Job Status and Progress
TL;DR
You told the user "we'll process this in the background." Now they want to know what's happening. Track job state in a database (pending, processing, completed, failed), push progress updates through Redis, and notify via the right channel: polling for simple UIs, SSE for real-time dashboards, WebSockets for bidirectional apps, and webhooks for B2B integrations. And always -- always -- make your workers idempotent, because a job that gets processed twice should produce the same result.
The Job Status Machine
Every background job moves through a finite set of states. Model this explicitly instead of treating status as a freeform string.
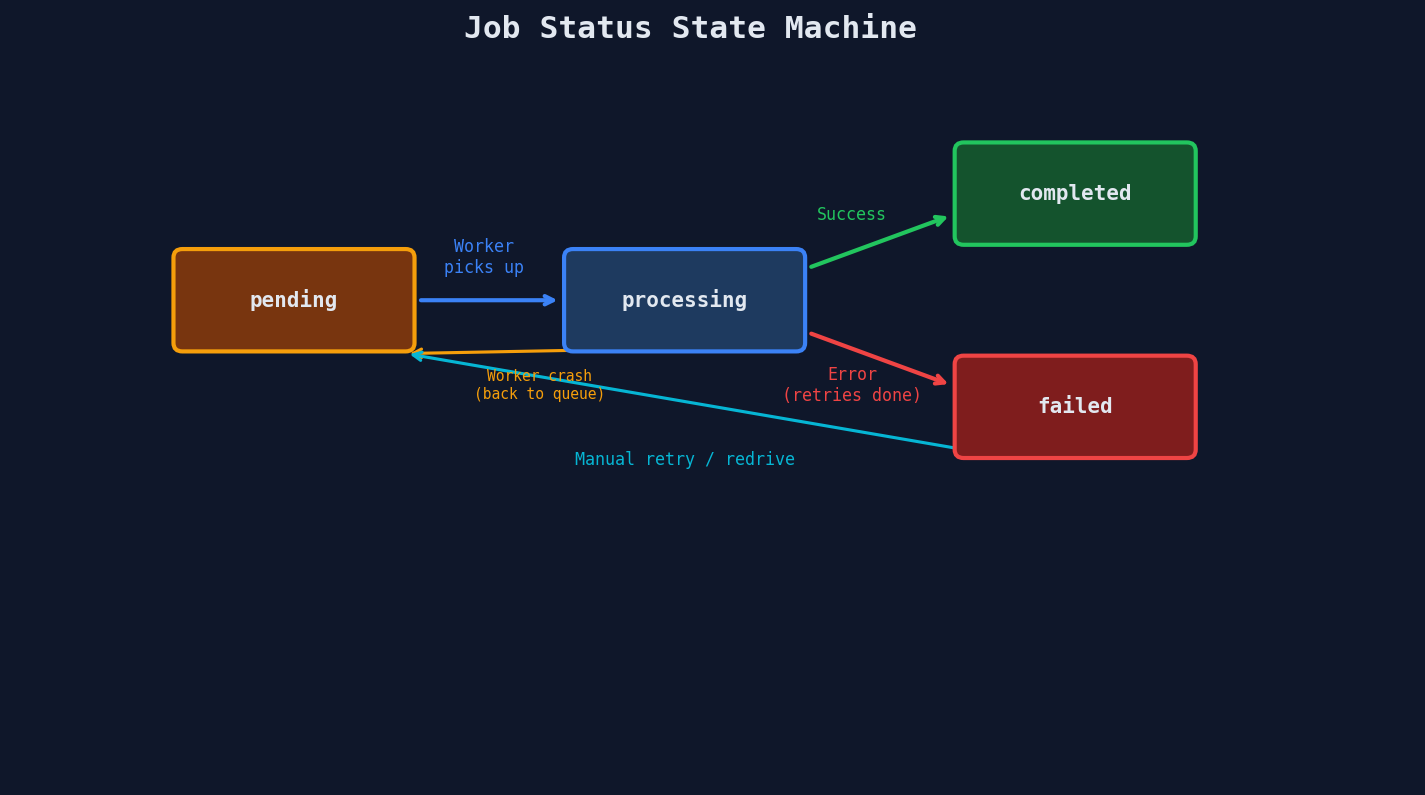
The Jobs Table
CREATE TABLE jobs (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
type VARCHAR(50) NOT NULL, -- 'report', 'video_transcode', 'csv_import'
status VARCHAR(20) NOT NULL DEFAULT 'pending',
payload JSONB NOT NULL, -- input data
result JSONB, -- output data (URL, stats, etc.)
