Why Writes Are Harder
TL;DR
Reads can be cached, replicated, and CDN'd — you can serve a read from anywhere that has a copy. Writes must touch the source of truth. Every write goes through the primary database, gets validated, updates indexes, replicates to followers, and flushes to disk. You can't shortcut any of that. That's why writes are fundamentally harder to scale.
Reads Are Easy. Writes Are Not.
In the last chapter, we scaled reads by throwing copies at the problem. Read replicas, caches, CDNs — all of these work because a read doesn't change anything. You can serve a read from any copy, anywhere in the world. Stale by a few seconds? Usually fine.
Writes don't get that luxury.
A write must go to one place: the primary database. It must be validated. It must be durable. It must be replicated. There's no shortcut, no caching trick, no CDN that can absorb a write for you.
Reads vs Writes — The Fundamental Asymmetry
┌─────────────────────────┬──────────────────────────────┐
│ What You Can Do │ Reads │ Writes │
├─────────────────────────┼────────────────┼─────────────┤
│ Serve from cache │ ✅ Yes │ ❌ No │
│ Serve from replica │ ✅ Yes │ ❌ No │
│ Serve from CDN │ ✅ Yes │ ❌ No │
│ Tolerate stale data │ ✅ Usually │ ❌ Never │
│ Parallelize freely │ ✅ Yes │ ⚠️ Limited │
│ Retry safely │ ✅ Always │ ⚠️ Risky │
│ Must touch primary DB │ ❌ Not always │ ✅ Always │
│ Must acquire locks │ ❌ Rarely │ ✅ Usually │
│ Must update indexes │ ❌ No │ ✅ Every one│
│ Must fsync to disk │ ❌ No │ ✅ Yes │
└─────────────────────────┴────────────────┴─────────────┘
Think of it this way: reading a book — anyone can read any copy. A million people can read the same book simultaneously, from a million different copies, in a million different locations. Writing a book — only one person holds the pen, and every edit must be published to every copy before readers see it.
That asymmetry shapes everything about how write-heavy systems are designed.
The Write Path — What Actually Happens When You INSERT a Row
When your application fires a simple INSERT INTO orders (user_id, amount) VALUES (42, 99.99), here's what the database actually does:
Step 1 → Connection accepted from pool
Step 2 → Query parsed and validated (syntax, permissions)
Step 3 → Transaction started, row-level locks acquired
Step 4 → Data written to Write-Ahead Log (WAL) — sequential disk write
Step 5 → Data written to in-memory buffer (B-tree page or memtable)
Step 6 → Indexes updated (EVERY index on the table)
Step 7 → Constraints checked (foreign keys, uniqueness, NOT NULL)
Step 8 → WAL flushed to disk (fsync) — THE SLOW PART
Step 9 → WAL streamed to replicas (replication)
Step 10 → Transaction committed, locks released
That's ten steps for a single INSERT. Let's trace this as a sequence diagram:
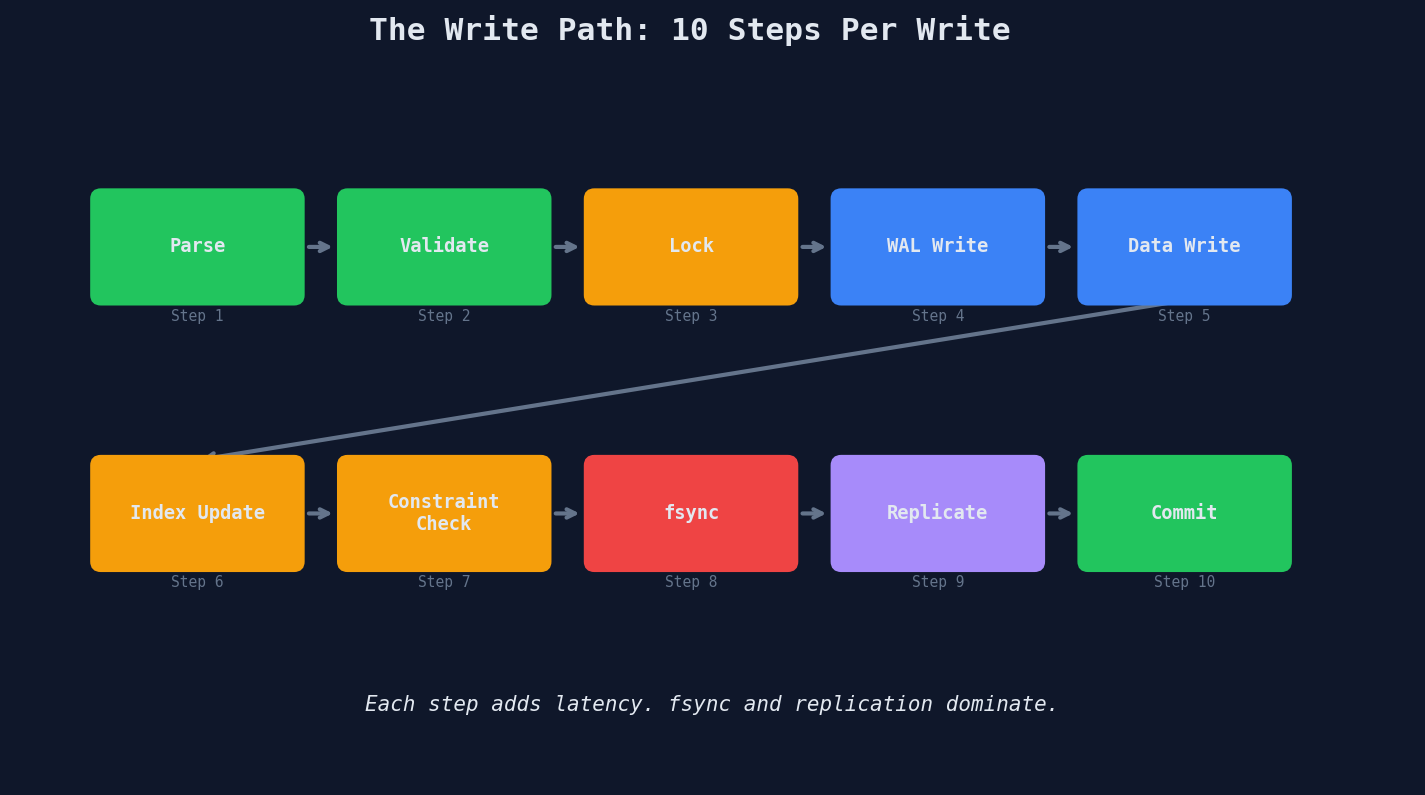
The critical insight: a single INSERT touches the WAL, data pages in the buffer pool, every index on the table, and triggers replication. A read touches none of those — it just reads a page from the buffer pool (or disk if it's not cached). That's why writes are 5-10x more expensive than reads on the same hardware.
The fsync Tax
