Saga vs 2PC
TL;DR
When a single operation spans multiple services (charge payment + reserve inventory + ship), you need distributed coordination. 2PC (Two-Phase Commit) is correct but fragile and blocking. Sagas break the operation into local transactions with compensating actions for rollback. The outbox pattern solves the dual-write problem of updating a DB and publishing an event atomically. In most interviews, Sagas with orchestration is the answer they're looking for.
The Problem: Multi-Service Operations
In a monolith, placing an order is a single database transaction:
BEGIN;
INSERT INTO orders (...);
UPDATE inventory SET quantity = quantity - 1 WHERE ...;
INSERT INTO payments (...);
COMMIT;
All three operations share the same database. If the payment insert fails, the inventory update is rolled back. Atomicity is free.
In a microservices architecture, each operation lives in a different service with its own database. There is no shared transaction. If the payment service fails after the inventory service already decremented stock, you have an inconsistency that no single database can fix.
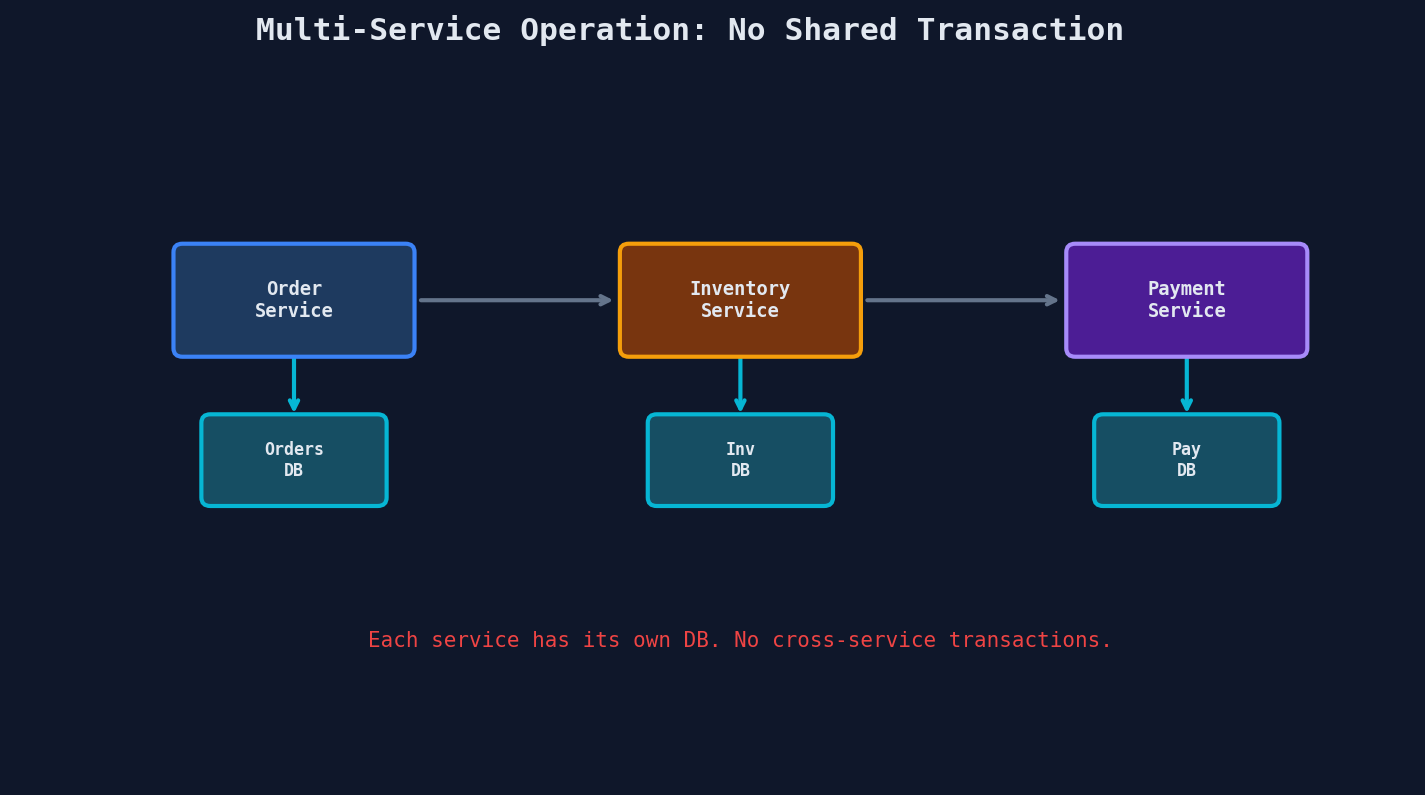
Two solutions exist: 2PC and Sagas. They make fundamentally different trade-offs.
