Retries & Idempotency
TL;DR
Networks fail. When they do, you retry. But naive retries can make things worse — imagine a struggling server getting hammered by thousands of "try again" requests. Exponential backoff gives it breathing room. And for operations where "doing it twice" is dangerous (like charging a credit card), idempotency keys make retries safe.
The Uncomfortable Truth About Networks
Here's something you need to accept about distributed systems: the network will fail. Not might. Will.
Cables get cut. Routers go down. Packets vanish into the void. A server that was perfectly healthy 10 seconds ago is suddenly unreachable. And the scariest part? Sometimes you send a request and get no response at all — you don't know if the server got your message, processed it, and the response got lost... or if the message never arrived.
The idea that "the network is reliable" is one of the most dangerous assumptions in software engineering. Robust system design means planning for failures, not hoping they won't happen.
Step 1: Timeouts — "I'm Not Waiting Forever"
The most basic defense: set a deadline.
Every network call should have a timeout. If the response doesn't arrive within that window, assume something went wrong. It's like waiting for a friend at a coffee shop — if they're not there in 15 minutes, you assume they're not coming and make a new plan.
Without timeouts, a single slow server can tie up your entire system. Threads sit there waiting... and waiting... and your application grinds to a halt.
Step 2: Retries — "Let Me Try That Again"
If a request times out, try again. This handles transient failures — a momentary network hiccup, a server that was briefly overloaded, a packet that got dropped. The retry hits a different server (if you have multiple) or the same server after it recovers.
Sounds simple. But here's where most people get it wrong...
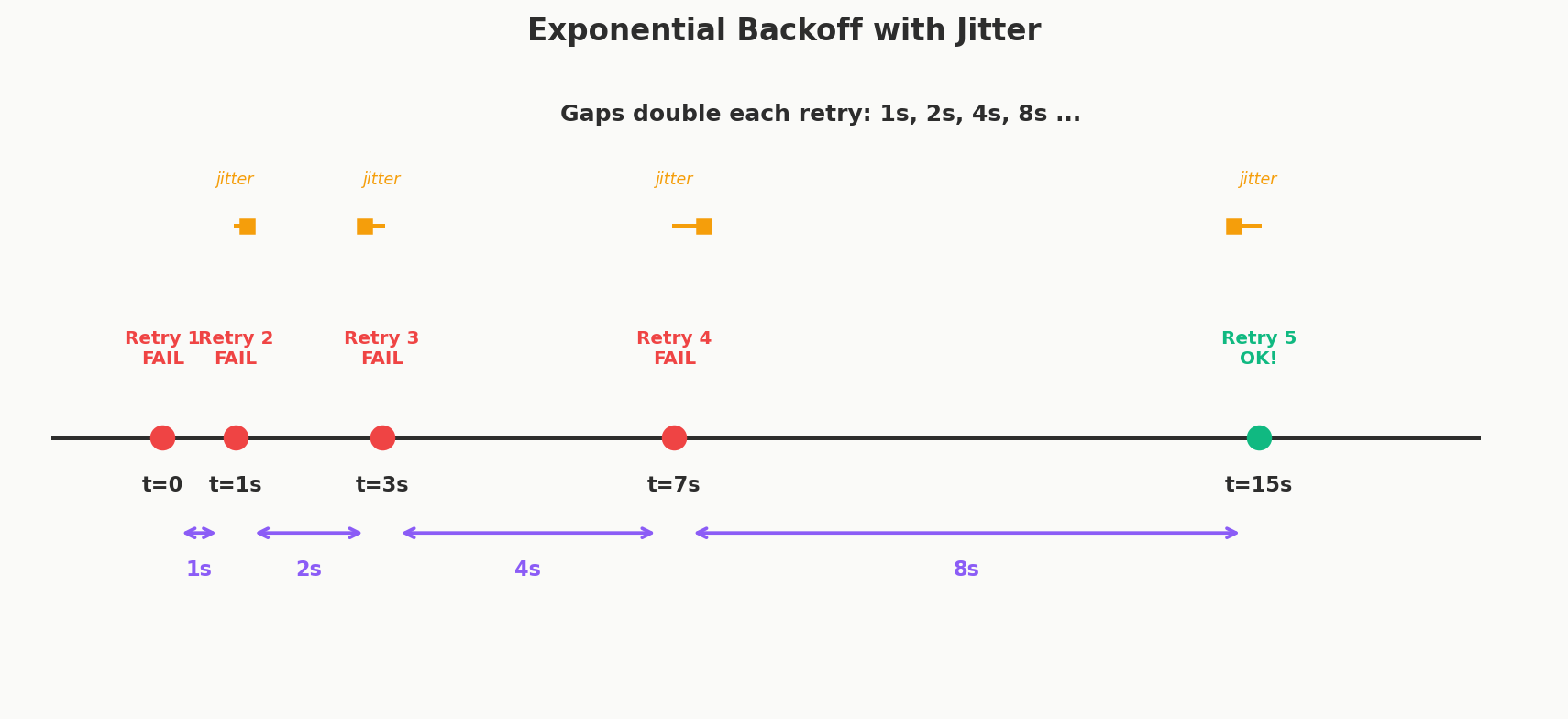
Step 3: Exponential Backoff — "Give It Some Breathing Room"
Imagine a server that's struggling under heavy load. Requests start timing out. Every client retries immediately. Now the server gets hit with double the traffic — the original requests plus all the retries. It falls further behind. More timeouts, more retries, more traffic. Congratulations — you've turned a slow server into a dead server.
This is called a retry storm, and it's like a crowd pushing harder against a jammed door. The door can't open because everyone's pushing.
