Document & Key-Value Models
TL;DR
Document databases store data the way your application reads it — what is accessed together should be stored together. Key-value stores are the fastest possible lookup for simple access patterns. Both trade away joins and referential integrity for read performance and schema flexibility.
The Shipping Box Analogy
Imagine you run an online store. When a customer orders three items, you don't ship each item in a separate box from a separate warehouse and hope they all arrive together. You pack everything into one box, tape it shut, and ship it.
That's the document model. Instead of spreading an order across five normalized tables (orders, order_items, shipping_addresses, payment_methods, customer_details), you pack it all into one document:
{
"order_id": "ord_29481",
"customer": {
"name": "Alice Chen",
"email": "alice@example.com"
},
"items": [
{"product": "Mechanical Keyboard", "qty": 1, "price": 149.99},
{"product": "USB-C Cable", "qty": 2, "price": 12.99}
],
"shipping": {
"address": "123 Main St",
"city": "Seattle",
"method": "express"
},
"total": 175.97,
"status": "shipped"
}
One read gets you everything. No joins. No five-table query plan. Just fetch the document by its key and you're done.
The trade-off is obvious: if you need to update Alice's email across all her orders, you're updating hundreds of documents instead of one row in a customers table. ~~Denormalization is not optional~~ — it's the foundation of the document model.
The Core Principle: Access Pattern First
In the relational world, you model your data first and figure out queries later. In the document world, you flip it: start with how you'll query the data, then model it to serve those queries.
This is the fundamental mindset shift. A relational schema asks "what are the entities and relationships?" A document schema asks "what will the application screen look like?"
| Design Approach | Starting Question | Optimized For |
|---|---|---|
| Relational | What are my entities? | Flexibility, ad-hoc queries |
| Document | What are my access patterns? | Read performance, specific queries |
If your application has a product detail page that shows the product, its reviews summary, and the seller info — a document database lets you store all of that in one document and serve it in one read.
Embedding vs. Referencing
The most important design decision in document databases: do you embed related data inside the document, or store a reference (like a foreign key) and look it up separately?
Embed When:
- Data is accessed together (order + line items)
- The relationship is one-to-few (a user with 3 addresses)
- The embedded data doesn't change independently
- You need atomic updates on the whole structure
Reference When:
- Data is accessed independently (user profile vs. order history)
- The relationship is one-to-many or many-to-many (a user with 10,000 orders)
- The referenced data changes frequently (a product price that updates daily)
- Documents would grow unboundedly
// EMBEDDED — product with reviews summary
{
"product_id": "prod_123",
"name": "Wireless Mouse",
"price": 29.99,
"reviews_summary": {
"avg_rating": 4.3,
"count": 847,
"recent": [
{"user": "Bob", "rating": 5, "text": "Great mouse"},
{"user": "Carol", "rating": 4, "text": "Good value"}
]
}
}
// REFERENCED — order pointing to customer
{
"order_id": "ord_456",
"customer_id": "cust_789", // look up separately
"items": [
{"product_id": "prod_123", "qty": 1} // look up separately
]
}
Interview Tip
When you propose a document model, explicitly state what you're embedding and what you're referencing. "I'll embed the order items within the order document since they're always fetched together, but I'll reference the customer by ID since customer data is shared across orders and updated independently." This shows you understand the trade-off, not just the technology.
DynamoDB — Single-Table Design and Its Evolution
DynamoDB is Amazon's fully managed key-value and document database. Every item is accessed by a partition key (hash-based distribution) and an optional sort key (range queries within a partition).
For years, the community pushed single-table design — putting all entity types into one table and using generic attribute names (PK, SK, GSI1PK, GSI1SK) to enable multiple access patterns with overloaded indexes.
