Lexicographic Subsequences
Beyond Fixed Budgets
You now have the pop budget pattern down: build a stack greedily, pop when the current element improves the sequence, stop when you've used up your budget. Clean and simple.
But the real world — or at least the real LeetCode — isn't always that neat. This lesson covers three harder variants where the core idea is the same (greedy stack construction) but the pop condition changes. The budget isn't just a number you decrement. It depends on the structure of the data itself.
Let's look at each one.
Variant 1: Remove Duplicate Letters
Problem: Given a string, remove duplicate characters so that every letter appears exactly once. Among all possible results, return the lexicographically smallest one.
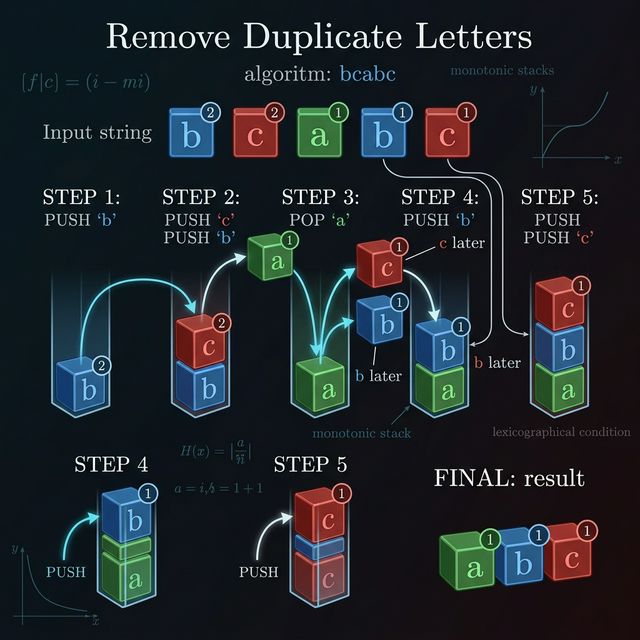
Example: "bcabc" should return "abc". The string "bca" also has each letter once, but "abc" < "bca" lexicographically.
What's the pop condition?
You still want an increasing stack — push smaller characters, pop larger ones. But here's the twist: you can only pop a character if it appears again later in the string. If you pop the last b, you can't get it back, and the result won't contain b at all.
So the "budget" for each character is dynamic: it's whether that character has remaining occurrences in the unprocessed portion of the string. This replaces the simple integer counter from before.
There's a second twist: if a character is already in the stack, you skip it entirely. You don't want duplicates in the result.
Walkthrough: "bcabc"
First, count remaining occurrences: {b:2, c:2, a:1}.
-
'b' arrives. Remaining:
{b:1, c:2, a:1}. Stack empty. Push b. Mark b as in-stack. Stack:[b] -
'c' arrives. Remaining:
{b:1, c:1, a:1}. c > b, no disturbance. Push c. Stack:[b, c] -
'a' arrives. Remaining:
{b:1, c:1, a:0}. a < c — can we pop c? Check: remaining['c'] = 1 > 0, so c appears later. Pop c. Now a < b — can we pop b? remaining['b'] = 1 > 0, so b appears later. Pop b. Push a. Stack:[a] -
'b' arrives. Remaining:
{b:0, c:1, a:0}. b not in stack. b > a, push. Stack:[a, b] -
'c' arrives. Remaining:
{b:0, c:0, a:0}. c not in stack. c > b, push. Stack:[a, b, c]
Result: "abc". Exactly right.
The algorithm
Count remaining occurrences of each character.
For each character c in the string:
Decrement remaining[c].
If c is already in the stack, skip it.
While stack is not empty AND stack.top() > c AND remaining[stack.top()] > 0:
Mark stack.top() as not-in-stack.
Pop.
Push c. Mark c as in-stack.
Return the stack as a string.
Three conditions in the while loop. All three must be true to pop: 1. Stack isn't empty. 2. The top character is larger than the current one (standard greedy comparison). 3. The top character appears later in the string (can be recovered).
This is the same skeleton as Remove K Digits. The only difference is condition 3 replacing the budget counter. Instead of asking "do I have pops left?", you ask "can I afford to lose this specific character?"
A note on "Smallest Subsequence of Distinct Characters"
LeetCode has two problems that are literally the same thing: "Remove Duplicate Letters" (problem 316) and "Smallest Subsequence of Distinct Characters" (problem 1081). Identical problem, identical solution. If you solve one, you've solved both.
Variant 2: Create Maximum Number
Problem: Given two arrays of digits, nums1 of length M and nums2 of length N, create the maximum number of length K using digits from both arrays. The digits from each array must keep their relative order.
This one is harder. It combines the pop budget technique with a merge step. Let's break it down.
Strategy
You don't know how many digits to take from each array. So you try all possible splits:
- Take 0 from
nums1, K fromnums2 - Take 1 from
nums1, K-1 fromnums2 - ...
- Take K from
nums1, 0 fromnums2
(Bounded by the actual lengths of the arrays, of course.)
For each split (i, K-i):
1. Use the pop budget algorithm to find the largest subsequence of length i from nums1.
2. Use the pop budget algorithm to find the largest subsequence of length K-i from nums2.
3. Merge the two subsequences into the largest possible combined sequence.
Take the best result across all splits.
The merge step
This part is tricky, so let's break it down. You have two subsequences and need to interleave them (maintaining internal order) to form the largest possible sequence. This is a greedy merge — at each step, pick the next element from whichever subsequence is "larger."
