Denormalization
TL;DR
Denormalization intentionally duplicates data to make reads faster. You sacrifice write simplicity and risk inconsistency, but your hot read paths avoid expensive joins. The rule: normalize first, denormalize only when a specific query demands it.
The Tension
In the last lesson, we normalized everything. Each fact stored once. No redundancy. Clean and correct.
But then you write the query for your most critical page — the home feed — and it joins 5 tables, aggregates likes, and sorts by timestamp. It takes 200ms. Your product manager wants it under 50ms. Your users want it under 20ms.
This is the fundamental tension in data modelling: normalization optimizes for writes and consistency. Denormalization optimizes for reads and speed. Every real system lives somewhere on this spectrum.
What Denormalization Actually Means
Denormalization means deliberately storing redundant data to avoid expensive operations at read time.
Example 1: Embedding the Author's Name
Normalized: To display a post with its author's name, you join two tables:
SELECT posts.content, users.username
FROM posts
JOIN users ON posts.user_id = users.id
WHERE posts.id = 42;
Denormalized: Store the author's name directly on the post:
The author_username column is redundant — it duplicates data from the users table. But it eliminates a join on every post read. For a feed showing 50 posts, that's 50 joins you just avoided.
Example 2: Pre-computed Counts
Normalized: Count likes by querying the likes table:
Denormalized: Store the count directly on the post:
Every time someone likes or unlikes a post, you increment or decrement like_count. The count is always available without scanning the likes table.
Instagram does this. When a post by a celebrity has 3 million likes, you don't want to COUNT(*) three million rows every time someone views it.
Example 3: Materialized Feeds
Normalized: Compute the home feed at read time by joining posts, follows, and sorting:
SELECT posts.* FROM posts
JOIN follows ON posts.user_id = follows.following_id
WHERE follows.follower_id = ?
ORDER BY posts.created_at DESC
LIMIT 50;
Denormalized: Pre-compute the feed into a feed_items table:
feed_items
┌─────────┬─────────┬────────────┬─────────┐
│ user_id │ post_id │ created_at │ author │
├─────────┼─────────┼────────────┼─────────┤
│ 1 │ 500 │ 2024-03-15 │ bob │
│ 1 │ 499 │ 2024-03-15 │ carol │
│ 1 │ 497 │ 2024-03-14 │ bob │
└─────────┴─────────┴────────────┴─────────┘
Reading the feed is now a simple range scan on one table. The complexity shifts to write time — when someone posts, you insert a feed_item for each of their followers. This is the fan-out on write pattern that Twitter uses (more on this in Chapter 7).
The Cost of Denormalization
Every denormalization creates two problems:
1. Consistency Becomes Your Responsibility
When Alice changes her username, you now need to update:
- The users table (source of truth)
- The author_username on every post she's ever written
- The author field in every feed_item
- Any other table that duplicated her name
Miss one, and your data is inconsistent. The database won't help you here — there's no foreign key constraint on denormalized copies.
Strategies for handling this: - Synchronous updates: Update all copies in the same transaction. Correct but slow. - Background jobs: Update the source of truth immediately, then queue a job to update copies. Faster but temporarily inconsistent. - Accept staleness: For some data (like a cached feed), it's fine if it's a few seconds behind. A feed showing "alice" instead of "alice_new_name" for 30 seconds won't break anything.
2. Writes Get More Complex
Every denormalized field is another thing to update when the source data changes. A like_count on posts means every like and unlike must atomically increment or decrement the counter:
-- When someone likes a post:
BEGIN;
INSERT INTO likes (user_id, post_id) VALUES (?, ?);
UPDATE posts SET like_count = like_count + 1 WHERE id = ?;
COMMIT;
-- When someone unlikes:
BEGIN;
DELETE FROM likes WHERE user_id = ? AND post_id = ?;
UPDATE posts SET like_count = like_count - 1 WHERE id = ?;
COMMIT;
If the application crashes between the INSERT and UPDATE, the count drifts. You might need periodic reconciliation jobs to fix drift over time.
When to Denormalize
Denormalization is a performance optimization. Like all optimizations, don't do it until you have a reason.
Denormalize when:
| Signal | Example |
|---|---|
| A hot read path requires joins that add latency | Home feed joining posts + follows + users |
| An aggregation runs on every page load | COUNT(*) for likes, comments, followers |
| The same join appears in many queries | Author name shown on posts, comments, notifications |
| Read/write ratio is heavily skewed toward reads | Social media (1000:1 reads to writes on popular content) |
Don't denormalize when:
| Signal | Example |
|---|---|
| The data changes frequently | User email (changes create mass updates across tables) |
| Consistency is critical | Financial transactions, inventory counts |
| The read pattern is simple | Direct lookups by primary key (already fast with an index) |
| A cache would solve it | If the data fits in Redis, cache the join result instead of denormalizing |
Cache vs Denormalize — A Key Decision
Before denormalizing, ask: would a cache solve this problem?
