When to Linearize
You Have Two Tools Now
You've learned two linearizations:
- DFS ordering — each node appears once, subtrees are contiguous segments.
- Euler tour — each node appears multiple times, encodes path/depth information.
Both convert tree problems into array problems. But not every tree problem benefits from linearization. Sometimes a plain DFS is simpler and faster to code. The skill is knowing which tool to reach for — in the first 30 seconds of reading a problem.
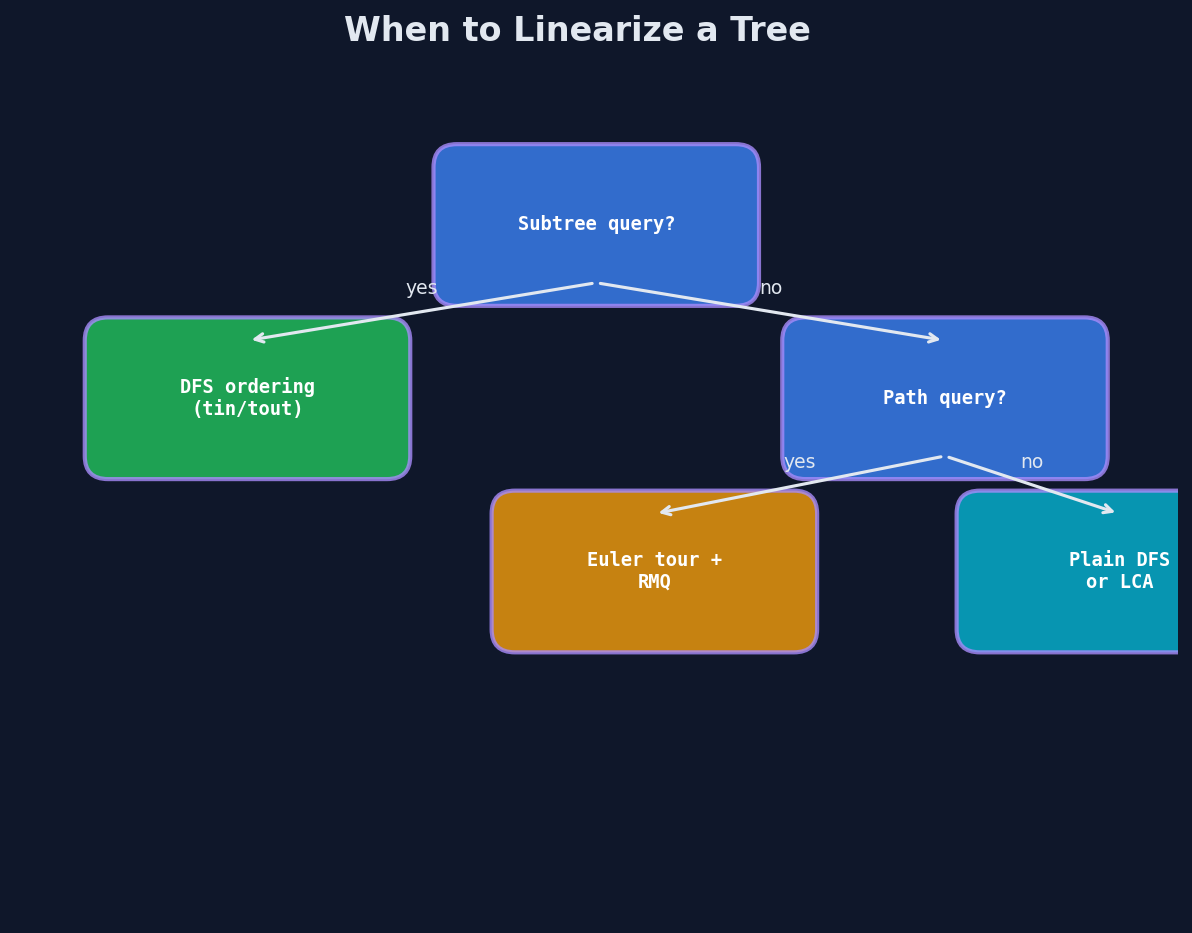
The Decision Framework
Ask these questions in order:
1. Do you need repeated range queries on subtrees?
Sum of values in a subtree, count of nodes satisfying a condition, minimum in a subtree — with updates between queries.
Answer: Linearize with DFS ordering. Map to BIT or segment tree. Covered in Lesson 2.
2. Do you need to check ancestor relationships?
"Is \(u\) an ancestor of \(v\)?" or "find all ancestors of \(v\) satisfying some property."
Answer: DFS ordering gives \(O(1)\) ancestor checks via \(tin/tout\) interval containment. Covered in Lesson 1.
3. Do you need LCA queries?
Lowest Common Ancestor of pairs of nodes, possibly many pairs.
Answer: Euler tour + sparse table for \(O(1)\) per query. Or binary lifting for \(O(\log n)\) per query with \(k\)-th ancestor support. Covered in Lesson 3 and Chapter 12.
4. Do you need range queries on paths (not subtrees)?
Sum along the path from \(u\) to \(v\), or maximum edge weight on a path.