error TEXT, -- last error message
attempts INT NOT NULL DEFAULT 0,
max_attempts INT NOT NULL DEFAULT 5,
priority INT NOT NULL DEFAULT 0,
progress INT DEFAULT 0, -- 0-100
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
started_at TIMESTAMPTZ,
completed_at TIMESTAMPTZ,
created_by UUID REFERENCES users(id),
CONSTRAINT valid_status CHECK (status IN ('pending', 'processing', 'completed', 'failed', 'cancelled'))
);
CREATE INDEX idx_jobs_status ON jobs(status) WHERE status IN ('pending', 'processing');
CREATE INDEX idx_jobs_created_by ON jobs(created_by, created_at DESC);
Partial index on active statuses
The WHERE status IN ('pending', 'processing') partial index keeps the index small. You might have millions of completed jobs but only a handful of active ones.
Job Lifecycle in Code
from datetime import datetime
from uuid import uuid4
class JobService:
def create_job(self, job_type: str, payload: dict, user_id: str) -> dict:
job_id = str(uuid4())
job = {
"id": job_id,
"type": job_type,
"status": "pending",
"payload": payload,
"attempts": 0,
"max_attempts": 5,
"progress": 0,
"created_at": datetime.utcnow(),
"created_by": user_id,
}
db.jobs.insert(job)
queue.send_message({"job_id": job_id})
return job
def start_job(self, job_id: str):
db.jobs.update(
{"id": job_id},
{"status": "processing", "started_at": datetime.utcnow(),
"attempts": db.raw("attempts + 1")}
)
def complete_job(self, job_id: str, result: dict):
db.jobs.update(
{"id": job_id},
{"status": "completed", "result": result,
"progress": 100, "completed_at": datetime.utcnow()}
)
def fail_job(self, job_id: str, error: str):
job = db.jobs.find_one({"id": job_id})
if job["attempts"] >= job["max_attempts"]:
db.jobs.update({"id": job_id}, {"status": "failed", "error": error})
else:
db.jobs.update({"id": job_id}, {"status": "pending", "error": error})
queue.send_message({"job_id": job_id}) # re-enqueue
The Status API
Clients need a way to check on their job. The standard pattern:
POST /api/reports/generate → 202 Accepted { "job_id": "abc123" }
GET /api/jobs/abc123 → 200 OK { "status": "processing", "progress": 45 }
GET /api/jobs/abc123 → 200 OK { "status": "completed", "result": { "url": "..." } }
@app.route("/api/jobs/<job_id>", methods=["GET"])
def get_job_status(job_id: str):
job = db.jobs.find_one({"id": job_id})
if not job:
return jsonify({"error": "Job not found"}), 404
response = {
"id": job["id"],
"type": job["type"],
"status": job["status"],
"progress": job["progress"],
"created_at": job["created_at"].isoformat(),
}
if job["status"] == "completed":
response["result"] = job["result"]
response["completed_at"] = job["completed_at"].isoformat()
if job["status"] == "failed":
response["error"] = job["error"]
response["attempts"] = job["attempts"]
return jsonify(response), 200
Progress Tracking That Actually Works
Writing progress to the database on every percentage update is wasteful -- the worker might update progress 100 times for a single job. Use Redis as a fast, ephemeral progress store.