Two-Phase Commit (2PC)
2PC is a protocol where a coordinator asks all participants to prepare, then tells them all to commit (or all to abort).
The Protocol
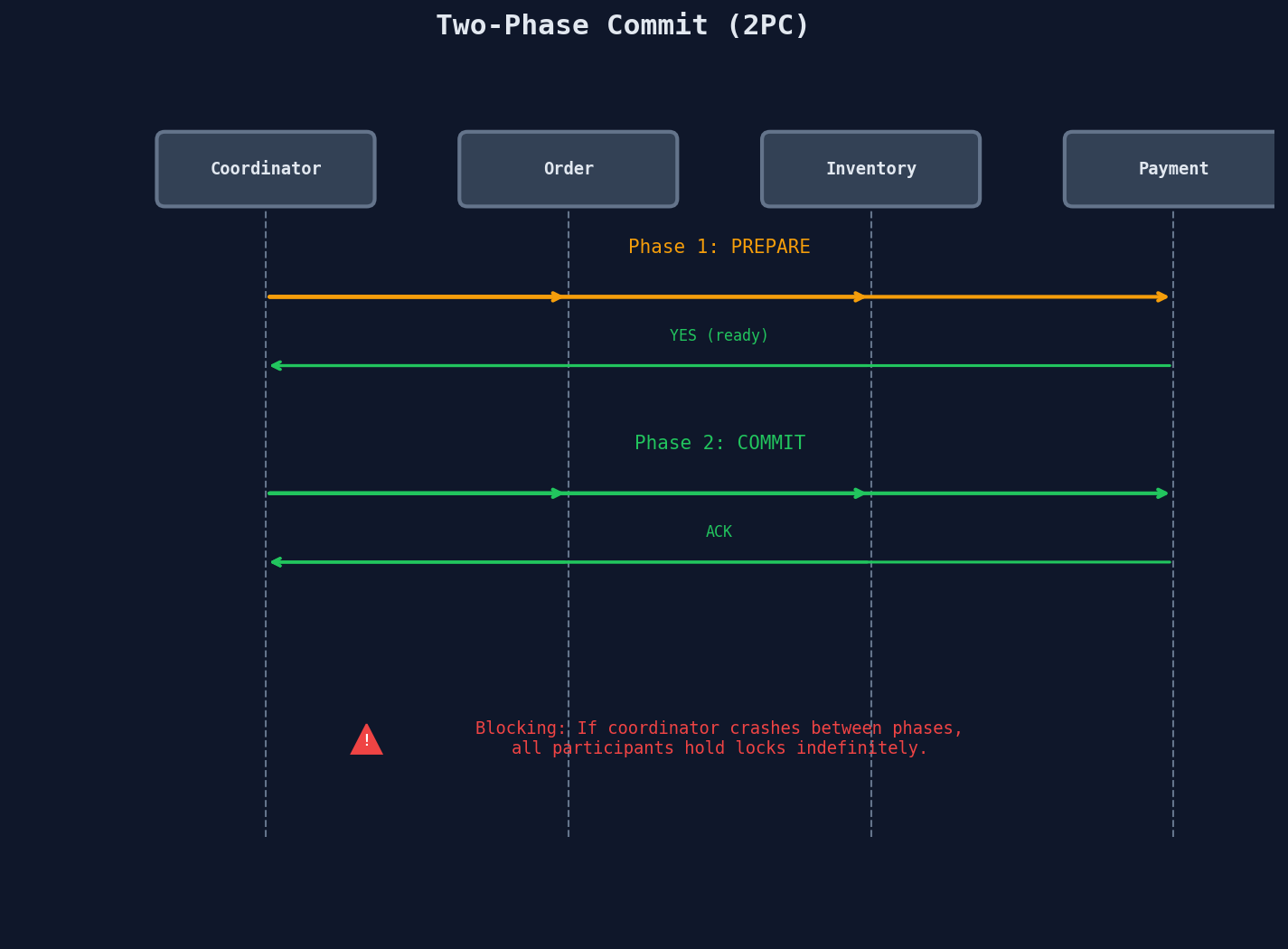
In Phase 1 (PREPARE), each participant does all the work — validates data, acquires locks, writes to a durable log — but does not commit. It votes YES ("I can commit if you tell me to") or NO ("something went wrong, abort").
In Phase 2 (COMMIT), if all participants voted YES, the coordinator tells everyone to commit. If any participant voted NO, the coordinator tells everyone to abort.