Exponential backoff breaks the cycle by waiting longer between each retry:
- 1st retry: wait 1 second
- 2nd retry: wait 2 seconds
- 3rd retry: wait 4 seconds
- 4th retry: wait 8 seconds
You're giving the struggling server room to breathe. The longer it's down, the more space you give it to recover.
Jitter — The Final Ingredient
There's one more problem. If a thousand clients all started their requests at the same time and they all fail, exponential backoff means they'll all retry at 1 second, then all at 2 seconds, then 4 seconds... They're still synchronized, hitting the server in waves.
Jitter adds randomness to the wait time. Instead of everyone retrying at exactly 4 seconds, one client waits 3.2 seconds, another waits 4.7, another waits 3.9. This spreads the retries out and prevents synchronized waves of traffic.
Think of it like a traffic light turning green at a busy intersection. If every car starts moving at the exact same instant, you get gridlock. But since each driver has slightly different reaction times, traffic flows smoothly.
Advanced Deep Dive: Thundering Herd vs. Retry Storm — They Sound Similar But Aren't
These two failure modes get confused in interviews, but they have different causes and different fixes:
Retry Storm — A server is slow or failing, so clients retry their failed requests. Each retry adds load, making the server slower, causing more timeouts, causing more retries. It's a feedback loop caused by retries of failed requests.
Thundering Herd — A shared resource suddenly becomes available (e.g., a cache expires, a server restarts, a rate-limit window resets), and all waiting clients rush it simultaneously. Nobody failed — they're all sending legitimate first requests at the exact same moment.
The classic thundering herd example: a popular cache key expires. Thousands of requests that were being served from cache now all hit the database at once. The fix isn't backoff (these aren't retries) — it's cache stampede prevention: lock so only one request rebuilds the cache while others wait, or use staggered TTLs so keys don't all expire simultaneously.
Retry storm fix: exponential backoff + jitter + circuit breakers. Thundering herd fix: request coalescing, staggered expiration, cache locking.
In an interview, if you conflate these two, it signals you've memorized terms without understanding mechanisms. If you cleanly distinguish them, it signals real distributed systems experience.