A cache (Redis, Memcached) gives you the same read speed benefit without polluting your schema:
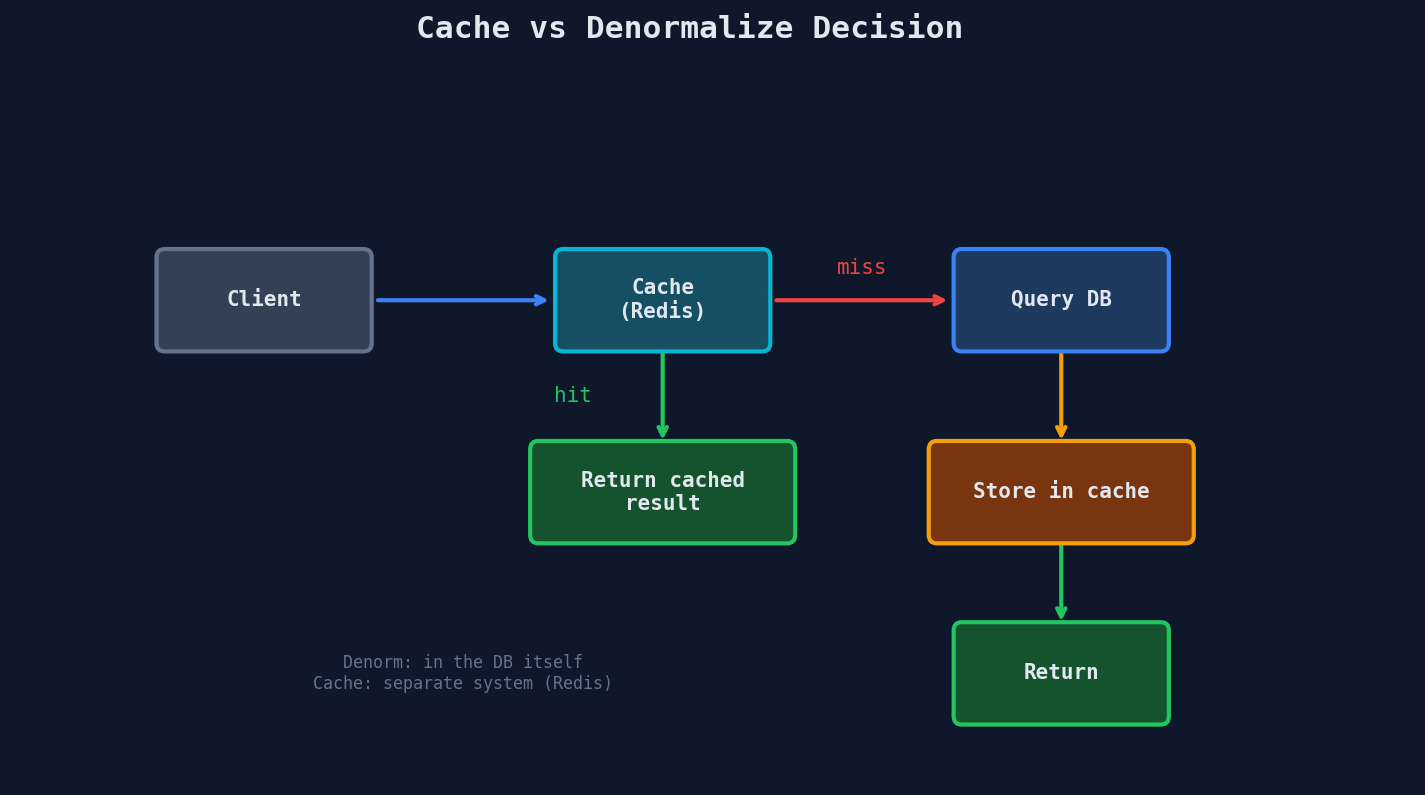
| Denormalization | Cache | |
|---|---|---|
| Where | In the database itself | Separate system (Redis) |
| Consistency | Must update on every write | Must invalidate on every write |
| Failure mode | Wrong data silently served | Cache miss → slower but correct |
| Complexity | Schema changes, migration needed | Application code only |
| Best for | Stable, rarely-changing denormalized data | Frequently-changing or expensive-to-compute data |
Further reading: For a deeper dive into caching patterns (cache-aside, write-through, write-behind, cache stampede, thundering herd), see the Caching and Redis articles.
Interview Tip
When proposing denormalization in an interview, always acknowledge the trade-off: "I'll store like_count directly on the post to avoid counting millions of rows on each read. The trade-off is that likes and unlikes now need to atomically update both the likes table and the counter. I'd also run a periodic reconciliation job to fix any drift." That shows mature engineering judgment.
