Evolution of Solutions
TL;DR
Distributed workflow solutions evolved through three generations: (1) a single API server calling services sequentially — simple but fragile; (2) checkpoint-based state machines — durable but painful to maintain; (3) event-driven architectures where workers react to events on a durable log — scalable and auditable but hard to reason about as a whole. Each generation solves the previous one's problems while introducing new trade-offs. Understanding this evolution is essential because you'll encounter all three in production systems.
Generation 1: The Naive Orchestrator
The simplest approach. One API server calls each downstream service in sequence. The order service is the orchestrator — it knows the full workflow and executes it step by step.
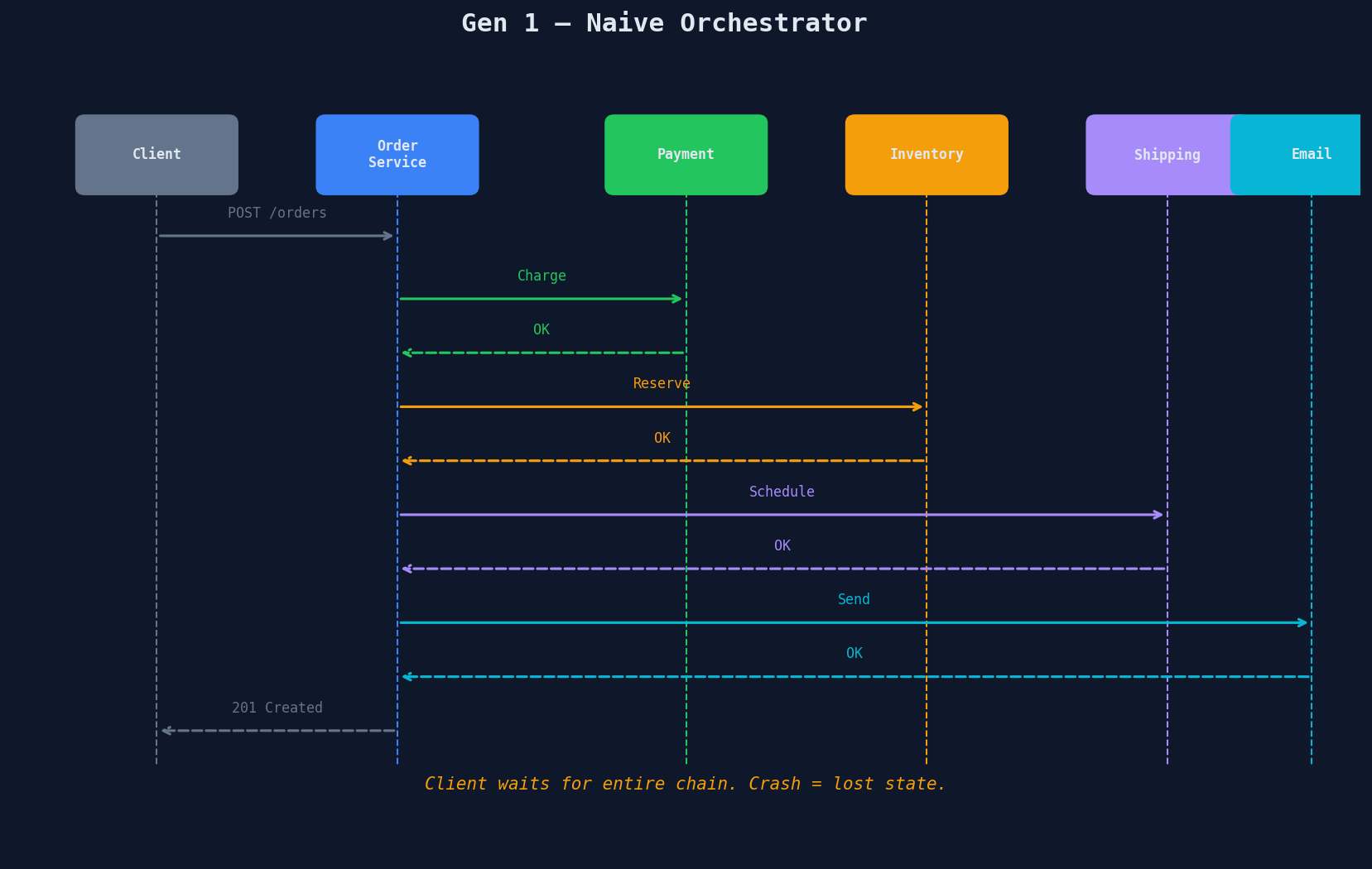
The client waits while the API server marches through every step. This is how most teams build their first version — and it works until it doesn't.
