Race Conditions
TL;DR
Race conditions happen when two operations read the same state, make decisions based on it, and then both write — not knowing the other exists. The gap between "check the current state" and "update based on that state" is where bugs live. This is an isolation problem (transactions interfering with each other), not an atomicity problem (single transactions partially completing). Understanding this distinction is the foundation for every concurrency control strategy that follows.
The Weeknd Has One Seat Left
Picture this: 1 seat left for The Weeknd. Alice is on her phone in Toronto. Bob is on his laptop in Vancouver. Both click "Buy" at the exact same moment — within a few milliseconds of each other.
Your backend receives two HTTP requests. Two threads pick them up. Two database connections open. Two transactions begin. Neither knows the other exists.
Here's what happens under the hood:
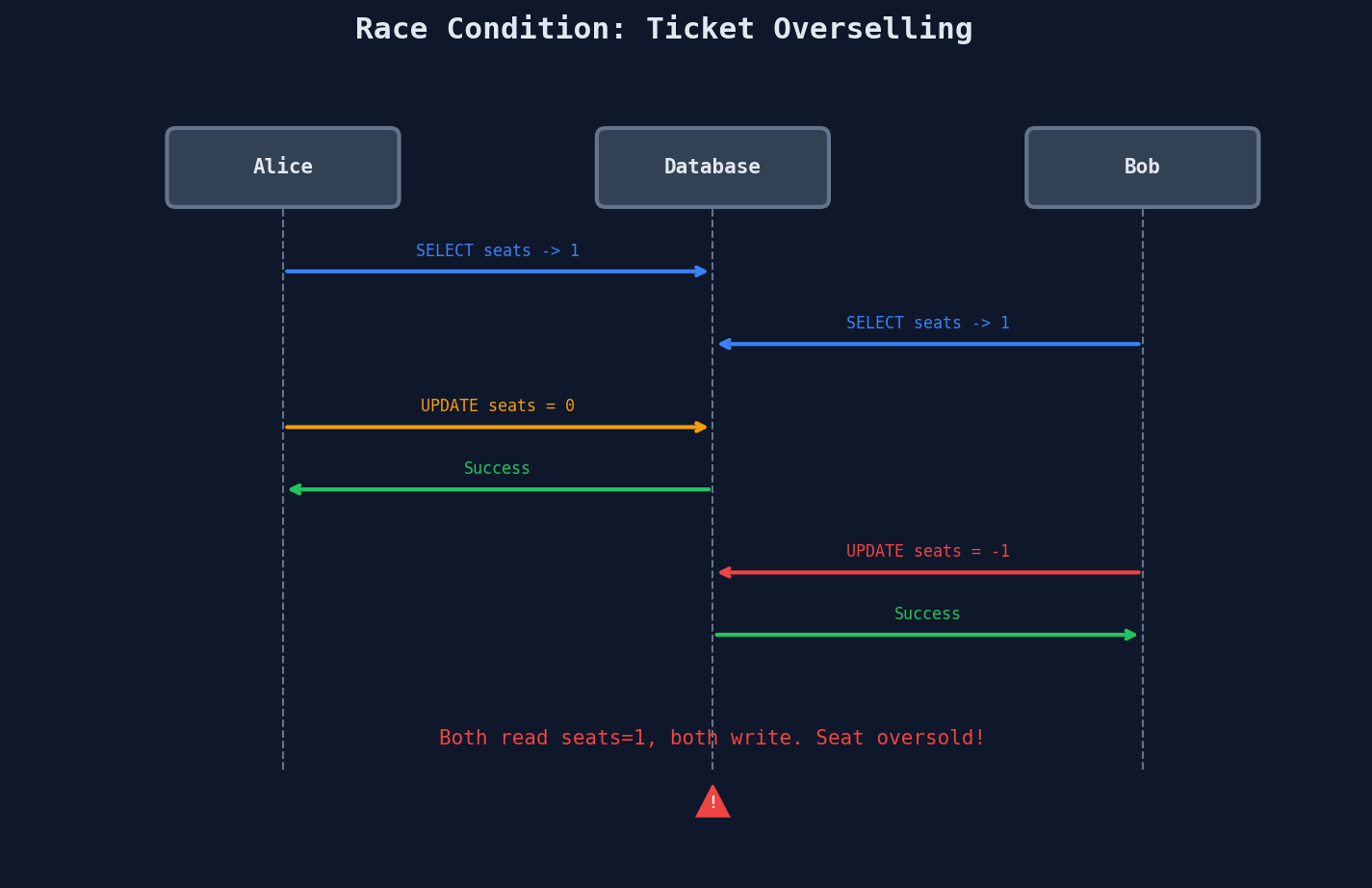
Each transaction, looked at in isolation, did nothing wrong. Alice checked the count, saw 1, decremented it. Bob did the same. The problem is that both read the same initial state before either one wrote. They each made a perfectly rational decision based on information that was already stale by the time they acted on it.
