Interview Cheat Sheet
TL;DR
Every key decision, comparison table, and interview phrase from the entire Data Modelling module — consolidated into one page. Review this the night before your interview.
Database Selection Flowchart
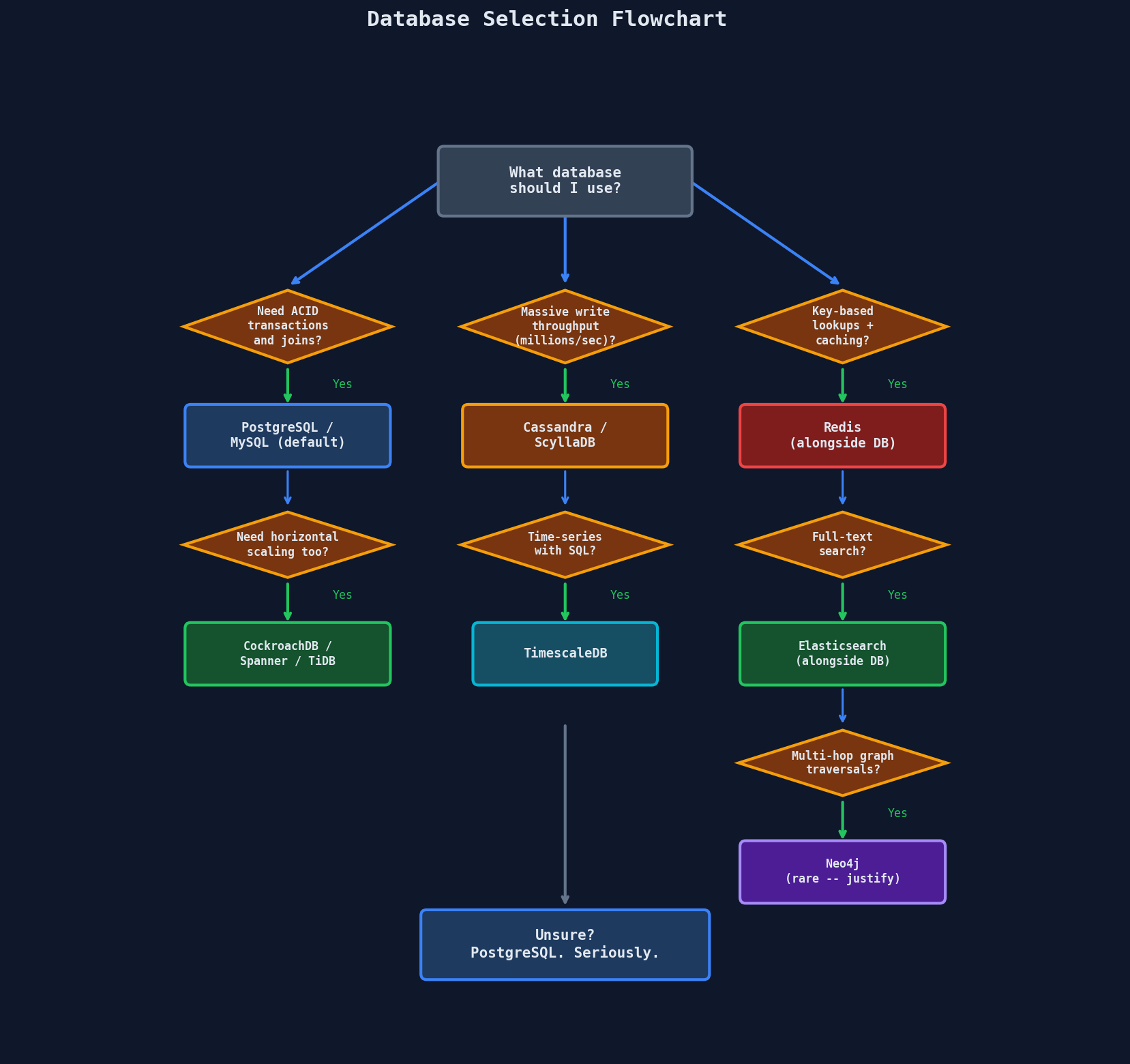
Key phrase: "I'll default to PostgreSQL unless a specific access pattern demands otherwise."