Why It Breaks
Problem 1: Crash = lost state. If the Order Service process dies between charging the payment and reserving inventory, the workflow vanishes. The customer is charged, but nothing else happens. On restart, the server has no record of this in-flight order.
Problem 2: Tight coupling. The Order Service must know about every downstream service, their APIs, error codes, and retry semantics. Add a loyalty points step? You're modifying the orchestrator.
Problem 3: Latency stacks. Each step runs sequentially. If payment takes 500ms, inventory takes 200ms, shipping takes 300ms, and email takes 100ms, the client waits 1.1 seconds minimum. Under load, any slow service blocks the entire chain.
Problem 4: No scalability story. The orchestrator is a single bottleneck. You can't parallelize independent steps or distribute the workflow across multiple workers.
Failure timeline:
──────────────────────────────────────────────
t1: Charge card → Success ($99.99 deducted)
t2: Reserve inventory → ??? (server crashes here)
t3: [nothing] → Process is dead
──────────────────────────────────────────────
Result: Orphaned charge. No inventory hold. No order record.
Generation 2: Add State Persistence
The fix seems obvious: checkpoint your progress. After each step, write the current state to a database. If the server crashes, it can reload the checkpoint and resume.
def place_order(order):
state = db.get_workflow_state(order.id)
if state is None:
state = db.create_workflow(order.id, step="start")
if state.step == "start":
charge_payment(order)
db.update_workflow(order.id, step="payment_done")
if state.step == "payment_done":
reserve_inventory(order)
db.update_workflow(order.id, step="inventory_reserved")
if state.step == "inventory_reserved":
schedule_shipping(order)
db.update_workflow(order.id, step="shipping_scheduled")
if state.step == "shipping_scheduled":
send_confirmation_email(order)
db.update_workflow(order.id, step="completed")
Now if the server crashes after payment, the next restart (or a recovery worker) can pick up where it left off. Progress is durable.