But "larger" doesn't just mean comparing the current elements. When they're equal, you need to look ahead. If both sequences start with 6, you pick from the one whose remaining suffix is lexicographically larger.
Example: merging [6, 7] and [6, 0, 4].
- Both start with 6. Compare suffixes: [6, 7] vs [6, 0, 4]. First elements equal, second: 7 > 0. So pick from the first.
- Result so far: [6]. Remaining: [7] and [6, 0, 4].
- 7 > 6, pick 7. Result: [6, 7]. Remaining: [] and [6, 0, 4].
- First array exhausted. Append rest: [6, 7, 6, 0, 4].
Complexity
For each split, computing the best subsequence is O(M) or O(N). The merge is O(K) with suffix comparisons that can take O(K) each in the worst case. There are O(K) splits to try. Total: O(K^2 * (M + N)) in the worst case. It's not blazing fast, but it's good enough for typical constraints (K up to a few hundred).
Why this is still the pop budget pattern
Each call to "find the largest subsequence of length L" is exactly the decreasing-stack version of the pop budget algorithm from the last lesson. The merge is new, but the core construction step is the same tool.
Variant 3: Connecting the Pop Conditions
Let's take a step back and see the pattern across all three variants.
| Problem | Stack Direction | Pop Condition |
|---|---|---|
| Remove K Digits | Increasing | budget > 0 && top > current |
| Best Subsequence of Length L | Increasing/Decreasing | budget > 0 && top worse than current |
| Remove Duplicate Letters | Increasing | top > current && remaining[top] > 0 |
| Create Maximum Number | Decreasing (per array) | budget > 0 && top < current |
The stack is always doing the same thing: building the answer one element at a time, ejecting suboptimal elements when something better comes along. What varies is the constraint on ejection:
- Fixed budget: You can pop at most K times total.
- Remaining supply: You can pop a character only if it shows up again later.
- Size guarantee: You can pop only if enough elements remain to fill the target length.
In the hardest problems, multiple constraints combine. Remove Duplicate Letters has both the "remaining supply" constraint and the "each character exactly once" constraint (enforced by the in_stack check). Create Maximum Number has the fixed budget constraint applied separately to two arrays, plus a merge.
Building Your Recognition Muscle
When you see a new problem, here's how to tell if it's a greedy stack construction problem:
- You're building a sequence (not querying ranges or computing areas).
- Lexicographic optimization — the problem asks for the smallest/largest/best result by some ordering.
- Relative order must be preserved — you're picking a subsequence, not rearranging.
- There's a constraint on how many elements you keep or remove.
If all four are present, reach for the greedy stack. Write down the pop condition — what must be true for a pop to be safe? That's usually the crux of the problem.
Walkthrough: Remove Duplicate Letters on "cbacdcbc"
Let's do one more detailed trace to make sure this is solid.
Input: "cbacdcbc"
Remaining counts: {c:4, b:2, a:1, d:1}
- 'c': remaining c -> 3. Stack empty. Push.
[c] - 'b': remaining b -> 1. b < c, remaining[c] = 3 > 0, pop c. Stack empty. Push b.
[b] - 'a': remaining a -> 0. a < b, remaining[b] = 1 > 0, pop b. Push a.
[a] - 'c': remaining c -> 2. c > a, push.
[a, c] - 'd': remaining d -> 0. d > c, push.
[a, c, d] - 'c': remaining c -> 1. c is already in stack. Skip.
- 'b': remaining b -> 0. b < d, but remaining[d] = 0 — can't pop d (it's the last one). Stop. b < c, but remaining[c] = 1 > 0 — can pop c? Wait, we need to check: d is on top, and we couldn't pop d. So b just goes after d. Push b.
[a, c, d, b] - 'c': remaining c -> 0. c is already in stack. Skip.
Result: "acdb". Let's verify: the distinct characters are a, b, c, d. Among all orderings that respect the original positions, is "acdb" the smallest? The 'a' is at index 2 — that's the earliest we can place 'a'. After index 2, we need c, d, b in some valid order. 'c' appears at index 3 (good). 'd' at index 4 (good). 'b' at index 7 (good). And "acdb" < "acdc" or any other arrangement starting with "acd". Correct.
The Big Picture
This chapter introduced a fundamentally different use of the monotonic stack. In Chapters 1-3, the stack was a passive observer — it watched elements go by and answered questions about relationships between them. Here, the stack is an active builder. It constructs the optimal sequence element by element.
The unifying idea is the pop budget — a constraint on how aggressively the stack can eject elements. Different problems impose different constraints:
- A fixed count (Remove K Digits)
- A minimum length requirement (best subsequence of length L)
- A future-availability check (Remove Duplicate Letters)
- A per-array budget with a merge step (Create Maximum Number)
But the skeleton never changes. Scan left to right. Maintain a stack. Pop when it's safe and beneficial. Push the current element. At the end, the stack holds your answer.
Once you internalize this pattern, these problems stop feeling like separate puzzles. They're all the same machine with different fuel gauges.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| LC 402 — Remove K Digits | leetcode.com/problems/remove-k-digits | Medium |
| LC 316 — Remove Duplicate Letters | leetcode.com/problems/remove-duplicate-letters | Medium |
| LC 1673 — Most Competitive Subsequence | leetcode.com/problems/find-the-most-competitive-subsequence | Medium |
| LC 2030 — Smallest K-Length Subsequence | leetcode.com/problems/smallest-k-length-subsequence-with-occurrences-of-a-letter | Hard |