Schema Design Checklist
- List core entities (nouns from requirements)
- Define primary keys (UUID or Snowflake ID for distributed systems)
- Draw relationships (1:N → FK on "many" side, M:N → junction table)
- Identify hot read paths → these drive indexing and denormalization
- Normalize to 3NF, then denormalize strategically for hot paths
Key phrase: "I'll start with a normalized schema and denormalize only where the primary access pattern demands it."
Normalization vs Denormalization
| Normalize | Denormalize | |
|---|---|---|
| Optimize for | Writes, consistency | Reads, speed |
| Data redundancy | None | Intentional duplication |
| Update cost | Change once | Change in multiple places |
| Best when | Data changes frequently | Data is read-heavy and rarely changes |
Indexing Decision Tree
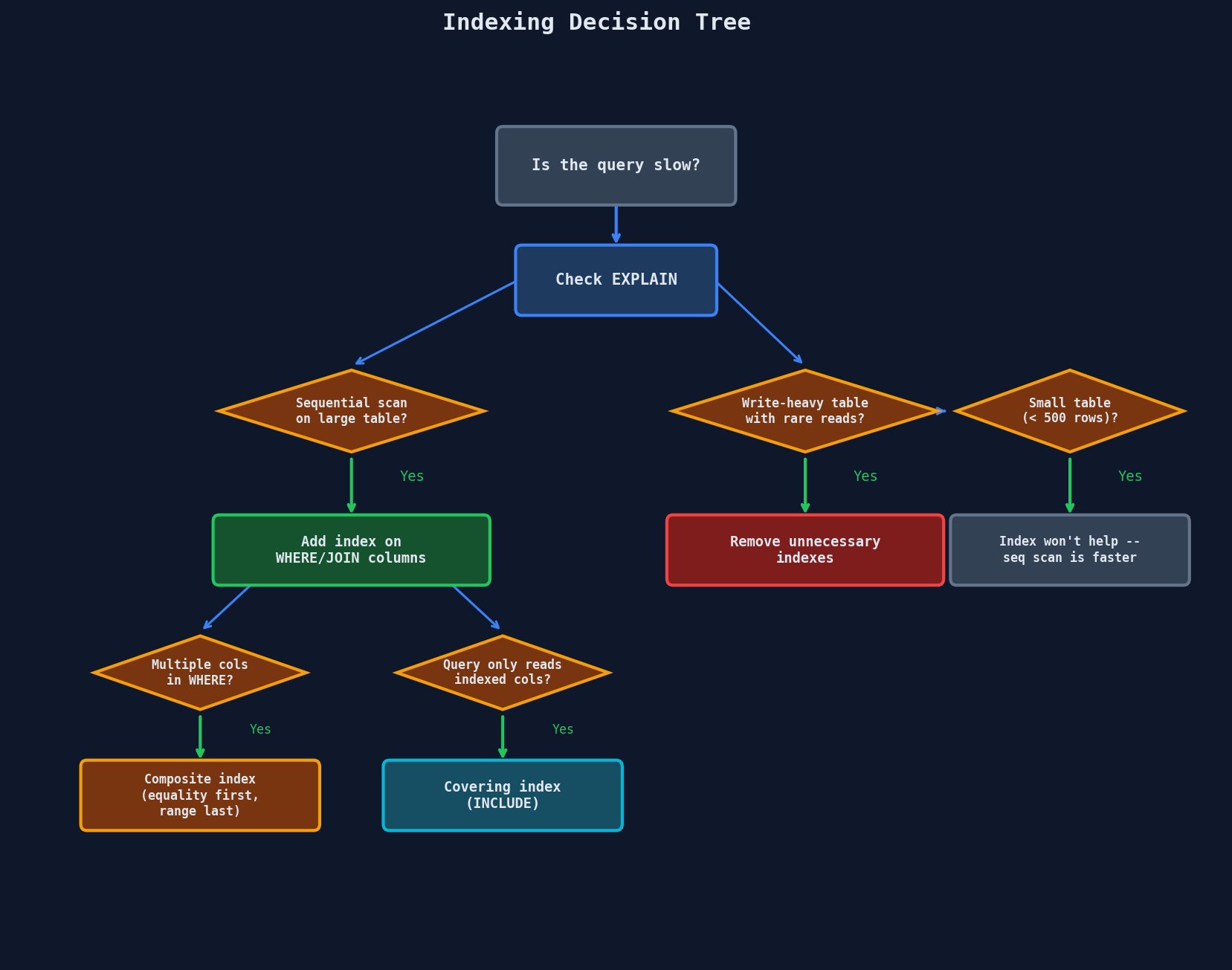
Key phrase: "I'll add an index on (user_id, created_at) since the primary query is fetching a user's recent posts."
