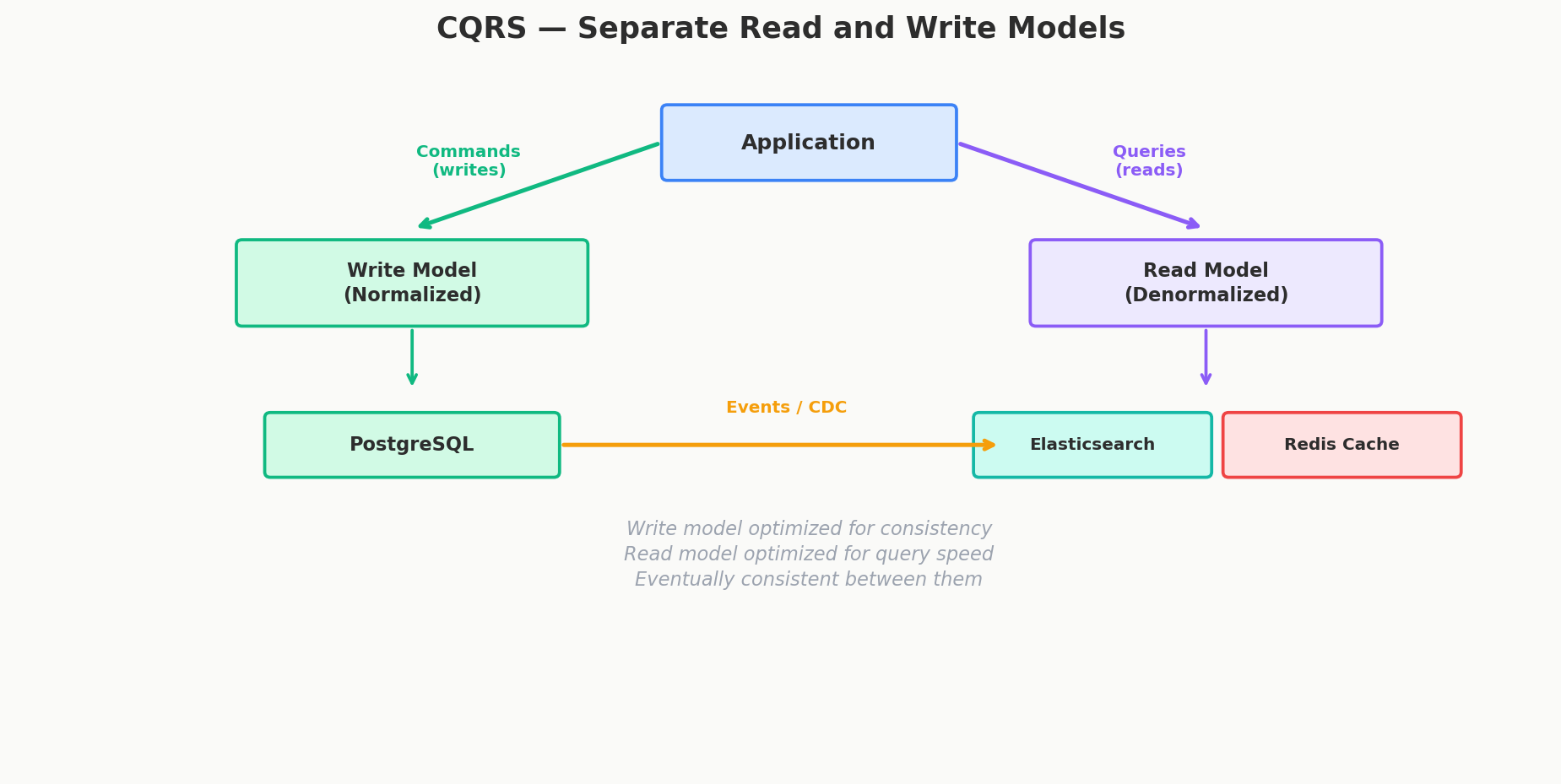
CQRS — Command Query Responsibility Segregation
CQRS splits your system into two sides:
- Command side (writes): Handles mutations. Normalized, optimized for consistency. Uses ACID transactions.
- Query side (reads): Handles reads. Denormalized, optimized for specific query patterns. Can use different storage entirely.