Step 8 — the fsync — is where writes hit a wall. An fsync forces the operating system to flush data from its write buffer to physical disk. The OS can't lie about it. The database waits until the disk confirms "yes, your data is safe." On an SSD, a single fsync takes 0.1-0.5 ms. That sounds fast until you're doing 10,000 of them per second — that's your entire write budget consumed by disk flushes alone.
The Tension — Every Read Optimization Makes Writes Harder
Here's what makes database design genuinely difficult: the things you do to speed up reads actively slow down writes.
| Optimization | Read Performance | Write Performance | Why |
|---|---|---|---|
| Add an index | + Faster lookups | - Must update index on every write | Each index = 1 extra write per INSERT |
| Add a read replica | + Spread read load | = No help (writes still go to primary) | Replication adds overhead to primary |
| Denormalize data | + Fewer JOINs needed | - Must update multiple locations | One logical write becomes 2-5 physical writes |
| Strong consistency | = Reads always fresh | - Must wait for replica ACK | Write latency includes replication round-trip |
| Materialized view | + Pre-computed results | - Must refresh on every write | Maintaining the view costs write throughput |
This is the fundamental tension in database design. You can't escape it. You can only choose where you want the pain.
A table with 5 indexes means every INSERT does 6 writes — one for the data, one for each index. A table with 10 indexes does 11 writes. Production tables at large companies commonly have 8-15 indexes. That's why a seemingly simple INSERT can take 10x longer than you'd expect.
Interview Tip
If an interviewer asks "how would you optimize this write-heavy system?" and the schema has 12 indexes, your first answer should be "audit the indexes." Dropping unused indexes is the cheapest write optimization that exists. Every removed index is a free write throughput boost.
Write Throughput — The Hard Numbers
Different databases achieve wildly different write throughput. The reason isn't magic — it's what they sacrifice.
Write Throughput by Database (single node, commodity hardware)
┌────────────────────┬──────────────────┬─────────────────────────────────────┐
│ Database │ Writes/sec │ Why │
├────────────────────┼──────────────────┼─────────────────────────────────────┤
│ PostgreSQL │ 5K – 20K │ B-tree, MVCC overhead, fsync │
│ MySQL (InnoDB) │ 5K – 15K │ Similar to Postgres │
│ Cassandra │ 10K – 50K │ LSM tree, append-only, no read- │
│ │ │ before-write │
│ Redis │ 100K – 200K │ In-memory, no fsync by default │
│ Kafka │ 500K – 700K │ Sequential append-only log, │
│ │ │ zero-copy │
└────────────────────┴──────────────────┴─────────────────────────────────────┘
Notice the pattern. The databases that write fastest are the ones that sacrifice read features:
- Cassandra sacrifices flexible reads — no JOINs, limited query patterns, read performance suffers from LSM compaction
- Redis sacrifices durability — data lives in RAM, an unexpected crash can lose the last few seconds of writes
- Kafka sacrifices random access — you can only append to and read sequentially from a topic, no point lookups
PostgreSQL and MySQL write slowly because they maintain B-tree indexes, enforce ACID transactions, and fsync every commit. Those features are what make reads fast and data reliable. The write cost is the price you pay.