The Scaling Ladder
Before sharding, exhaust every simpler option:
| # | Step | What it solves |
|---|---|---|
| 1 | Indexing | Solves 80% of performance problems |
| 2 | Read Replicas | Handle read-heavy traffic |
| 3 | Connection Pooling | PgBouncer for database protection |
| 4 | Caching (Redis) | Hot data and computed results |
| 5 | Partitioning | Split large tables within one database |
| 6 | Sharding | Split across multiple databases (last resort) |
| 7 | NewSQL | CockroachDB / Spanner (automatic sharding) |
Go top-to-bottom. Most apps never need to go past step 4.
Key phrase: "I'd exhaust simpler options first — indexes, replicas, caching — before introducing the complexity of sharding."
Sharding Quick Reference
| Strategy | How | Best For | Watch Out |
|---|---|---|---|
| Hash-based | shard = hash(key) % N |
Even distribution | Resharding moves most keys (use consistent hashing) |
| Range-based | Key ranges per shard | Time-series, multi-tenant | Hotspots on active ranges |
| Directory-based | Lookup table | Maximum flexibility | SPOF, lookup latency |
Good shard keys: user_id, tenant_id, order_id (high cardinality, even distribution, query-aligned)
Bad shard keys: boolean, timestamp (hot partition), low-cardinality enum
Key phrase: "I'd shard by user_id using hash-based sharding with consistent hashing to minimize data movement during resharding."
Replication Models
| Model | Writes | Consistency | Best For |
|---|---|---|---|
| Leader-follower | Leader only | Strong (leader), eventual (followers) | Most applications — the default |
| Multi-leader | Any leader | Eventual (conflict resolution) | Multi-region writes, offline-first apps |
| Leaderless (quorum) | Any node (W nodes) | Tunable (W+R>N for strong) | High write availability, no SPOF |
Quorum formula: W + R > N — ensures at least one overlapping node between read and write sets.
Key phrase: "I'd use leader-follower replication with async followers for read scaling, and route the user's own reads to the leader for read-after-write consistency."
Concurrency Control
| Technique | When | How |
|---|---|---|
| SELECT FOR UPDATE | High contention (last ticket) | Lock rows before reading — second transaction waits |
| Optimistic locking (version) | Low contention (profile edits) | Check version at write time, retry on conflict |
| MVCC / Snapshot isolation | Long-running reads | Multiple row versions, readers don't block writers |
| Serializable isolation | Must prevent all race conditions | Strongest but slowest — use for financial transactions |
Key phrase: "For the double-booking problem, I'd use SELECT FOR UPDATE to lock the row. For low-contention updates, optimistic locking with a version column."
Consistency Models
| Model | Guarantee | Use When | Example |
|---|---|---|---|
| Strong | All reads see latest write | Money, tickets, inventory | Spanner, single-leader PostgreSQL |
| Causal | Related events in order | Comments after posts | Some CRDTs |
| Read-your-writes | You see your own updates | Profile changes | Read from primary after write |
| Eventual | All replicas converge over time | Social feeds, DNS, CDN | Cassandra, DynamoDB (default) |
Key phrase: "Would inconsistent data be catastrophic? If yes, strong consistency. If no, eventual consistency with read-your-writes for the user's own data."