A Practical Framework
Here's how to think about denormalization in a system design interview:
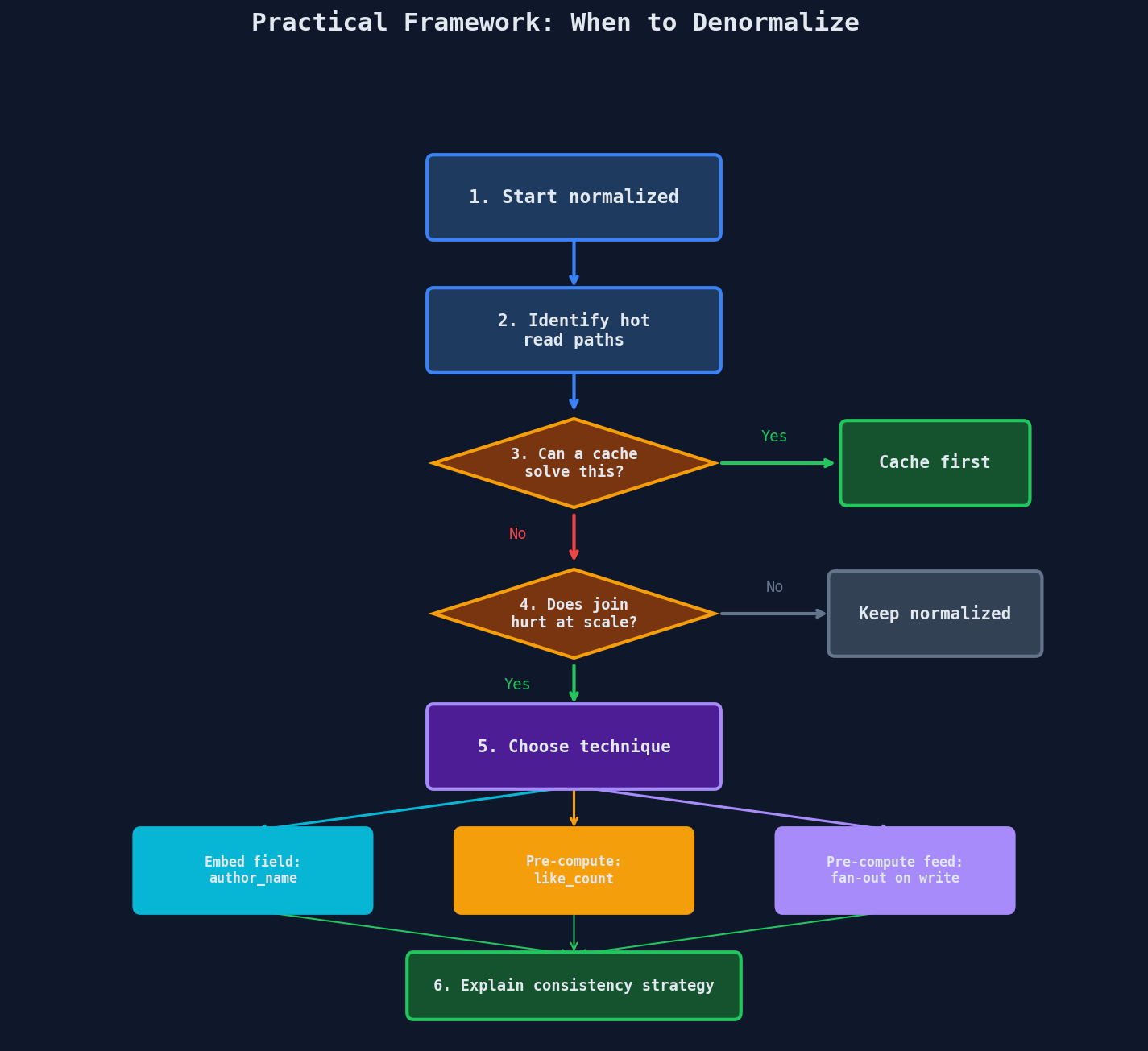
Quick Recap
| Technique | What It Does | Good For | Cost |
|---|---|---|---|
| Embedded fields | Copy a field from related table | Avoiding joins on hot paths | Updates must propagate to all copies |
| Pre-computed counts | Store aggregates directly | Avoiding COUNT(*) at scale | Must keep counter in sync |
| Materialized feeds | Pre-build query results | Complex multi-table reads | Write amplification |
| Caching | Store computed results in Redis | Any hot read path | Cache invalidation complexity |
The goal isn't to avoid denormalization — it's to denormalize intentionally, for specific queries, with a clear understanding of the trade-offs.