┌──────────────┬──────────────────┬──────────┬────────────┐
│ PK │ SK │ GSI1PK │ Data │
├──────────────┼──────────────────┼──────────┼────────────┤
│ USER#alice │ PROFILE │ — │ {name, ..} │
│ USER#alice │ ORDER#2025-01-15 │ ORD#1234 │ {total, ..}│
│ USER#alice │ ORDER#2025-02-03 │ ORD#1235 │ {total, ..}│
│ ORD#1234 │ ITEM#1 │ — │ {product,} │
│ ORD#1234 │ ITEM#2 │ — │ {product,} │
└──────────────┴──────────────────┴──────────┴────────────┘
This pattern (popularized by Rick Houlihan) works, but it has real costs: - Unreadable — you need a decoder ring to understand the table - Rigid — adding a new access pattern often requires a new GSI - Painful migrations — changing the key structure means rewriting every item
Houlihan himself has evolved his thinking. DynamoDB now supports 25 Global Secondary Indexes per table (up from 5), which makes index overloading less necessary. The modern recommendation is more nuanced: use single-table design when you genuinely need transactional operations across entity types, but don't be afraid to use multiple tables when it makes the schema clearer.
Key-Value Stores — Redis and the Speed Layer
A key-value store is the simplest possible data model: you have a key, you have a value, you do GET and SET. That's it.
Redis is the most widely used key-value store, and it's everywhere:
| Use Case | Key Pattern | Value | Why Redis? |
|---|---|---|---|
| Caching | user:123:profile |
JSON blob | Sub-millisecond reads, TTL expiration |
| Sessions | session:abc-def-ghi |
Session data | Fast lookups, automatic expiry |
| Rate Limiting | ratelimit:ip:1.2.3.4 |
Counter | Atomic increment, TTL for sliding window |
| Leaderboards | leaderboard:daily |
Sorted set | ZADD/ZRANGE for ranked queries |
| Pub/Sub | channel:notifications |
Messages | Real-time message broadcasting |
| Distributed Locks | lock:order:123 |
Lock token | SETNX for mutual exclusion |
Redis is not a primary database — it's an acceleration layer. Your source of truth lives in PostgreSQL or DynamoDB. Redis sits in front for hot data that needs sub-millisecond latency.
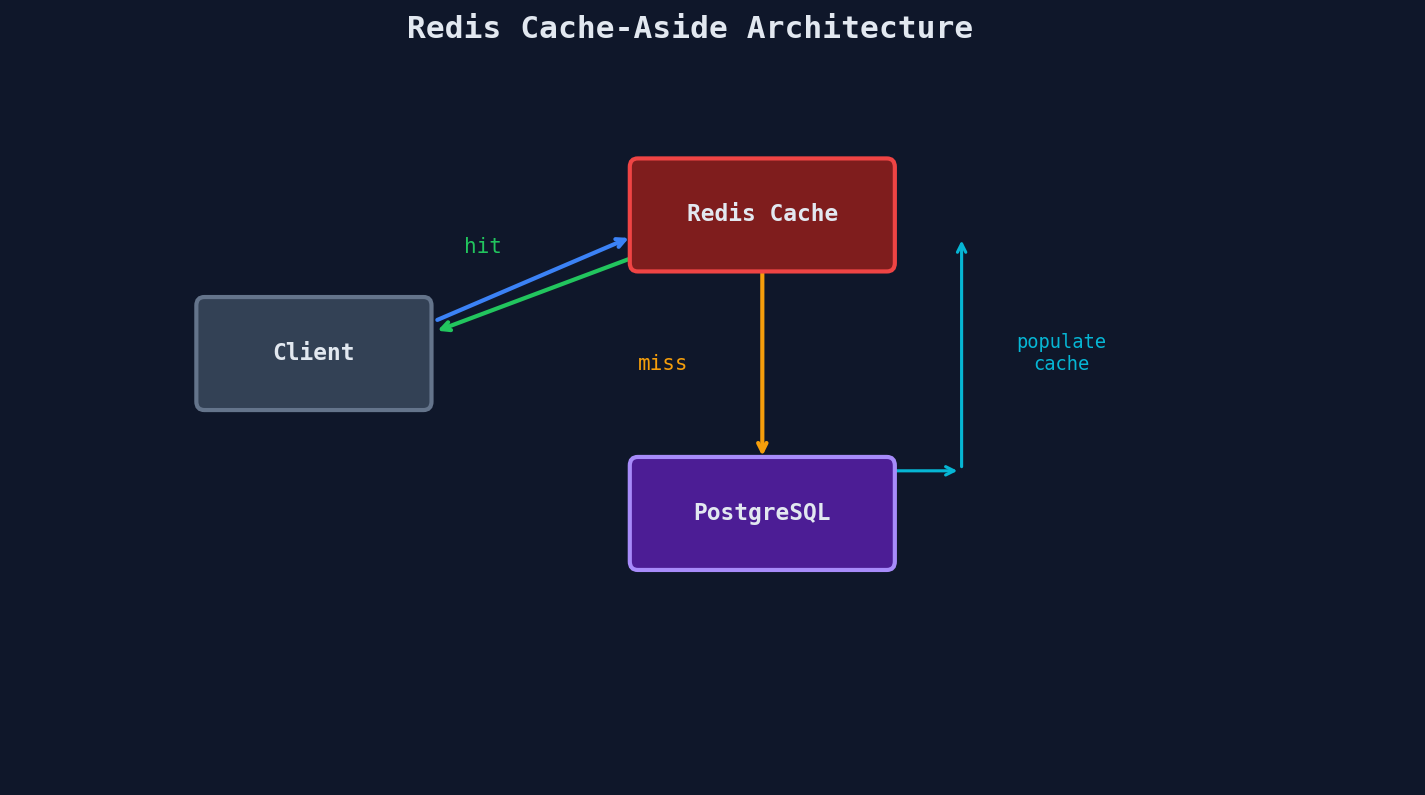
The pattern: check Redis first. On a cache hit, return immediately. On a cache miss, query the primary database, populate the cache with a TTL, then return. This is called ~~cache-aside~~ (or lazy loading), and it's the most common caching strategy.
def get_user(user_id):
key = f"user:{user_id}"
cached = redis.get(key)
if cached:
return json.loads(cached) # cache hit — sub-millisecond