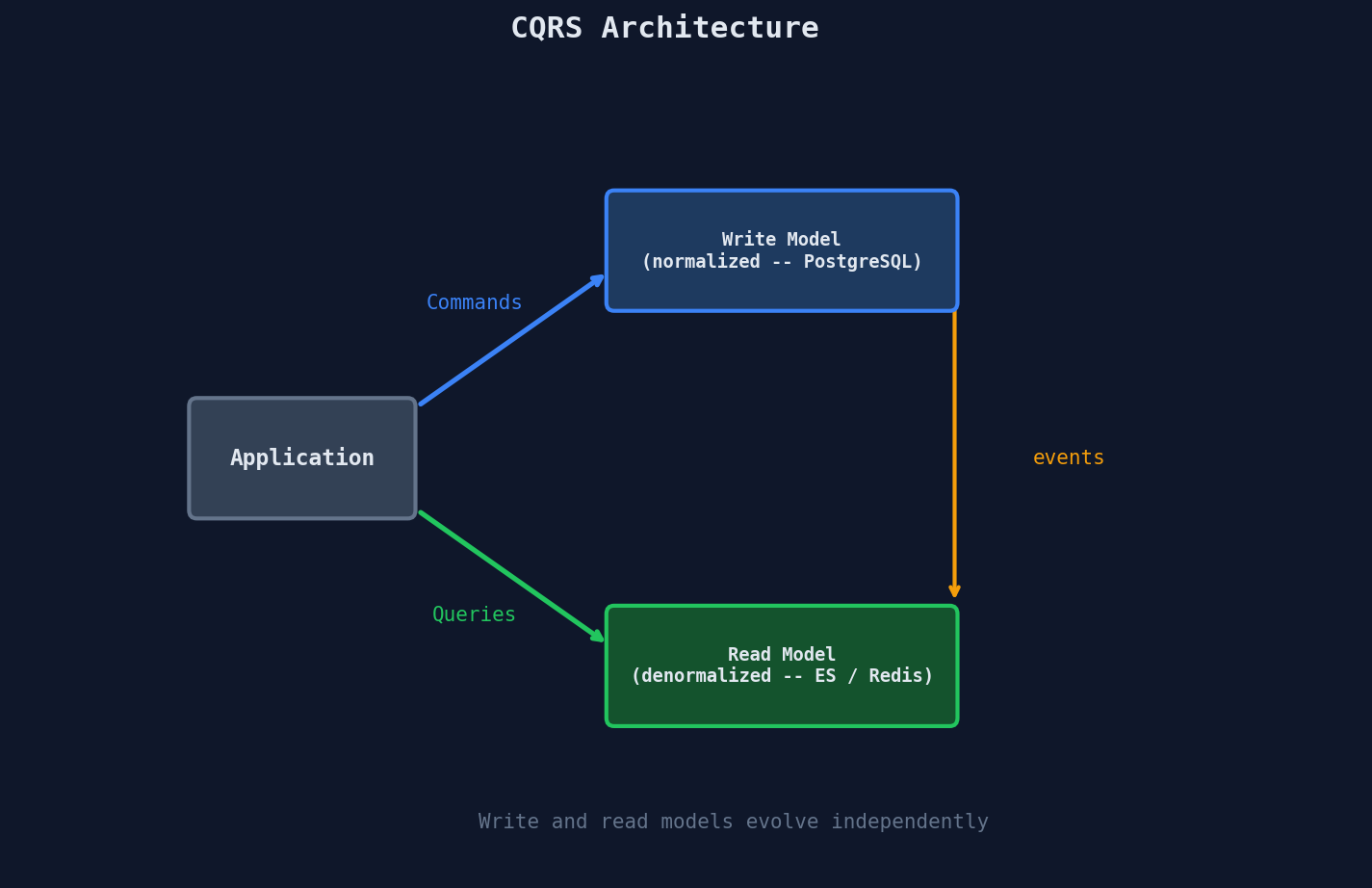
The write model publishes events when data changes. The read model consumes those events and updates its denormalized views. The two models are eventually consistent — there's a small delay between a write and its appearance in the read model.
When CQRS Is Worth It
| Signal | Why CQRS Helps |
|---|---|
| Read/write ratio is wildly skewed (1000:1) | Scale reads independently of writes |
| Read and write schemas are very different | Each model is optimized for its purpose |
| Need to serve different read patterns from same data | Multiple read models for different consumers |
| Need an audit trail | Events provide a natural changelog |
When CQRS Is Overkill
For a simple CRUD application where reads and writes use the same schema, CQRS adds complexity with no benefit. A single PostgreSQL database with read replicas serves most applications perfectly.