Distributed Transaction Patterns
| Pattern | How | When | Cost |
|---|---|---|---|
| 2PC | Coordinator: prepare → commit | Single database, multi-statement | Blocking, slow |
| Saga | Sequence of local transactions + compensating actions | Microservices, cross-service operations | Complexity, eventual consistency |
| Outbox | Write event to outbox table in same transaction | Reliable event publishing | Extra table, CDC/polling |
Key phrase: "I'd use the Saga pattern with compensating transactions — if payment fails, reverse the inventory reservation."
Query Performance Patterns
| Problem | Symptom | Fix |
|---|---|---|
| N+1 queries | N+1 DB round trips per page | JOIN or batch with WHERE IN |
| Offset pagination | Slow at high page numbers | Cursor-based (WHERE id < last_seen) |
| COUNT(*) at scale | Slow aggregation on millions of rows | Pre-computed counter on the entity |
| Connection exhaustion | "too many connections" | PgBouncer + HikariCP |
Real-World Reference
| Company | Database | Key Pattern | Scale |
|---|---|---|---|
| Facebook TAO | Sharded MySQL + cache | Graph model on relational storage | Billions reads/sec |
| Redis timelines | Hybrid fan-out (push < 10K, pull for celebrities) | 105TB Redis, 39M QPS | |
| Discord | ScyllaDB + Rust data services | Request coalescing for hot partitions | Trillions of messages |
| Slack | MySQL + Vitess | Transparent sharding by workspace | 2.3M QPS |
| Uber | Schemaless (MySQL) | Append-only 3D hash map | Mission-critical trip data |
| Stripe | DocDB (custom) | 6-step reversible migration | 5M QPS, 99.999% uptime |
| Shopify | MySQL pods | Tenant isolation, Ghostferry migration | Black Friday scale |
Capacity Estimation — Byte Sizes
Back-of-envelope math is expected in interviews. Memorize these:
| Data Type | Size | Example |
|---|---|---|
| Boolean | 1 byte | is_active |
| Integer (32-bit) | 4 bytes | user_id (up to ~2B) |
| BigInt (64-bit) | 8 bytes | Snowflake ID, timestamps |
| UUID | 16 bytes | 550e8400-e29b-... |
| VARCHAR(255) | 1-255 bytes | username, email |
| Text (avg tweet) | ~300 bytes | 280 chars UTF-8 |
| JSON document (small) | ~1 KB | API response, user profile |
| Typical DB row | ~0.5-2 KB | user row with 8-10 columns |
| Image thumbnail | ~20 KB | 200x200 JPEG |
| Image (full) | ~2 MB | 1080p photo |
| 1 minute of video | ~10 MB | 720p compressed |
Quick estimation formulas:
| Question | Formula |
|---|---|
| Storage for 1B users | 1B x 1KB/row = 1 TB |
| Storage for 500M tweets/day x 1 year | 500M x 365 x 300B = ~55 TB |
| QPS from 100M DAU | 100M users x ~10 requests/day / 86,400 sec = ~12K QPS |
| Peak QPS | Average QPS x 3 = ~36K QPS |
Key phrase: "Let me do a quick capacity estimate — at 1KB per row and 100M users, we're looking at ~100GB of user data, which fits comfortably on a single PostgreSQL instance."