Worker Writes Progress to Redis
import redis
r = redis.Redis(host="localhost", port=6379)
def process_csv_import(job_id: str, rows: list):
total = len(rows)
for i, row in enumerate(rows):
import_row(row)
# Update progress every 1% or every 100 rows
if i % max(1, total // 100) == 0:
progress = int((i / total) * 100)
r.setex(f"job:{job_id}:progress", 3600, progress) # expires in 1 hour
r.setex(f"job:{job_id}:progress", 3600, 100)
Client Gets Progress
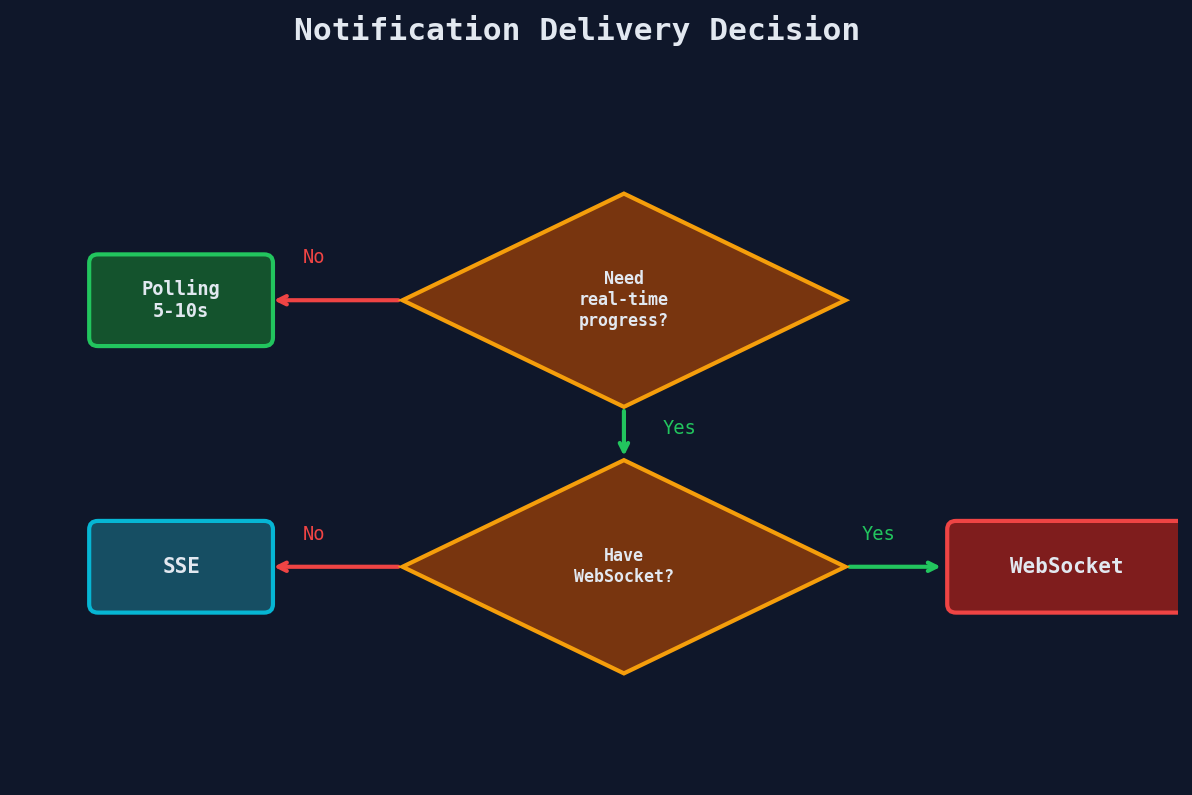
Three delivery mechanisms, each with different trade-offs.
Option 1: Polling (Simplest)
The client asks "are we there yet?" on a timer.
async function pollJobStatus(jobId: string): Promise<JobResult> {
const POLL_INTERVAL = 2000; // 2 seconds
while (true) {
const response = await fetch(`/api/jobs/${jobId}`);
const job = await response.json();
updateProgressBar(job.progress);
if (job.status === "completed") return job.result;
if (job.status === "failed") throw new Error(job.error);
await new Promise(resolve => setTimeout(resolve, POLL_INTERVAL));
}
}
| Pros | Cons |
|---|---|
| Dead simple | Wasted requests when nothing changed |
| Works through any proxy/CDN | Latency = poll interval / 2 on average |
| No persistent connections | Higher server load at scale |
Adaptive polling
Start with a 1-second interval, then back off to 5 seconds after 10 polls, then 15 seconds after 30 polls. Fast feedback initially, less waste over time.
Option 2: Server-Sent Events (SSE)
The server pushes updates to the client over a single HTTP connection. One-directional: server to client only.
from flask import Response, stream_with_context
@app.route("/api/jobs/<job_id>/stream")
def job_stream(job_id: str):
def generate():
last_progress = -1
while True:
# Check Redis for progress
progress = int(r.get(f"job:{job_id}:progress") or 0)
job = db.jobs.find_one({"id": job_id})
if progress != last_progress:
yield f"data: {json.dumps({'progress': progress, 'status': job['status']})}\n\n"
last_progress = progress
if job["status"] in ("completed", "failed"):
yield f"data: {json.dumps({'status': job['status'], 'result': job.get('result')})}\n\n"
return
time.sleep(1)
return Response(
stream_with_context(generate()),
mimetype="text/event-stream",
headers={"Cache-Control": "no-cache", "X-Accel-Buffering": "no"}
)
// Client-side
const eventSource = new EventSource(`/api/jobs/${jobId}/stream`);
eventSource.onmessage = (event) => {
const data = JSON.parse(event.data);
updateProgressBar(data.progress);
if (data.status === "completed") {
eventSource.close();
showResult(data.result);
}
};
eventSource.onerror = () => {
// SSE auto-reconnects by default
console.log("Connection lost, reconnecting...");
};
| Pros | Cons |
|---|---|
| Real-time updates | Holds a connection open per client |
| Auto-reconnection built in | Some proxies buffer/timeout SSE connections |
| Simple API (just HTTP) | Server to client only (no bidirectional) |
Option 3: WebSocket
Full bidirectional communication. Overkill for job progress, but appropriate if you already have WebSockets for other features (chat, live collaboration).