This is the core of every race condition: individually correct operations that produce collectively wrong results because they interfere with each other.
TOCTOU — The Bug With a Name
This class of bug has a formal name: Time Of Check, Time Of Use (TOCTOU).
| Step | What Happens | The Problem |
|---|---|---|
| Check (Time of Check) | "Is a seat available?" → Yes | This answer is only true right now |
| Gap | Microseconds pass... | Other transactions are running in this gap |
| Use (Time of Use) | "Decrement the seat count" | The seat might already be gone |
The window between check and use can be microseconds. On a quiet system with 10 concurrent users, you might see one conflict per hour — easy to miss in testing. But at 10,000 concurrent users hitting the same hot resource, those microseconds produce constant conflicts. The bug that never appeared in staging becomes a production fire every night at peak traffic.
Here's the thing that makes TOCTOU so insidious: you can't catch it with unit tests. A single-threaded test will always check and then use without interruption. The bug only appears when two operations overlap in time — and the overlap window can be smaller than the time it takes to execute a single line of code.
TOCTOU Is Everywhere
This isn't just a database problem. File systems have it (check if file exists, then write to it — another process deletes it in between). Distributed systems have it (check if lock is free, then acquire it). Even real-world systems have it — ATMs checking your balance before dispensing cash. Any time you separate "reading state" from "acting on state," you open a TOCTOU window.
The Broken SQL — And Why It Looks Correct
Here's the SQL that ships to production because it looks like it handles the race condition. This is the single biggest confusion point in concurrency control, and community discussions confirm it trips up even experienced engineers.
BEGIN TRANSACTION;
UPDATE concerts
SET available_seats = available_seats - 1
WHERE concert_id = 'weeknd_tour'
AND available_seats > 0;
INSERT INTO tickets (user_id, concert_id, seat_number)
VALUES ('user123', 'weeknd_tour', 'A15');
COMMIT;
Read that UPDATE carefully. It has AND available_seats > 0 in the WHERE clause. Seems safe, right? If there are no seats left, the UPDATE won't decrement below zero. Problem solved?
No. Here's what actually happens when available_seats is already 0:
| Step | What the Database Does | What You Probably Expected |
|---|---|---|
UPDATE ... WHERE available_seats > 0 |
Matches 0 rows. Updates nothing. Returns success. | "It should fail or stop the transaction" |
INSERT INTO tickets ... |
Inserts the ticket row. Returns success. | "It shouldn't run if the UPDATE didn't work" |
COMMIT |
Commits both operations. Returns success. | "It should have rolled back" |
The ticket is created. No seat was decremented. You just oversold.
The Trap: 0 Rows Affected Is Not a Failure
A transaction guarantees that all operations succeed or all fail (atomicity). But an UPDATE that matches 0 rows is not a failure. It's a perfectly successful UPDATE that happened to find nothing to update. The database doesn't know you intended for the UPDATE to be a prerequisite for the INSERT. It just runs each statement in order, and both succeed. The transaction happily commits.
This is the mental model that breaks for people: they assume a transaction is a conditional — "do all this only if the first part actually changed something." It's not. A transaction is a unit of atomicity: all-or-nothing execution. But "nothing happened" in one statement doesn't trigger the "nothing" (rollback) path. Each statement independently succeeded.
Let's trace two concurrent transactions to see the overselling bug in action:
Timeline — Two Concurrent Transactions with the Broken SQL:
available_seats = 1
T1 (Alice): BEGIN → UPDATE (seats 1→0, 1 row affected) → INSERT ticket → COMMIT ✅
T2 (Bob): BEGIN → UPDATE (seats already 0, 0 rows affected) → INSERT ticket → COMMIT ✅
Result: 2 tickets created, but seats only decremented once.
available_seats = 0, but 2 people have tickets.
The UPDATE with the WHERE guard correctly prevents the counter from going below 0 — that part works. But the INSERT doesn't care what the UPDATE did. It runs unconditionally. Two tickets, one seat. The customer support team gets the angry call.
The Fix — Make the INSERT Depend on the UPDATE
The solution is to structurally link the INSERT to the UPDATE's result, so the INSERT cannot run unless the UPDATE actually affected a row.