The State Machine You Didn't Mean to Build
But look at what you've built. This is a hand-rolled state machine with transitions stored in a database. Every new step needs a new state, a new transition, and new recovery logic. Add error handling:
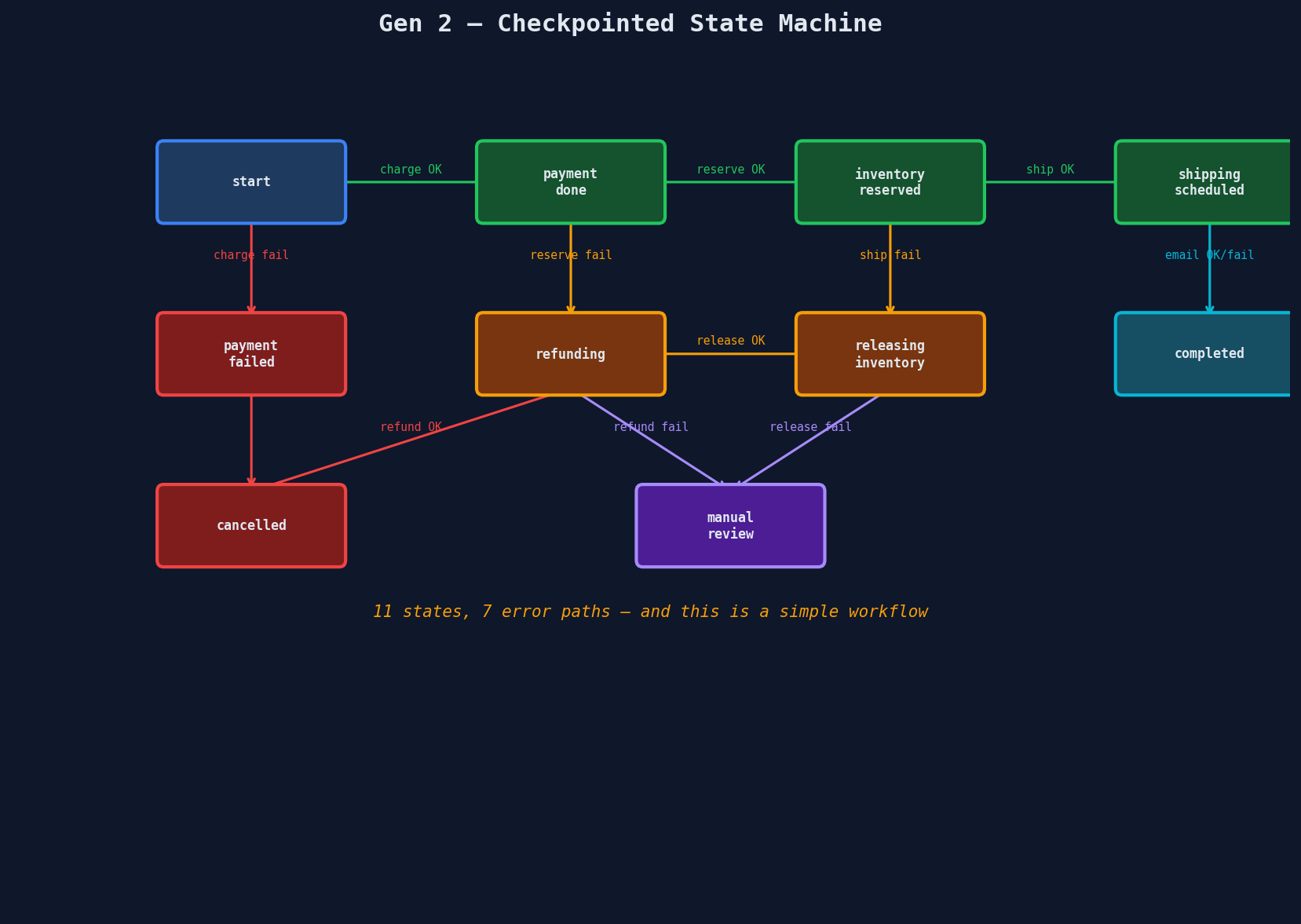
Eleven states. Seven error paths. And this is a simple four-step workflow. Real production workflows have 15-30 steps, conditional branches, parallel paths, and timer-based escalations. The state machine becomes a maintenance nightmare that no one wants to touch.
The Custom State Machine Trap
Every team that builds a custom workflow engine says the same thing six months later: "We should have used an existing framework." Custom state machines accrete complexity organically — an error state here, a retry path there — until the state diagram looks like a plate of spaghetti and no one is confident enough to modify it.
The Checkpoint Race Condition
There's a subtle but critical bug in the checkpoint approach. What if the server crashes between completing a step and writing the checkpoint?
t1: charge_payment(order) → Success (card charged)
t2: [CRASH] → Process dies before DB write
t3: [Recovery] reads state → step="start"
t4: charge_payment(order) → Card charged AGAIN
The customer gets double-charged. To fix this, every step must be idempotent — safe to execute multiple times with the same result. We'll cover this in Lesson 4, but notice how infrastructure concerns keep leaking into your business logic.
Generation 3: Event-Driven Architecture
Instead of one orchestrator calling services sequentially, flip the model. Each service reacts to events on a durable log (like Kafka or AWS SQS). No single service owns the workflow — it emerges from the chain of events.
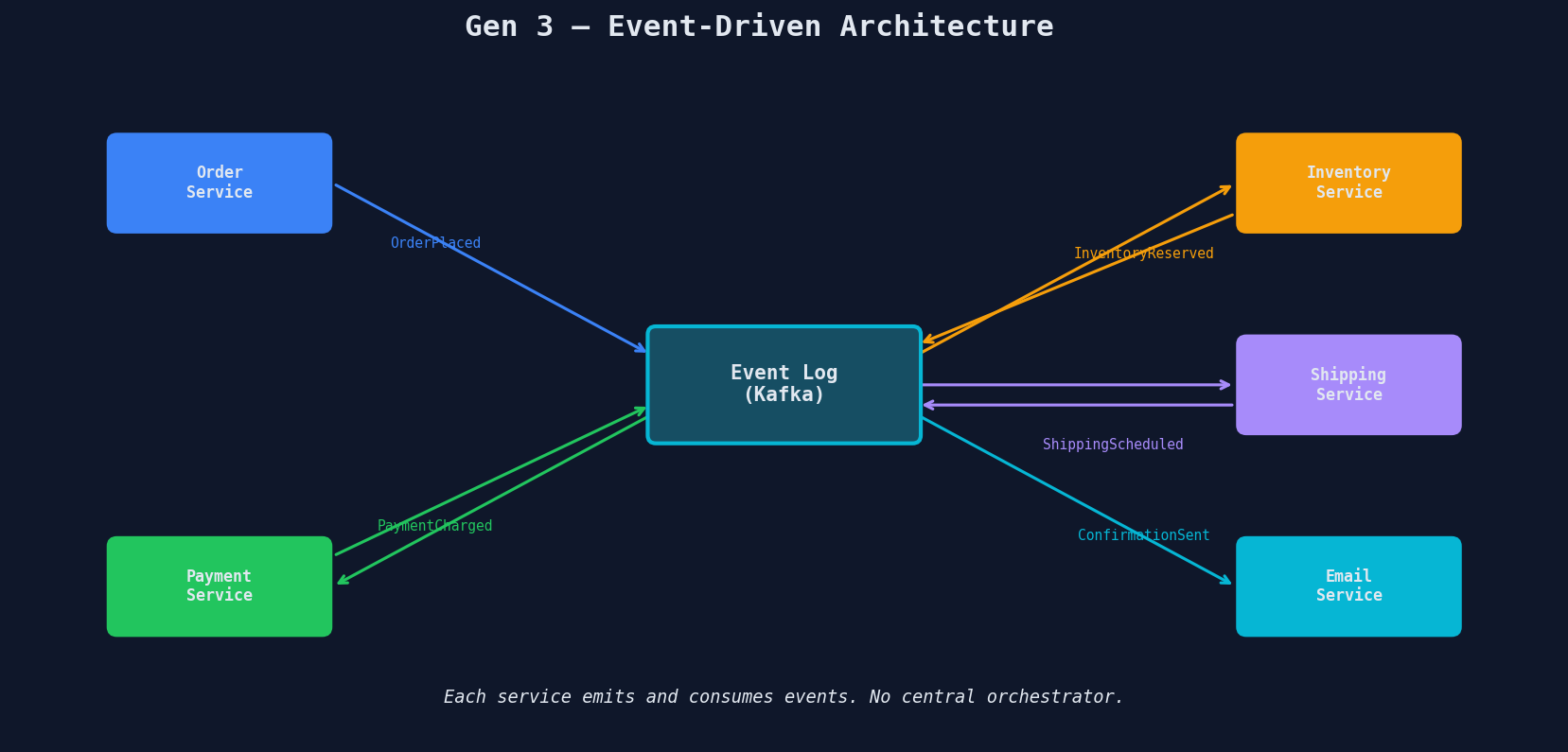
Each service does one thing:
- Consume an event from the log
- Do its work (charge payment, reserve inventory, etc.)
- Emit a new event back to the log
The event log (Kafka, Pulsar, SQS, etc.) is durable — events survive crashes, restarts, and deployments. If a consumer dies mid-processing, the event stays in the log and gets redelivered.