# Only use WebSocket if you already have it for other features.
# For job progress alone, SSE or polling is simpler.
@socketio.on("subscribe_job")
def handle_subscribe(data):
job_id = data["job_id"]
join_room(f"job:{job_id}")
# Worker emits updates via Redis pub/sub → SocketIO
def emit_progress(job_id: str, progress: int):
socketio.emit("job_progress", {"progress": progress}, room=f"job:{job_id}")
Which Delivery Mechanism to Choose
Notification on Completion
Progress tracking handles the "user is watching" case. But what if the user navigated away, closed their laptop, or is another service entirely?
Connected Users: In-App Notification
def complete_job(job_id: str, result: dict):
job_service.complete_job(job_id, result)
# Push to connected client via SSE/WebSocket
notify_client(job["created_by"], {
"type": "job_completed",
"job_id": job_id,
"message": "Your report is ready",
"download_url": result["url"]
})
Disconnected Users: Email or Push
def complete_job(job_id: str, result: dict):
job_service.complete_job(job_id, result)
user = db.users.find_one({"id": job["created_by"]})
# Try real-time first, fall back to email
if is_user_connected(user["id"]):
notify_client(user["id"], {"type": "job_completed", ...})
else:
send_email(
to=user["email"],
subject="Your report is ready",
body=f"Download: {result['url']}"
)
B2B Integrations: Webhooks
When another service is waiting for the result, use webhooks. The consuming service registers a URL, and you POST to it on completion.
def deliver_webhook(job_id: str, result: dict):
webhook_url = job["payload"]["webhook_url"]
payload = {
"event": "job.completed",
"job_id": job_id,
"result": result,
"timestamp": datetime.utcnow().isoformat()
}
# Sign the payload so the receiver can verify authenticity
signature = hmac.new(
webhook_secret.encode(),
json.dumps(payload).encode(),
hashlib.sha256
).hexdigest()
response = requests.post(
webhook_url,
json=payload,
headers={
"X-Webhook-Signature": signature,
"Content-Type": "application/json"
},
timeout=30
)
if response.status_code >= 400:
schedule_webhook_retry(job_id, attempt=1)
Stripe's webhook retry schedule is a good model for designing your own:
| Attempt | Delay After Previous |
|---|---|
| 1 | Immediate |
| 2 | 5 seconds |
| 3 | 30 seconds |
| 4 | 5 minutes |
| 5 | 30 minutes |
| 6 | 2 hours |
| 7 | 8 hours |
| 8 | 24 hours |
After 8 failed attempts over ~3 days, Stripe marks the endpoint as disabled and alerts the developer. Total retry window: ~34.5 hours.
Idempotent Execution: The Silent Killer
Here's a scenario that breaks systems:

The worker completed the work but crashed before telling the queue. The queue redelivers the message. The worker processes it again. The customer gets charged twice.
The Idempotency Key Pattern
Every job gets a unique key. Before processing, check if that key has already been processed.
def process_job(message: dict):
job_id = message["job_id"]
idempotency_key = f"processed:{job_id}"
# Check if already processed
if r.get(idempotency_key):
log.info(f"Job {job_id} already processed, skipping")
acknowledge(message)
return
# Process the job
result = do_work(message)
# Mark as processed BEFORE acknowledging the queue message
# Use a TTL longer than your max retry window
r.setex(idempotency_key, 86400 * 7, "done") # 7 days
# Store result
job_service.complete_job(job_id, result)
# Now acknowledge
acknowledge(message)
Database-Level Idempotency
For financial operations, Redis isn't durable enough. Use a database constraint:
CREATE TABLE processed_jobs (
idempotency_key VARCHAR(255) PRIMARY KEY,
job_id UUID NOT NULL,
result JSONB,
processed_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
-- In a transaction:
BEGIN;
-- This INSERT fails if the key already exists (duplicate processing attempt)
INSERT INTO processed_jobs (idempotency_key, job_id, result)
VALUES ('charge_cust123_ord456', 'job_789', '{"charge_id": "ch_abc"}');
-- Only reaches here if the INSERT succeeded (first time)
-- ... perform the actual charge ...