WITH reserved AS (
UPDATE concerts
SET available_seats = available_seats - 1
WHERE concert_id = 'weeknd_tour'
AND available_seats > 0
RETURNING concert_id
)
INSERT INTO tickets (user_id, concert_id, seat_number)
SELECT 'user123', concert_id, 'A15'
FROM reserved;
Here's why this works:
-
The
UPDATE ... RETURNING concert_idruns first. Ifavailable_seats > 0, it decrements and returns theconcert_id. Ifavailable_seatsis already 0, it returns nothing — an empty result set. -
The
INSERT ... SELECT ... FROM reserveddraws its data from that result set. Ifreservedis empty (the UPDATE matched 0 rows), the SELECT returns 0 rows, so the INSERT inserts 0 rows. -
No seat decremented → no ticket created. The coupling is structural, not based on hope.
| Scenario | UPDATE Result | reserved CTE |
INSERT Result |
|---|---|---|---|
available_seats = 5 |
Decrements to 4, returns row | 1 row | Ticket created |
available_seats = 1 |
Decrements to 0, returns row | 1 row | Ticket created |
available_seats = 0 |
Matches 0 rows, returns nothing | 0 rows | Nothing inserted |
Alternative: Check in Application Code
If your database doesn't support WITH ... RETURNING (or your ORM makes it awkward), you can check the affected row count in application code:
cursor.execute("""
UPDATE concerts
SET available_seats = available_seats - 1
WHERE concert_id = %s AND available_seats > 0
""", (concert_id,))
if cursor.rowcount == 0:
connection.rollback()
raise SoldOutError("No seats available")
cursor.execute("""
INSERT INTO tickets (user_id, concert_id, seat_number)
VALUES (%s, %s, %s)
""", (user_id, concert_id, seat_number))
connection.commit()
This achieves the same result — the INSERT only runs if the UPDATE affected a row — but the logic lives in your application rather than in SQL. Most production systems use this approach because it's easier to add logging, custom error messages, and retry logic around the failure case.
Both approaches fix the symptom — the decoupled INSERT. But neither fixes the root cause: two transactions contending on the same resource. For that, you need isolation-level controls — locking, serializable transactions, or application-level coordination — which are the subject of the next lessons in this chapter.
"But Wait — Doesn't the UPDATE Lock the Row?"
This question comes up constantly, and it reveals a subtlety worth addressing head-on.
Yes, in PostgreSQL and most relational databases, an UPDATE acquires a row-level lock on any row it modifies. If Alice's UPDATE runs first and locks the row, Bob's UPDATE will wait until Alice commits. After Alice commits, Bob's UPDATE re-evaluates the WHERE clause against the new value of available_seats.
So with the WHERE available_seats > 0 guard, here's what actually happens in the basic UPDATE scenario:
T1 (Alice): UPDATE seats = 0 WHERE seats > 0 → locks row → COMMIT → releases lock
T2 (Bob): UPDATE seats WHERE seats > 0 → waits... → re-checks: seats = 0 → 0 rows affected
The UPDATE itself is safe against going negative — Bob's UPDATE will correctly match 0 rows after Alice commits. The problem is what happens after the UPDATE in the broken SQL example: the INSERT still runs regardless of whether the UPDATE matched anything.
The row-level lock protects the counter from going negative. It does not protect you from creating a ticket without decrementing a seat. That's why the WITH ... RETURNING fix or the application-level rowcount check is necessary — the race condition isn't in the UPDATE itself, it's in the decoupled INSERT that follows.
This is a crucial nuance. Many engineers see the row-level lock behavior and conclude "the database handles it." The database handles the counter integrity — available_seats will never be -1. But the business logic integrity — "every ticket must correspond to a decremented seat" — is your responsibility to enforce.
The Lock Helps, But Doesn't Solve It
Row-level locking on the UPDATE prevents the -1 seats scenario from the opening story. But it creates a different failure mode: 0 rows affected + ticket still created. The lock changes how the bug manifests, not whether it exists.
Atomicity vs Isolation — The Distinction That Matters
This is where the deeper confusion lives. People hear "use transactions" and think the problem is solved. But transactions give you atomicity, and the race condition is an isolation problem.
| Property | What It Guarantees | What It Does NOT Guarantee |
|---|---|---|
| Atomicity | All operations in my transaction succeed together or fail together. If the INSERT fails, the UPDATE is rolled back. | Nothing about what other transactions can see or do while mine is running. |
| Isolation | Other transactions can't interfere with my view of the data (at the right isolation level). | Nothing about internal consistency of a single transaction — that's atomicity. |
The concert ticket race condition is an isolation problem:
- Both transactions individually execute correctly (atomicity is fine)
- They break because they interfere with each other's view of the data (isolation is violated)
- Under the default
READ COMMITTEDisolation level, both transactions can readavailable_seats = 1before either one writes - Each transaction sees a committed snapshot, which is consistent — but it's the same snapshot, and they both act on it
Timeline with READ COMMITTED:
T1 (Alice): BEGIN → READ seats=1 → → UPDATE seats=0 → COMMIT
T2 (Bob): BEGIN → → READ seats=1 → → UPDATE seats=-1 → COMMIT
Both reads return 1 because neither write has committed yet.