Why 2PC Is Fragile
The protocol is correct but has three critical problems:
| Problem | What Happens | Impact |
|---|---|---|
| Blocking | After voting YES in Phase 1, participants hold locks and wait for the coordinator's Phase 2 decision. They cannot proceed or abort on their own. | If the coordinator crashes between Phase 1 and Phase 2, participants hold locks forever (until manual intervention). Other transactions waiting on those locks pile up. |
| Single point of failure | The coordinator is a single process. If it dies, the entire protocol stalls. | Requires coordinator high availability (adds complexity), or risk total system freeze. |
| High latency | Two network round trips (PREPARE + COMMIT), and every participant holds locks for the full duration of both phases. | Under load, lock hold times increase contention across all participating databases. Throughput drops. |
Where 2PC Actually Works
2PC works well within a single database system. PostgreSQL uses 2PC internally for multi-table transactions — the database engine is both coordinator and participant, running on the same node with shared memory. No network latency, no coordinator failure risk.
It also works in tightly coupled systems with very few participants (2-3 databases on the same network) and low transaction volume. XA transactions in Java enterprise systems use 2PC across databases, and they work — but they don't scale.
2PC in the Real World
Google Spanner uses a variant of 2PC (with Paxos for coordinator replication) to achieve strong consistency across data centers. But Spanner controls the entire stack — hardware, network, TrueTime clocks. For most companies running standard databases over standard networks, 2PC across services is impractical.
The Saga Pattern
A Saga breaks a distributed operation into a sequence of local transactions, each in its own service. If any step fails, previously completed steps are compensated (undone) by running a reverse operation.
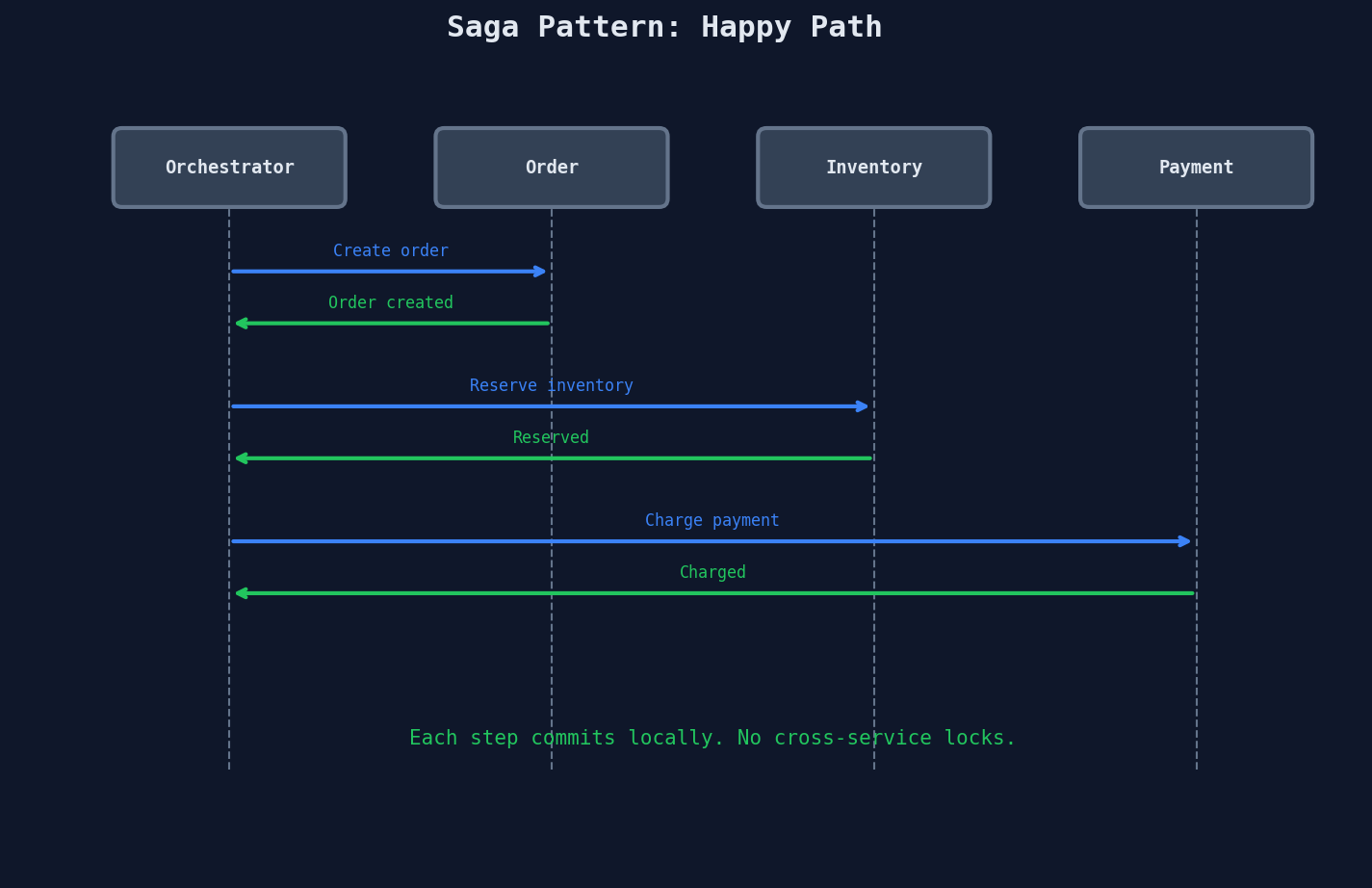
Happy Path
Failure Path — Compensation
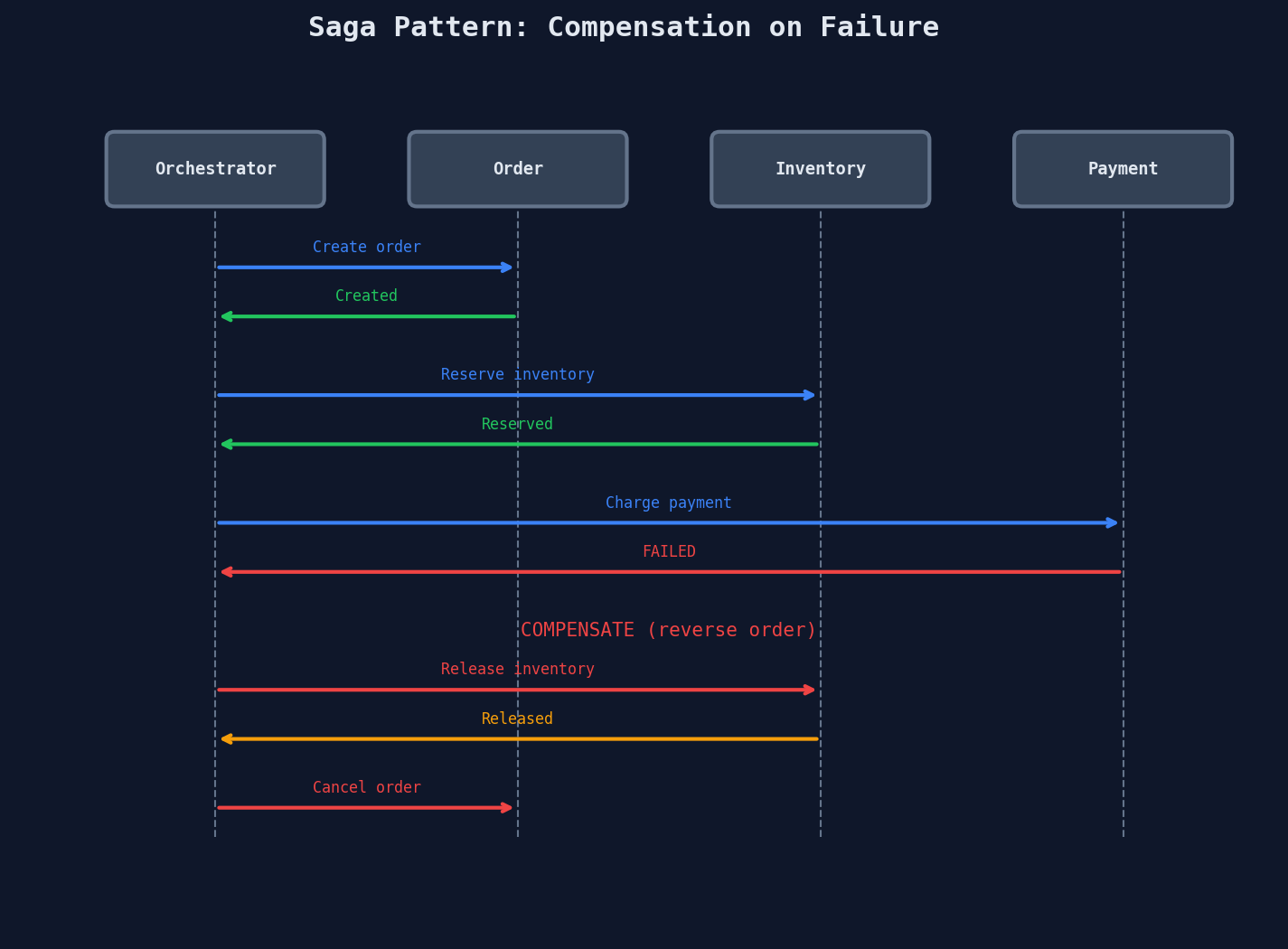
Each local transaction commits immediately in its own database. There are no cross-service locks. If step 3 fails, the orchestrator calls compensating actions for steps 2 and 1 — in reverse order.