Here's what this looks like in code:
import random, time
def retry_with_backoff(func, max_retries=5):
for attempt in range(max_retries):
try:
return func()
except Exception:
if attempt == max_retries - 1:
raise
wait = (2 ** attempt) + random.uniform(0, 1) # backoff + jitter
time.sleep(wait)
Five lines. That's all it takes to implement retry with exponential backoff and jitter. The 2 ** attempt doubles the wait each time. The random.uniform(0, 1) adds jitter so clients don't retry in sync.
The magic phrase for interviews: "retry with exponential backoff and jitter."
When Retry Storms Cause Real Outages
This isn't theoretical. In 2015, a major AWS DynamoDB outage was triggered by a retry storm. A small number of storage nodes became overloaded, which caused requests to time out. Millions of internal services retried simultaneously without sufficient backoff, flooding the system with even more requests. The overloaded nodes couldn't recover because the retries never let up. The cascading failure took down large parts of the internet, including Netflix, Airbnb, and Reddit, for several hours.
The lesson: without proper backoff and jitter, your "helpful" retry logic becomes the weapon that kills your own infrastructure.
The Idempotency Problem: "Did It Go Through or Not?"
Here's where things get genuinely scary. Retries are great... until they have side effects.
Picture this: a user buys a shirt for $30. The payment request goes out... and times out. Did the charge go through? You have no idea.
- If you don't retry and the payment actually failed → the user thinks they paid but didn't. Order gets stuck.
- If you retry and the payment actually succeeded → you just charged them $60 for one shirt.
Both outcomes are terrible. This is the idempotency problem: how do you make it safe to retry a request that might have already succeeded?
What "Idempotent" Means
An idempotent operation gives the same result whether you do it once or ten times:
GET /users/42— Reading data doesn't change anything. Idempotent.DELETE /users/42— Deleting something that's already deleted is a no-op. Idempotent.POST /payments— Each call creates a new payment. NOT idempotent.
Idempotency Keys: Making Retries Safe
For write operations that need safe retries, you add an idempotency key — a unique ID for each logical request.
Here's how the payment example works with idempotency:
- Client generates a unique key:
payment_xyz789 - Client sends
POST /paymentswith the key - Request times out — client doesn't know if it worked
- Client retries with the same key:
payment_xyz789 - Server checks: "Have I seen
payment_xyz789before?" - Yes → Return the original result. No double charge.
- No → Process the payment normally.
It's like giving each transaction a serial number. If the bank sees the same serial number twice, they know it's a retry, not a new charge.
Advanced Deep Dive: Implementing Idempotency Keys in Practice
There are two common strategies for generating idempotency keys:
1. Client-generated UUID — The client creates a random UUID (e.g.,
550e8400-e29b-41d4-a716-446655440000) before sending the request. Simple and universal, but requires the client to store the key until the request succeeds.2. Composite key — Build the key from the request's natural identity:
user_123_order_456orpayment_user123_cart789_1711500000. This is deterministic — the same logical operation always produces the same key, even if the client crashes and restarts.On the backend, the check is straightforward:
def process_payment(idempotency_key, amount, user_id): # Check Redis for existing result cached = redis.get(f"idem:{idempotency_key}") if cached: return json.loads(cached) # Return original result # Process the payment result = charge_card(user_id, amount) # Store result with TTL (e.g., 24 hours) redis.setex(f"idem:{idempotency_key}", 86400, json.dumps(result)) return resultThe key details: use Redis (or another fast store) with a TTL so keys don't accumulate forever. Stripe, PayPal, and most payment APIs use exactly this pattern — you send an
Idempotency-Keyheader, and they guarantee at-most-once processing.
Where Idempotency Matters
Any time "doing it twice" would be bad:
- Payment processing — Double charges
- Order placement — Duplicate orders
- Resource creation — Creating two users instead of one
- Sending messages — Delivering the same notification twice
Interview Tip
Whenever you design a system with write operations and retries, mention idempotency. The combination of "exponential backoff with jitter" for when to retry and "idempotency keys" for making retries safe shows that you understand distributed systems at a practical level. Most candidates mention retries. Fewer mention backoff. Even fewer mention idempotency. It's a strong differentiator.