Both transactions see a consistent, committed state — they just see the SAME state.
Think of it this way: atomicity is about protecting you from yourself (your own transaction partially failing). Isolation is about protecting you from others (their transactions interfering with yours). The concert ticket problem is entirely about "others" — each transaction works perfectly in isolation, they just shouldn't both be allowed to act on the same stale snapshot.
A higher isolation level like SERIALIZABLE would catch this — the database would detect the conflict and abort one of the transactions. But higher isolation levels come with performance costs (more locking, more aborted transactions, more retries). That trade-off — correctness vs throughput — is the central tension of concurrency control, and every solution in this chapter navigates it differently.
Why This Distinction Matters in Interviews
When a candidate says "just wrap it in a transaction" and moves on, interviewers know they don't understand concurrency. Transactions solve atomicity — making sure partial failures don't corrupt data. But race conditions are about multiple transactions seeing the same state and conflicting. That requires isolation controls: locking, serializable transactions, or application-level coordination. These are different tools for a different problem.
Scaling Makes It Worse
Race conditions don't just exist — they get more probable as your system grows. The race window (the gap between check and use) stays constant at microseconds. But the number of concurrent operations passing through that window scales with traffic.
| Concurrent Users | Conflicts on Hot Resource |
|---|---|
| 10 | ~1 per hour |
| 100 | ~1 per minute |
| 1,000 | ~multiple per second |
| 10,000 | Every millisecond |
This is why contention is the hardest scaling problem in system design. Most scaling challenges get easier with money — buy more servers, add more replicas, expand the cache. But contention on a single shared resource gets worse as you grow, because more users means more concurrent operations fighting over the same rows.
Ticketmaster learned this the hard way during the Taylor Swift Eras Tour presale. 14 million users hit the same pool of seats simultaneously, and the system buckled — not because of raw traffic volume, but because of contention on shared inventory.
Robinhood experienced similar pain during the GameStop trading frenzy. Thousands of concurrent trades on the same stock created contention on inventory and balance records that no amount of horizontal scaling could fix, because the bottleneck was a single logical resource.
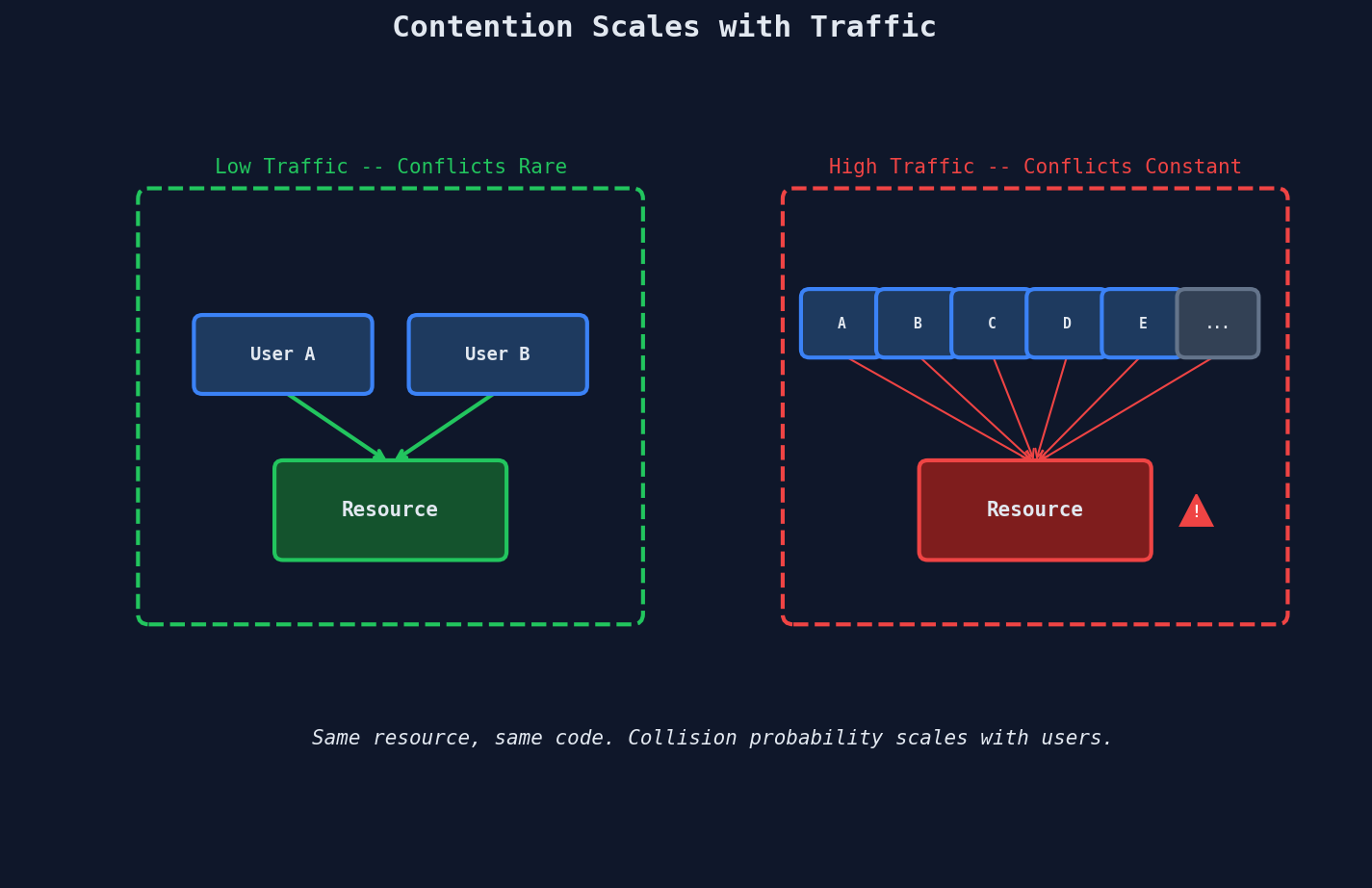
The resource itself doesn't change. The code doesn't change. The probability of collision changes — and probability at scale becomes certainty.