Choreography vs Orchestration
There are two ways to coordinate a Saga.
Choreography: Events, No Coordinator
Each service publishes an event when it completes its step. The next service reacts to that event.
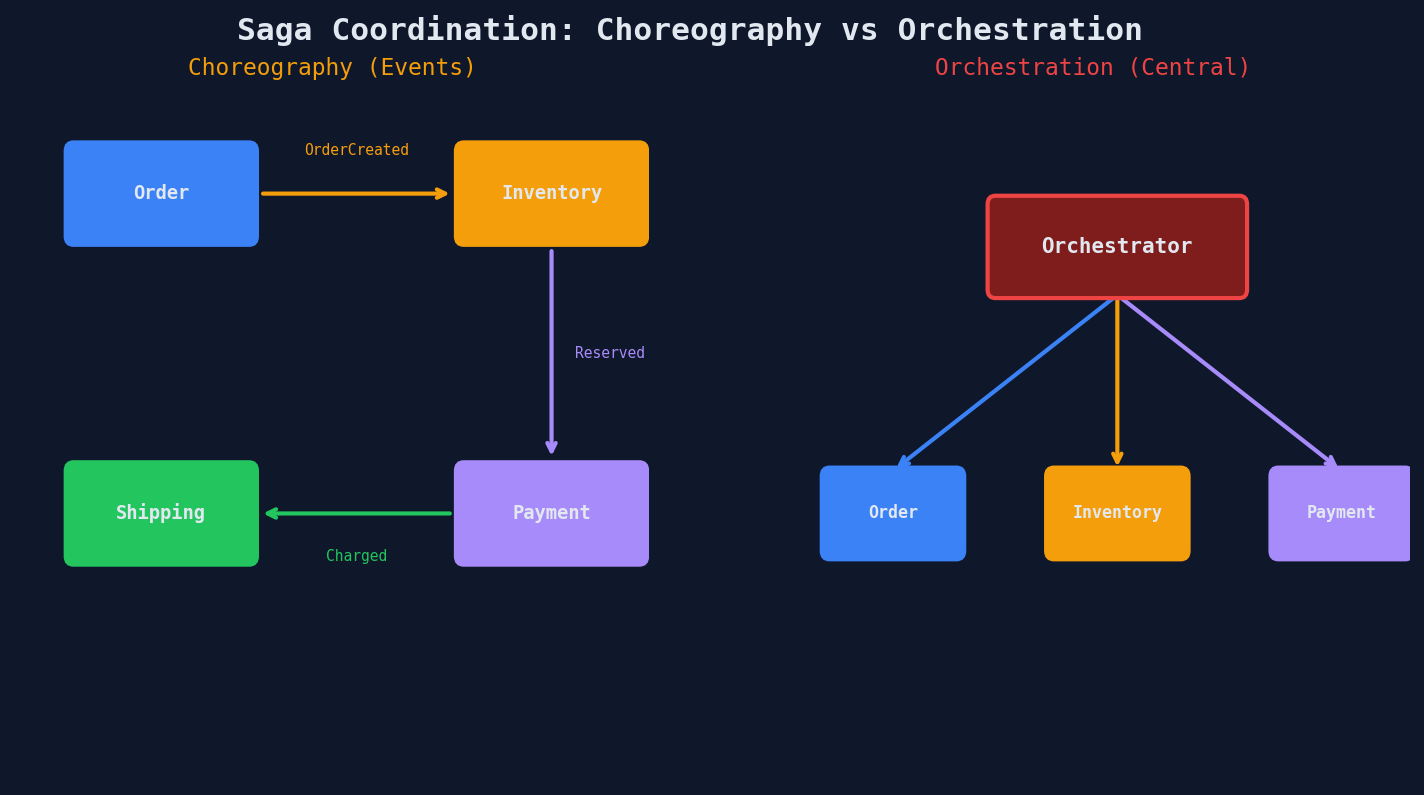
Choreography (top):
Pros: No single point of failure. Services are decoupled. Simple for 2-4 step flows.
Cons: Hard to understand the full flow — the logic is spread across services. Debugging requires correlating events across systems. Adding a new step means modifying multiple services. Circular dependencies can emerge.