Red Flags — What Never to Say
Interview Anti-Patterns
- "Let's shard it" as your first scaling answer — exhaust indexes, replicas, pooling, and caching first
- "I'll use MongoDB because it's more flexible" — without a specific access pattern justifying it, this signals cargo-culting
- "We need strong consistency everywhere" — shows you don't understand the cost; map consistency per feature
- "I'll use a graph database for the social network" — even Facebook uses sharded MySQL; a
followstable with indexes is the right answer - "UUIDv4 for all primary keys" — random UUIDs destroy B-tree performance; mention UUIDv7 or Snowflake IDs instead
- "Let me add an index on every column" — each index slows writes; index based on query patterns, not schema
Baseline Architecture — The Safe Default
When you blank on where to start, draw this:
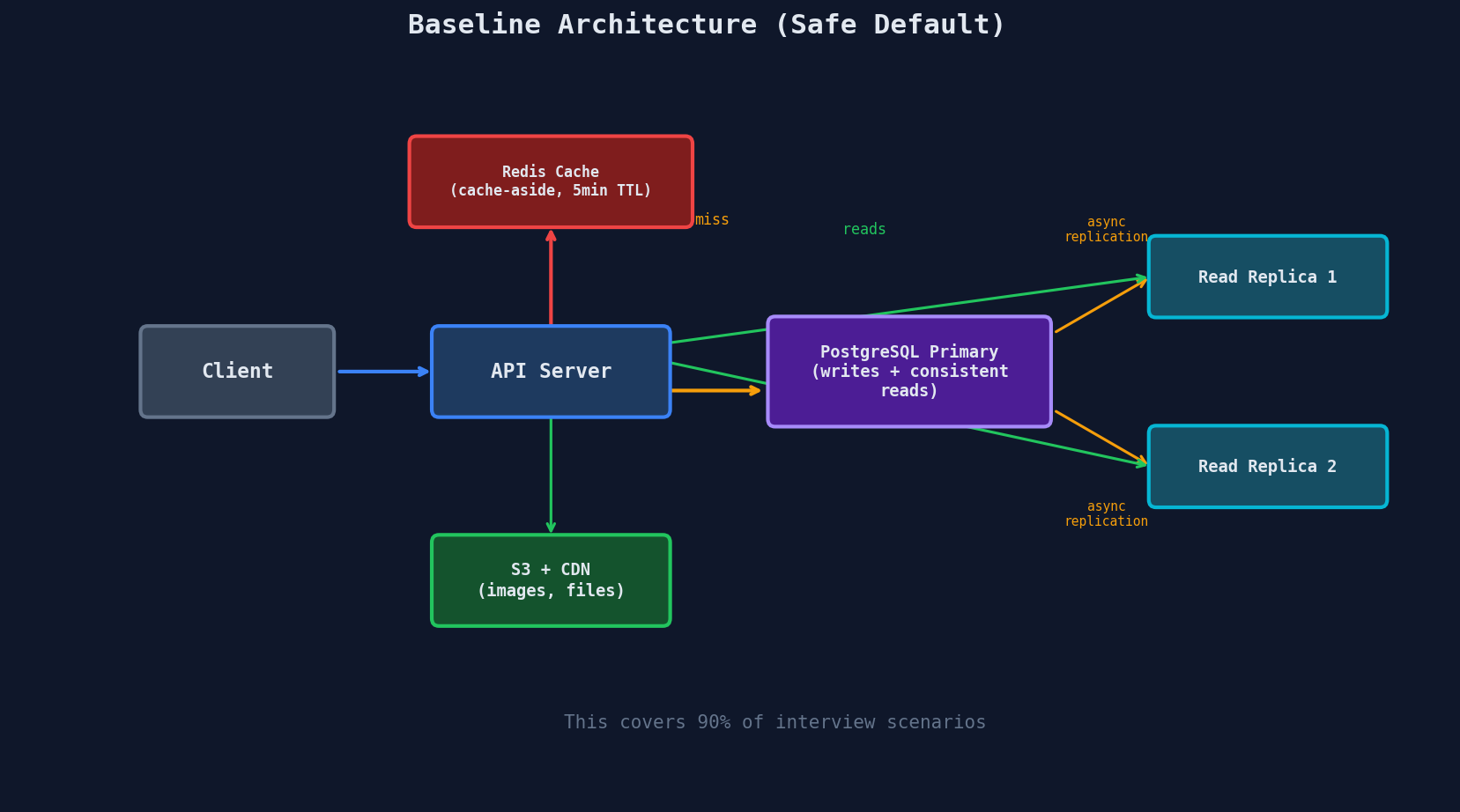
This covers 90% of interview scenarios. Add Elasticsearch for search, Kafka for async events, or sharding only when the interviewer pushes you there.
The Five Things to Say in Every Data Modelling Discussion
- "The core entities are X, Y, Z — each maps to a table." (Shows structured thinking)
- "I'll default to PostgreSQL unless a specific access pattern demands otherwise." (Shows pragmatism)
- "I'll index on (col_a, col_b) since the primary query filters on both." (Shows performance awareness)
- "I'll denormalize X on the Y table to avoid a join on the hot path." (Shows trade-off awareness)
- "Before sharding, I'd try indexes, replicas, and caching first." (Shows maturity)