This is fundamentally different from the read-scaling problem we covered earlier in this course. Read bottlenecks can be solved by adding more replicas, more caches, more CDN nodes. You're distributing independent operations across more hardware. But write contention on a shared resource is about dependent operations — they all need to coordinate on the same piece of state, and adding hardware doesn't reduce that coordination cost. If anything, more app servers mean more concurrent writers funneling into the same database row.
Where Race Conditions Hide
Concert tickets make a clean example, but race conditions lurk in almost every system that handles concurrent writes. Here are the patterns to watch for:
| Domain | The Shared Resource | The Race |
|---|---|---|
| E-commerce | Inventory count | Two users buy the last item simultaneously |
| Banking | Account balance | Two withdrawals from the same account overlap |
| Social media | Like/follower count | Thousands of likes on a viral post lose some increments |
| Ride-sharing | Driver availability | Two riders get matched with the same driver |
| Healthcare | Appointment slot | Two patients book the same 2pm slot with Dr. Smith |
| Gaming | Leaderboard position | Two players submit scores simultaneously, one overwrite is lost |
The common thread: a single mutable resource that multiple actors try to read-then-write in a short window. Any time your system has this pattern, you have a potential race condition. The question isn't if it will happen, but when — and how bad the consequences are when it does.
The Lost Update Problem
A close cousin of the overselling race is the lost update: two transactions read a value, both modify it, and the second write overwrites the first. Example: two requests both read balance = 100, one adds $50, the other adds $30. Both write their result. Final balance: $130 or $150 — but it should be $180. One update is silently lost.
Quick Recap
| Concept | Key Takeaway |
|---|---|
| Race condition | Two operations read same state, both write based on stale data |
| TOCTOU | Time Of Check → gap → Time Of Use. The gap is where bugs live |
| 0 rows affected | A successful UPDATE that matches nothing — the transaction won't rollback |
| WITH/RETURNING fix | Structurally link INSERT to UPDATE's result, so INSERT can't run alone |
| Atomicity vs Isolation | Atomicity = all-or-nothing in one transaction. Isolation = transactions don't interfere with each other. Race conditions are isolation problems. |
| Contention at scale | Race window is constant, but collision probability scales with traffic |
Interview Tip
When the interviewer describes a system where multiple users can modify the same resource — seats, inventory, account balances, reservation slots — immediately identify it as a contention problem. Your next sentence should be about your concurrency control strategy: pessimistic locking, optimistic concurrency, or serialization through a queue. You'll learn each of these in the next four lessons.