Orchestration: Central Coordinator
A central orchestrator (a dedicated service or workflow engine) directs each step.
Pros: The entire flow is visible in one place. Easy to add, remove, or reorder steps. Clear ownership of the workflow logic.
Cons: The orchestrator is a dependency — if it goes down, no workflows execute (mitigate with HA). Can become a "god service" if not carefully scoped.
Which to Choose
| Factor | Choreography | Orchestration |
|---|---|---|
| Number of steps | 2-4 steps | 5+ steps |
| Flow complexity | Linear, no branching | Branching, retries, timeouts |
| Debuggability | Hard (distributed events) | Easy (centralized state machine) |
| Adding new steps | Modify multiple services | Modify the orchestrator only |
| Coupling | Low (event-driven) | Medium (orchestrator knows all services) |
For complex business flows — order placement, loan processing, trip booking — use orchestration. For simple event-driven reactions — "when a user signs up, send a welcome email" — choreography is sufficient.
Compensating Transactions Are Tricky
Not all compensations are equal. Some are trivial; others are painful or impossible.
| Step | Compensation | Difficulty |
|---|---|---|
| Create order record | Cancel order, set status to cancelled |
Easy — just a status update |
| Reserve inventory | Release reserved units back to available pool | Easy — reverse the decrement |
| Charge payment | Issue refund | Medium — refund takes days to process, generates support tickets, card network fees apply |
| Ship package | Recall shipment, arrange return | Hard — package may already be in transit, return shipping costs money, customer may refuse return |
| Send notification email | Send correction / apology email | Impossible to "unsend" — can only send a follow-up |
Order Your Steps Wisely
Place hard-to-compensate steps last in the Saga. If the payment charge is step 2 and shipping is step 3, a shipping failure means issuing a refund (medium difficulty). But if shipping is step 2 and payment is step 3, a payment failure means recalling a shipment (hard, expensive). Same operations, different ordering, dramatically different compensation cost.
The general rule: easy-to-undo steps first, hard-to-undo steps last. This minimizes the blast radius of failures.
The Banking Debate
A recurring question in community discussions: should banking systems use Sagas or 2PC?
The intuitive answer is 2PC — money demands absolute consistency. But the reality is different.
Most banks use Sagas with eventual consistency. Here's what a failed bank transfer actually looks like:
- Your account is debited. You get an SMS: "Rs 5,000 debited."
- The recipient's bank rejects the credit (wrong account number, daily limit exceeded, etc.).
- A compensation runs: your account is credited back. You get another SMS: "Rs 5,000 credited — refund for failed transfer."
The user experienced temporary inconsistency — their balance was wrong for a few minutes. But the system reached a consistent state eventually.
Indian UPI (Unified Payments Interface) handles millions of transactions per second using this exact pattern. When a UPI payment fails mid-transaction, the user sees a debit notification, then receives a refund within 5-30 minutes. This is a Saga with compensation, not 2PC.
PayPal uses both. Internal ledger updates use strong consistency (2PC-like within their database). But cross-system operations (merchant payouts, bank withdrawals) use Saga-style eventual consistency with reconciliation jobs.
Interview Framing
In interviews, start with Sagas. Say: "I'd use the Saga pattern with an orchestrator for this workflow." Only mention 2PC if the interviewer explicitly pushes for strict consistency — and even then, clarify that 2PC works within a single database but is impractical across services. This shows you understand the real-world trade-offs, not just textbook definitions.
The Dual-Write Problem
Every Saga implementation hits the same fundamental problem: you need to update your database AND publish an event, and those are two separate systems.
def process_order(order_id: str):
# Step 1: Update the database
db.execute("UPDATE orders SET status = 'confirmed' WHERE id = %s", order_id)
# Step 2: Publish event for the next service
kafka.send("order-events", {"type": "OrderConfirmed", "order_id": order_id})
# What if the process crashes between Step 1 and Step 2?
# Database is updated, but the event was never published.
# The next service never learns about the order.
# The Saga is stuck forever.
This is the dual-write problem: you need to write to two systems (DB + message broker) atomically, but there's no transaction spanning both. If the process crashes between the two writes, one succeeds and the other doesn't. Data diverges.
Two solutions: the Outbox Pattern and Change Data Capture (CDC).
The Outbox Pattern
Instead of publishing directly to Kafka, write the event to an outbox table in the same database transaction as your business data. A separate relay process reads the outbox and publishes to Kafka.