user = db.execute("SELECT * FROM users WHERE id = %s", user_id)
redis.setex(key, 300, json.dumps(user)) # cache miss — populate with 5-min TTL
return user
def update_user(user_id, data):
db.execute("UPDATE users SET ... WHERE id = %s", user_id)
redis.delete(f"user:{user_id}") # invalidate — next read fetches fresh
Interview Tip
When you add Redis to a system design, always mention the cache invalidation strategy. "We'll use cache-aside with a 5-minute TTL. For writes, we'll invalidate the cache key immediately so the next read fetches fresh data." Cache invalidation is one of the two hard things in computer science — showing you've thought about it earns points.
When Document Makes Sense (And When It Doesn't)
| Document Wins | Document Loses |
|---|---|
| Data is naturally hierarchical (product catalogs, user profiles) | Complex joins across entities |
| Access patterns are well-defined and key-based | Ad-hoc reporting and analytics |
| Schema varies between items (CMS content, event data) | Referential integrity is critical |
| Read-heavy with predictable query patterns | Many-to-many relationships |
| Rapid iteration on schema (startups, prototyping) | Transactions spanning multiple documents |
MongoDB, Firestore, and DynamoDB each have their sweet spots, but they all share the same fundamental trade-off: you optimize reads by denormalizing, and you pay for it with write complexity and data consistency challenges.
A good rule of thumb: if you find yourself doing more than two lookups to serve a single API response in a document database, your data might be better modeled relationally. And if you find yourself doing five-table JOINs in a relational database to serve a single API response, your data might be better modeled as a document.
Quick Recap
| Concept | Key Point |
|---|---|
| Document Model | Store what's accessed together in one document; access-pattern-first design |
| Embedding | Nest related data inside the document; great for one-to-few relationships |
| Referencing | Store an ID and look it up separately; use for independent or frequently changing data |
| DynamoDB | Partition key + sort key; single-table design is powerful but not always necessary |
| Key-Value (Redis) | Simplest model; ideal for caching, sessions, rate limiting, leaderboards |
| Cache-Aside | Check cache first, populate on miss; always plan your invalidation strategy |
| Trade-Off | No joins means denormalization is mandatory; writes get harder so reads get faster |