The Event Flow in Detail
Event Timeline:
═══════════════════════════════════════════════════════════
Event 1: OrderPlaced
→ Payment Service picks up
→ Charges card
→ Emits PaymentCharged
Event 2: PaymentCharged
→ Inventory Service picks up
→ Reserves 1x Widget
→ Emits InventoryReserved
Event 3: InventoryReserved
→ Shipping Service picks up
→ Schedules FedEx pickup
→ Emits ShippingScheduled
Event 4: ShippingScheduled
→ Email Service picks up
→ Sends confirmation to customer
→ Emits ConfirmationSent
═══════════════════════════════════════════════════════════
What This Gets Right
Fault tolerance. If the Inventory Service crashes after reading PaymentCharged but before emitting InventoryReserved, the event stays unconsumed (or gets redelivered with at-least-once semantics). The workflow resumes automatically when the service recovers.
Scalability. Each service scales independently. Need more payment throughput? Add more Payment Service instances. They all consume from the same topic partition.
Audit trail. The event log is a complete history of everything that happened. You can replay events to debug, rebuild state, or seed a new service.
Loose coupling. Services don't know about each other. The Payment Service doesn't call the Inventory Service — it emits an event and moves on. Adding a loyalty-points step means adding a new consumer on PaymentCharged. Zero changes to existing services.
What This Gets Wrong
The "who owns the workflow?" problem. In the orchestrator model, the Order Service owns the flow. You can read one file and understand the entire process. In the event-driven model, the workflow is smeared across five services, five event handlers, and five event schemas. Understanding the full flow requires tracing events across multiple codebases.
Debugging is painful. Customer says their order is stuck. Which event is it waiting on? Which service consumed the last event? Did the event get emitted but no consumer picked it up? You need distributed tracing, correlation IDs, and log aggregation just to answer basic questions.