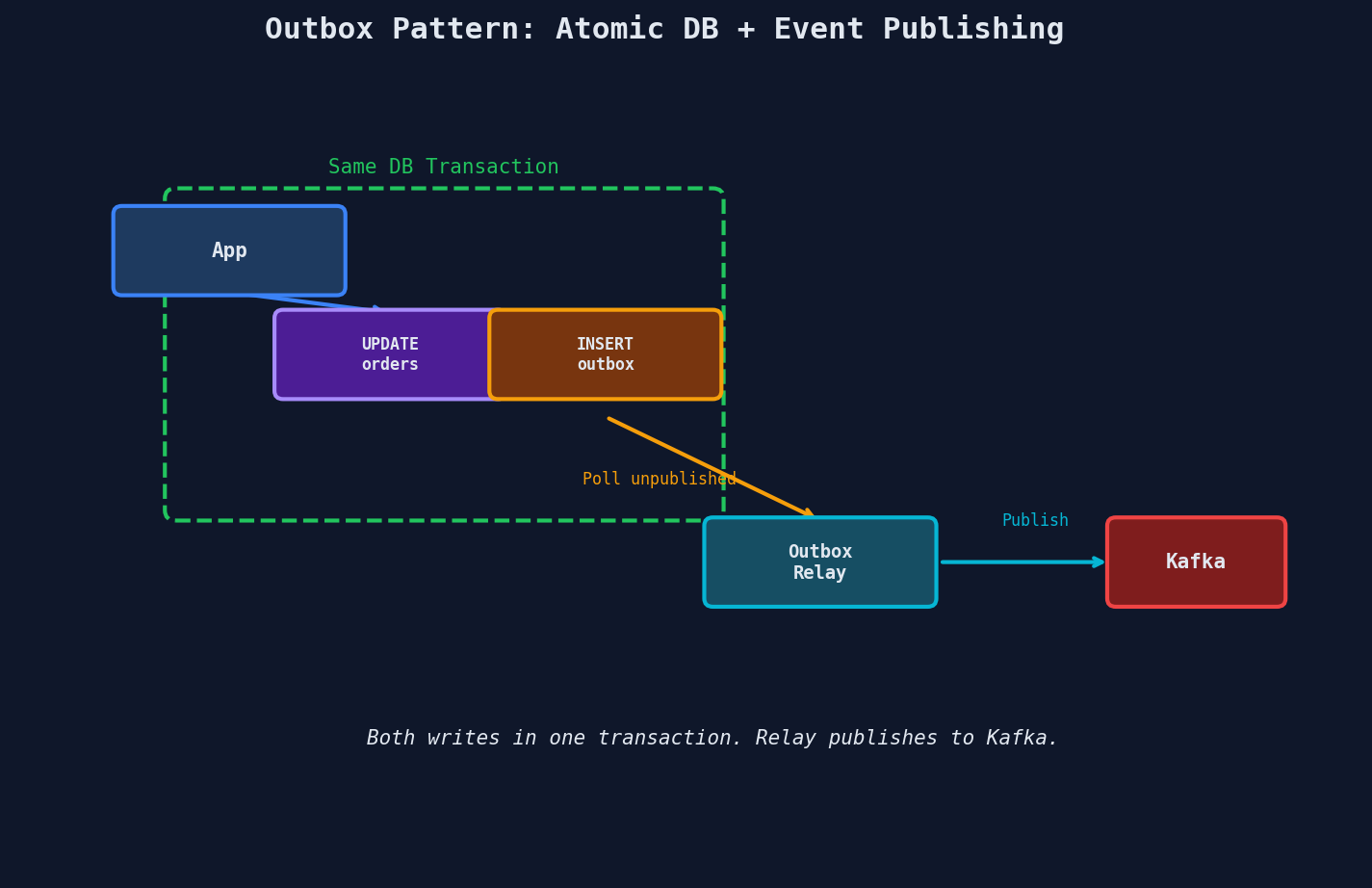
-- The outbox table
CREATE TABLE outbox (
id BIGSERIAL PRIMARY KEY,
event_type VARCHAR(100) NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMP DEFAULT NOW(),
published BOOLEAN DEFAULT FALSE
);
-- In the same transaction as your business logic
BEGIN;
UPDATE orders SET status = 'confirmed' WHERE id = 'order-123';
INSERT INTO outbox (event_type, payload) VALUES (
'OrderConfirmed',
'{"order_id": "order-123", "customer_id": "cust-456"}'
);
COMMIT;
The relay process polls the outbox table (or is triggered by notifications), publishes unpublished events to Kafka, and marks them as published. If the relay crashes, it restarts and picks up where it left off — unpublished events are still in the table.