COMMIT;
At-least-once delivery means your workers WILL see duplicates
Every major queue system (SQS, RabbitMQ, Kafka) delivers at-least-once. Exactly-once is either impossible or extremely expensive. Design your workers to handle duplicates gracefully.
The Complete Picture
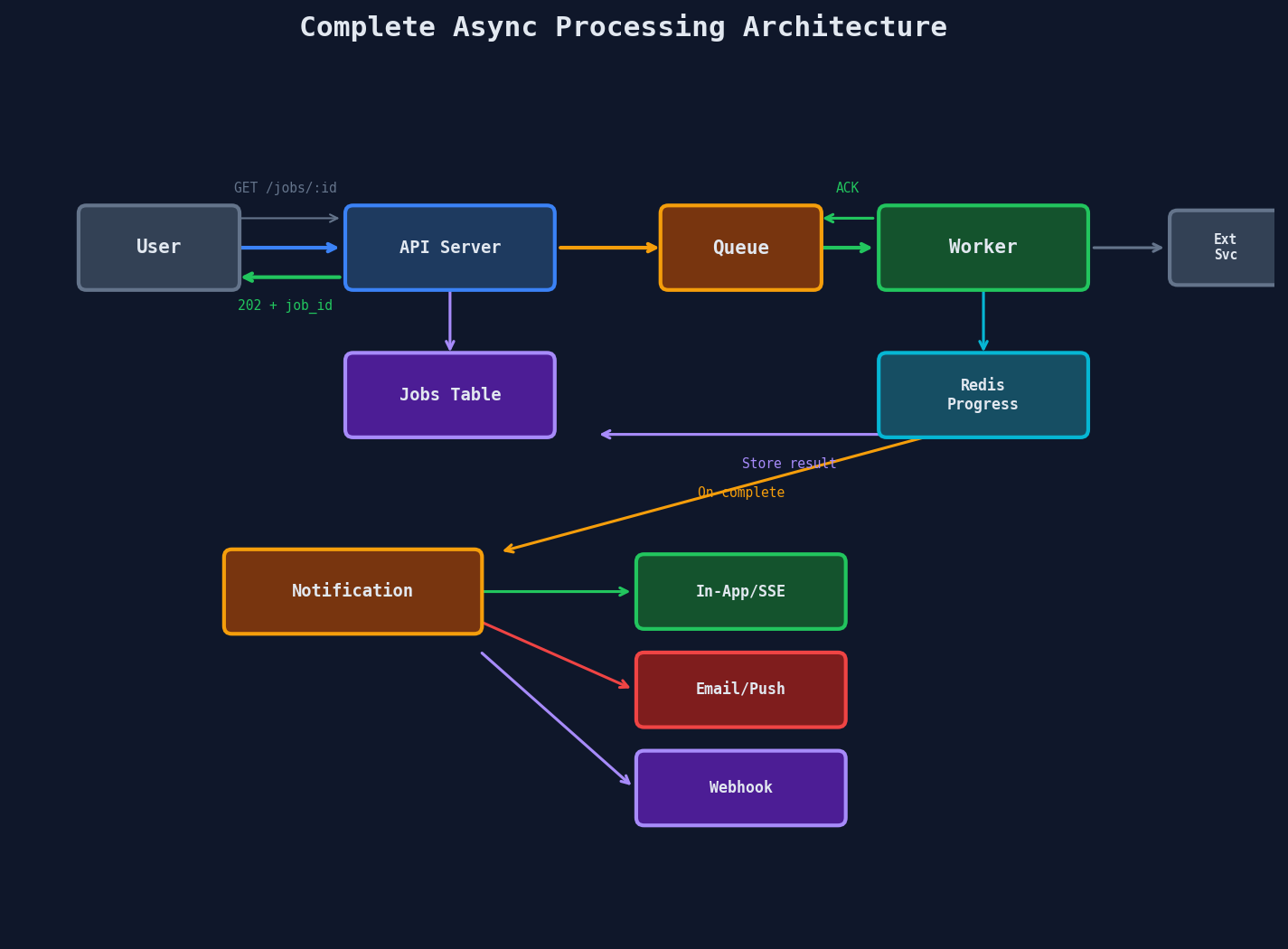
Key Takeaways
| Concept | Details |
|---|---|
| Job states | pending, processing, completed, failed, cancelled |
| Progress via Redis | Workers write setex, clients read via poll/SSE |
| Polling vs SSE vs WebSocket | Polling = simple; SSE = real-time, one-way; WebSocket = bidirectional |
| Webhook retries | Exponential schedule; disable endpoint after sustained failures |
| Idempotency | Check before processing; at-least-once delivery means duplicates happen |