Error handling is distributed. If inventory reservation fails, who triggers the payment refund? The Inventory Service? A dedicated compensation service? Some event-driven saga coordinator? The error flow is just as distributed as the happy path — and harder to reason about.
Ordering is not guaranteed. Events can arrive out of order, be duplicated, or be processed concurrently. Your consumers must be idempotent and order-insensitive, which adds complexity to every handler.
Event Sourcing vs. Event-Driven Architecture
These two concepts are frequently confused — even by experienced engineers. They are separate patterns that can be used independently or together.
Event-Driven Architecture (EDA) is a communication pattern. Services talk to each other by emitting and consuming events through a message broker. The focus is on decoupling services.
Event Sourcing is a persistence pattern. Instead of storing current state (e.g., balance: \$50), you store every event that changed the state (Deposited \$100, Withdrew \$50). The current state is derived by replaying all events.
When using event sourcing, the event log is the source of truth, but you still need read-optimized views. This is where CQRS (Command Query Responsibility Segregation) comes in — separate read models (materialized views) are built by replaying events. For example, an order events log produces a "current order status" read model, an "order analytics" model, and a "customer order history" model — each optimized for its specific query pattern.
You can use EDA without event sourcing (most common). You can use event sourcing without EDA (single-service, event-sourced aggregate). You can use both together (event-sourced microservices communicating via events). But they solve different problems — don't conflate them.
Comparing the Three Generations
| Dimension | Gen 1: Naive Orchestrator | Gen 2: Checkpointed State Machine | Gen 3: Event-Driven |
|---|---|---|---|
| Crash recovery | None — state is lost | Resume from checkpoint | Event redelivered by broker |
| Visibility | Read one function | Read state machine diagram | Trace events across services |
| Coupling | Orchestrator knows everything | Orchestrator still knows everything | Services are independent |
| Scalability | Single bottleneck | Single bottleneck (with DB) | Each service scales independently |
| Error handling | try/catch in one place | State transitions for errors | Distributed compensation |
| Complexity | Low (until it breaks) | Medium (grows with states) | High (distributed reasoning) |
| Debug story | Stack trace | Query workflow state table | Distributed tracing required |
| When to use | Prototypes, low-traffic | Medium-complexity workflows | High-scale, many teams |
The Missing Piece
Notice the pattern: each generation trades one problem for another.
- Gen 1 is simple but fragile.
- Gen 2 is durable but creates a maintenance nightmare.
- Gen 3 is scalable but makes reasoning about the workflow incredibly hard.
What we really want is the simplicity of Gen 1 (write sequential code) with the durability of Gen 2 (survive crashes) and the scalability of Gen 3 (independent services). Write your business logic as a simple function, and let the framework handle crashes, retries, and persistence invisibly.
The ideal:
──────────────────────────────────────────────
def place_order(order): # ← Write this
charge_payment(order) # (looks like Gen 1)
reserve_inventory(order)
schedule_shipping(order)
send_confirmation(order)
# Framework provides: ← Get this for free
# ✓ Crash recovery (Gen 2)
# ✓ Scalability (Gen 3)
# ✓ Retry with backoff
# ✓ Timeout handling
# ✓ Audit trail
# ✓ Visibility into running workflows
──────────────────────────────────────────────
This is exactly what durable execution frameworks provide. Temporal, AWS Step Functions, and Netflix Conductor each take a different approach, but they all promise the same thing: separate your business logic from infrastructure concerns.
That's the next lesson.
Quick Recap
| Concept | Key Takeaway |
|---|---|
| Naive orchestrator | Sequential calls, no durability — crashes lose everything |
| Checkpointed state machine | Durable but becomes unmaintainable spaghetti |
| Checkpoint race condition | Crash between step and checkpoint = duplicate execution |
| Event-driven architecture | Scalable and decoupled, but workflow is invisible |
| EDA vs event sourcing | Communication pattern vs persistence pattern — don't confuse them |
| The missing piece | We want simple code + durable execution + scalability |
Interview Tip
When discussing distributed workflows in an interview, walk through this evolution: "We could have a single orchestrator, but it's not crash-safe. We could checkpoint to a DB, but that creates a brittle state machine. We could go event-driven, but then nobody can see the full workflow. This is why frameworks like Temporal exist — they give you sequential code with durable execution under the hood." This shows you understand the why behind the tooling, not just the what.