Event Sourcing — Store Every Change
Current State vs Event History
Traditional approach: Store current state. When a user updates their name from "Alice" to "Alicia," you overwrite the row. The old value is gone.
Event sourcing: Store every change as an immutable event. Never overwrite.
Event Store:
┌─────┬────────────────┬──────────────────────┬────────────┐
│ seq │ event_type │ payload │ timestamp │
├─────┼────────────────┼──────────────────────┼────────────┤
│ 1 │ AccountCreated │ {id: 1, name: Alice} │ 2024-01-15 │
│ 2 │ NameChanged │ {id: 1, name: Alicia}│ 2024-03-20 │
│ 3 │ EmailChanged │ {id: 1, email: new} │ 2024-03-22 │
│ 4 │ AccountDeleted │ {id: 1} │ 2024-06-01 │
└─────┴────────────────┴──────────────────────┴────────────┘
Current state of account 1 = replay events 1→2→3→4 = deleted
Why This Matters
Complete audit trail: Every change is recorded. Perfect for financial systems, compliance, and debugging ("what happened to this user's account between March 15 and March 20?").
Time travel: Rebuild the state of any entity at any point in time by replaying events up to that timestamp.
Rebuild read models: If you realize your read model needs a different structure, replay all events to build a new one from scratch. No data migration needed.
Decoupled systems: Multiple downstream services can consume the same event stream and build their own views of the data.
The Costs
Complexity: Simple CRUD becomes event design. "Update user" becomes "UserNameChanged event + UserEmailChanged event."
Storage: Events accumulate forever. Snapshotting (periodically saving current state) helps — replay from the latest snapshot, not from the beginning of time.
Eventual consistency: Read models lag behind the event stream. A user changes their name and might see the old name for a second.
Event versioning: When the schema of an event changes, old events in the store still have the old format. You need upcasting or versioned event handlers.
Materialized Views — Pre-Computed Query Results
A materialized view is a query result stored as a table. Instead of computing the result on every read, you compute it once and serve the pre-built result.
PostgreSQL Materialized Views
-- Create a materialized view of daily order totals
CREATE MATERIALIZED VIEW daily_order_totals AS
SELECT
DATE(created_at) AS order_date,
COUNT(*) AS total_orders,
SUM(amount) AS total_revenue
FROM orders
GROUP BY DATE(created_at);
-- Refresh when data changes (or on a schedule)
REFRESH MATERIALIZED VIEW CONCURRENTLY daily_order_totals;
The view is a real table on disk. Queries against it are fast — no aggregation at query time.
CONCURRENTLY refreshes the view without locking reads. Readers see the old data until the refresh completes, then atomically see the new data.
Star Schema and Snowflake Schema
For analytics workloads, materialized views connect to a broader pattern: dimensional modeling.
Star Schema: A central fact table (measurements like order amounts, click counts) surrounded by dimension tables (descriptive data like products, dates, customers). Dimensions are denormalized.
Snowflake Schema: Like star, but dimensions are further normalized into sub-tables (product → category → department). Less redundancy, more joins.
OLTP vs OLAP: Your main application database (OLTP) is optimized for transactions. Analytics databases (OLAP) are optimized for aggregation queries. Star schema lives in the OLAP world — data warehouses like BigQuery, Redshift, Snowflake.
| OLTP | OLAP | |
|---|---|---|
| Purpose | Transactions | Analytics |
| Operations | INSERT, UPDATE, DELETE | SELECT + aggregation |
| Schema | Normalized (3NF) | Denormalized (Star/Snowflake) |
| Example | PostgreSQL, MySQL | BigQuery, Redshift |
Interview Tip
If a system design problem mentions dashboards, analytics, or reporting alongside transactional features — mention CQRS or at least a read replica with materialized views. "The transactional database handles writes, and I'd sync data to a read-optimized store (or materialized views) for the analytics dashboard." That separates you from candidates who try to serve both from one query path.