The Physical Ceiling — Disk I/O
Every durable write eventually hits disk. And disk speed is the ultimate ceiling.
| Storage Type | Sequential Write | Random Write | Writes/sec (4KB blocks) |
|---|---|---|---|
| HDD (spinning) | 100-200 MB/s | 1-5 MB/s | 250-1,250 |
| SSD (NVMe) | 500-600 MB/s | 50-100 MB/s | 12,500-25,000 |
| RAM | ~10 GB/s | ~10 GB/s | ~2,500,000 |
This table explains everything:
Kafka's genius: it only does sequential writes. Append to the end of a log file, one after another. That's why it matches raw SSD throughput — it's doing exactly what the hardware is optimized for.
PostgreSQL's constraint: B-tree indexes require random writes. Updating an index means finding the right page in the tree and modifying it in place. On an HDD, that's 200x slower than sequential writes. Even on an SSD, it's 5-10x slower.
Kafka Write Pattern (Sequential)
┌──────────────────────────────────────────┐
│ msg1 │ msg2 │ msg3 │ msg4 │ msg5 │ ───► │
└──────────────────────────────────────────┘
Just keep appending. Disk loves this.
PostgreSQL Write Pattern (Random)
┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐
│Page 7│ │Page 2│ │Page 9│ │Page 4│
│ WRITE│ │ WRITE│ │ WRITE│ │ WRITE│
└──────┘ └──────┘ └──────┘ └──────┘
Jump around the disk. Disk hates this.
Don't Blame the Database
PostgreSQL isn't slow because it's badly written. It's slow at writes because it gives you ACID transactions, rich indexing, and flexible queries. Kafka is fast at writes because it gives you almost none of that. There's no free lunch — only trade-offs you choose.
Proof Points — Real-World Scale
These aren't theoretical problems. The biggest systems in the world wrestle with write throughput daily:
Uber ingests roughly 1 million GPS location updates per second across their global fleet. Each driver's phone pings their location every 4 seconds. That's a write-heavy workload that no single database can handle — it requires purpose-built ingestion pipelines.
Kafka handles 500K+ messages per second per broker via sequential disk writes. LinkedIn runs over 7 trillion messages per day through their Kafka clusters — possible only because Kafka treats writes as sequential appends.
Discord processes 120M+ messages per day. When their message volume overwhelmed Cassandra's compaction process (a write amplification problem), they had to migrate their message storage to ScyllaDB — a rewrite driven entirely by write-path bottlenecks.
What's Coming Next
Now that you understand why writes are hard, the rest of this chapter is about what to do about it:
| Lesson | Strategy | Core Idea |
|---|---|---|
| Lesson 2 | Optimize your database | Tune WAL, batch commits, audit indexes — squeeze more from one machine |
| Lesson 3 | Sharding | Split writes across multiple machines by partitioning data |
| Lesson 4 | Buffering and batching | Absorb write spikes with queues, batch multiple writes into one |
| Lesson 5 | Conflict-free writes | CRDTs and sharded counters — avoid coordination entirely |
Each lesson builds on this foundation. The write path we traced above? Every optimization strategy in this chapter targets a specific step in that path — making it faster, skipping it, or distributing it across machines.
Quick Recap
| Concept | Key Takeaway |
|---|---|
| The asymmetry | Reads can be served from anywhere. Writes must go to the primary. |
| The write path | A single INSERT touches WAL + data page + every index + replication |
| The tension | Read optimizations (indexes, denormalization) make writes slower |
| The physical ceiling | Sequential writes (Kafka) are 5-200x faster than random writes (B-trees) |
| The trade-off | Fast-write databases sacrifice read flexibility or durability |
| Write throughput | PostgreSQL: 5-20K/s. Kafka: 500K+/s. The gap is architectural. |
Interview Tip
When an interviewer says "this system needs to handle millions of writes per second," your first question should be: "Are these writes to the same data (contention) or to different data (throughput)?" The answer completely changes your architecture. Contention means you need conflict resolution (CRDTs, last-write-wins, sharded counters). Throughput means you need horizontal partitioning (sharding, Kafka topics). Conflating the two is the most common mistake candidates make.