Answer: This needs LCA (to split the path at the LCA) plus either prefix sums (for sum/xor) or Heavy-Light Decomposition (for min/max/arbitrary queries). HLD is Chapter 14.
5. Is it a one-off structural question?
"Find the diameter," "check if the tree is balanced," "count leaves." A single pass suffices.
Answer: Just DFS. Don't linearize. The overhead of building a flat array and a data structure isn't worth it for a single traversal.
Quick Reference Table
| Need | Technique | Complexity |
|---|---|---|
| Subtree sum/min/max with updates | DFS order + BIT/segment tree | \(O(\log n)\) per op |
| Is \(u\) ancestor of \(v\)? | DFS order, \(tin/tout\) check | \(O(1)\) |
| LCA (batch) | Euler tour + sparse table | \(O(1)\) per query |
| LCA (online, also need \(k\)-th ancestor) | Binary lifting | \(O(\log n)\) per query |
| Path sum | LCA + depth prefix sums | \(O(\log n)\) or \(O(1)\) |
| Path min/max with updates | HLD + segment tree | \(O(\log^2 n)\) per op |
| Single structural query | Plain DFS | \(O(n)\) |
Practice: 5 Problems, Decide First
For each problem below, decide whether to linearize before reading the solution approach. Spend 30 seconds, no more.
Problem 1: Given a rooted tree with \(n \leq 2 \times 10^5\) nodes, each with a color. Answer \(q\) queries: "how many distinct colors are in the subtree of node \(v\)?"
Decision: Linearize. DFS ordering makes each subtree a contiguous range. This becomes "count distinct values in a range" — solvable with Mo's algorithm on the flat array, or a DFS-order merge sort tree. You'd never solve this efficiently on the raw tree.
Problem 2: Given a binary tree, return its diameter (longest path between any two nodes).
Decision: Don't linearize. A single postorder DFS computes the diameter in \(O(n)\). Linearization adds complexity for zero benefit.
Problem 3: Given a tree with \(n\) nodes and \(q\) queries, each query gives two nodes \(u, v\). Return the distance (number of edges) between them.
Decision: Linearize. Distance = \(depth[u] + depth[v] - 2 \cdot depth[LCA(u,v)]\). You need LCA for each query. Euler tour + sparse table gives \(O(1)\) per query after \(O(n \log n)\) preprocessing.
Problem 4: Given a tree, find the sum of all pairwise distances. No queries, just one answer.
Decision: Don't linearize. A single DFS using subtree sizes computes the contribution of each edge: edge \((u, parent)\) contributes \(subtreeSize[u] \times (n - subtreeSize[u])\) to the total. One pass, \(O(n)\).
Problem 5: Given a tree with values on nodes. Support two operations: (a) add \(x\) to all nodes in the subtree of \(v\), (b) query the value of node \(v\).
Decision: Linearize. "Add \(x\) to all positions in \([tin[v], tout[v]]\)" is a range update. "Query value at \(tin[v]\)" is a point query. A BIT with range-update/point-query mode handles this in \(O(\log n)\) per operation.
The Meta-Insight
Linearization is a reduction. You're not inventing a new data structure for trees. You're converting a tree problem into an array problem, then using powerful array tools that have been optimized for decades.
The hardest part isn't implementing the BIT or the sparse table. It's recognizing that the tree problem you're staring at IS an array problem in disguise. That recognition comes from this decision framework, applied repeatedly until it becomes instinct.
When you see "subtree" in a problem statement, your first thought should be: that's a contiguous range. When you see "path between two nodes," your first thought should be: I need LCA to split it. When you see "ancestor," think interval containment.
The tree is the surface. The array is the engine.
Try It
Challenge: Here's a problem you haven't seen: "Given a rooted tree, support two operations: (a) toggle the color of node \(v\) between black and white, (b) find the closest black ancestor of node \(v\)." Does linearization help?
Think about it. Linearization gives you subtree ranges and ancestor checks, but "closest black ancestor" requires walking up the tree. You could use a set of black nodes sorted by DFS entry time and do a predecessor query — that IS a linearization approach. But binary lifting with some bookkeeping might be simpler. Both work. The point is: you considered linearization first, decided whether it fits, and made a reasoned choice. That's the skill.
Edge Cases to Watch For
- Mixed query types (subtree + path): May need both DFS ordering (for subtree) and LCA (for path) simultaneously. If you only precompute one, the other query type fails silently or requires a separate pass.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| CSES — Subtree Queries | cses.fi/problemset/task/1137 | Medium |
| CSES — Path Queries | cses.fi/problemset/task/1138 | Medium |
| CSES — Distance Queries | cses.fi/problemset/task/1135 | Medium |
| CF 343D — Water Tree | codeforces.com/problemset/problem/343/D | Hard |
| CF 600E — Lomsat gelral | codeforces.com/problemset/problem/600/E | Hard |
| CF 620E — New Year Tree | codeforces.com/problemset/problem/620/E | Hard |
| CF 877E — Danil and Part-time Job | codeforces.com/problemset/problem/877/E | Medium |
What's Next?
Linearization turns subtree queries into range queries. But path queries need something more: a way to find where two paths meet. Chapter 12 teaches LCA -- the most reusable primitive in all of tree algorithms.