Putting It All Together
CQRS, event sourcing, and materialized views are often combined:
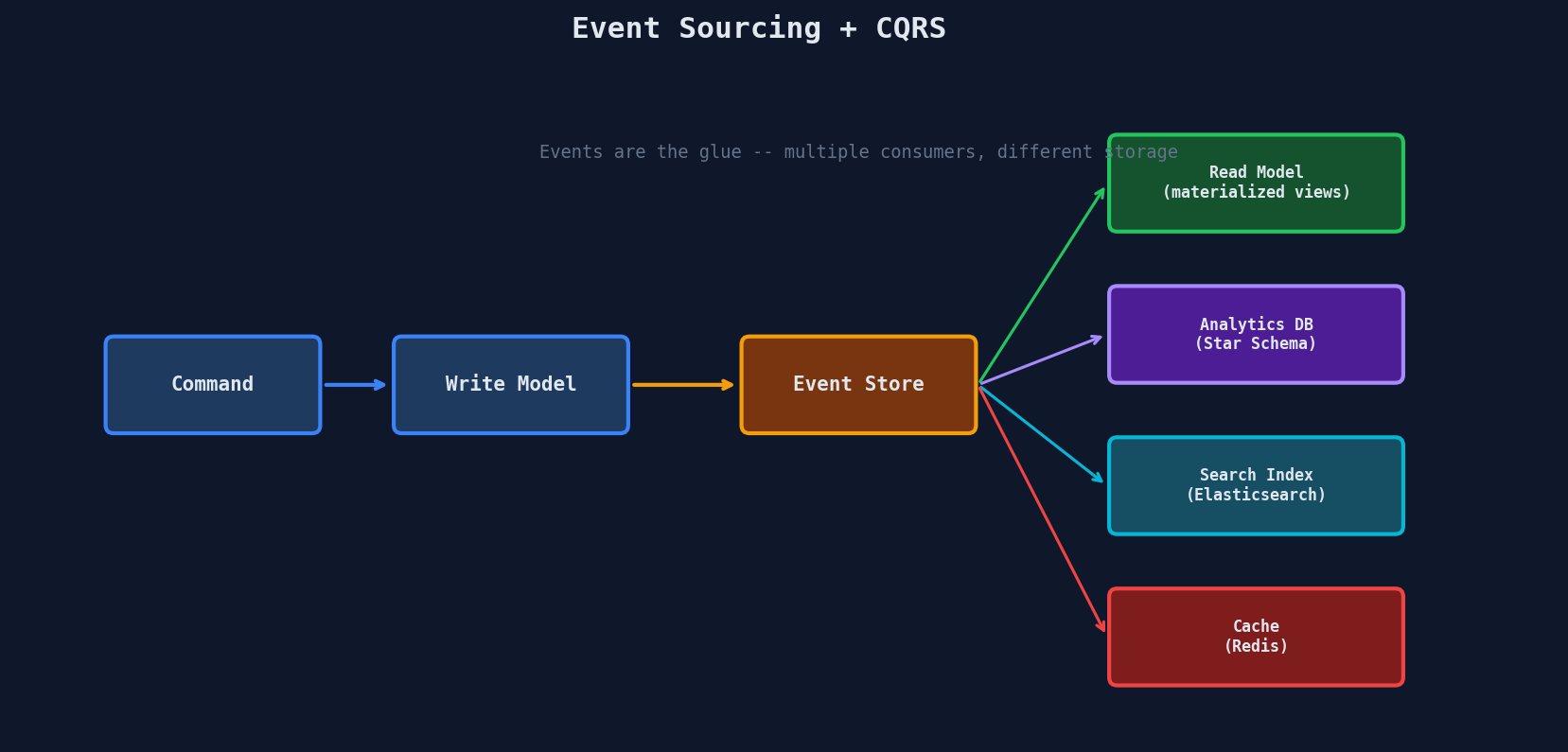
Events are the glue: the write model emits events, and multiple read models consume them to build different views of the same data. Each consumer is independent and can use the storage technology that best fits its query pattern.
Quick Recap
| Pattern | What It Does | Best For | Cost |
|---|---|---|---|
| CQRS | Separate read/write models | Different read/write requirements | Two data stores, eventual consistency |
| Event Sourcing | Store changes, not state | Audit trails, time travel, rebuilding views | Complexity, storage, event versioning |
| Materialized Views | Pre-compute query results | Expensive aggregations, dashboards | Staleness, refresh overhead |
| Star Schema | Fact + dimension tables | Analytics, reporting, data warehouses | OLAP only, not for OLTP |