Change Data Capture (CDC)
CDC eliminates the outbox table entirely. A tool like Debezium reads the database's write-ahead log (WAL) and streams changes directly to Kafka.
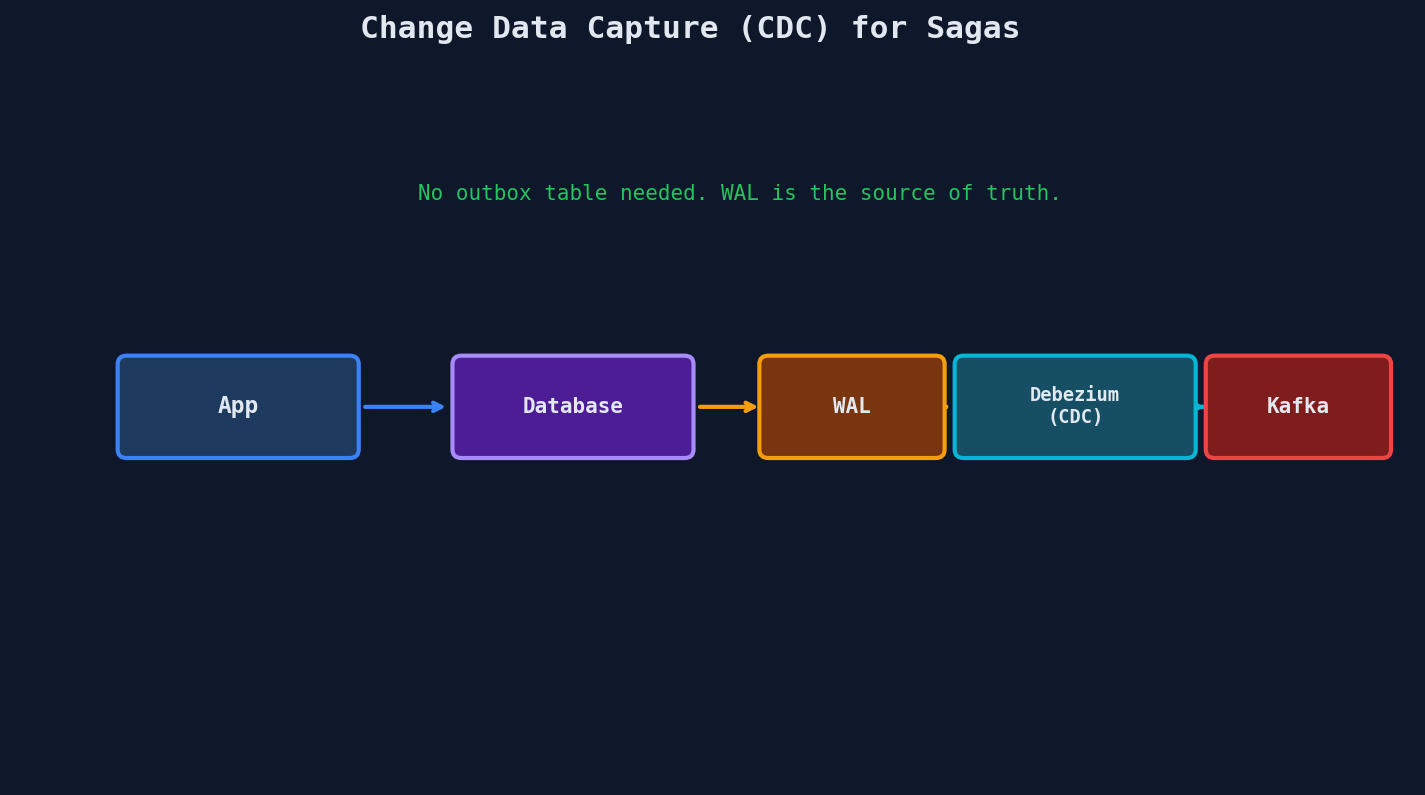
| Aspect | Outbox Pattern | CDC (Debezium) |
|---|---|---|
| Extra table | Yes — outbox table in your database |
No — reads the WAL directly |
| Application changes | Must insert into outbox in every transaction | None — works transparently |
| Relay process | Yes — you manage polling + publishing | Debezium manages it (with Kafka Connect) |
| Event schema control | Full control — you define the payload | Depends on table schema — less flexible |
| Operational complexity | Lower — just a table + simple poller | Higher — Debezium, Kafka Connect, WAL config |
| Delivery guarantee | At-least-once (relay retries on failure) | At-least-once (Debezium tracks WAL offset) |
The Dual-Write Problem Shows Up Everywhere
This isn't just a Saga concern. Any time your service needs to update a database AND notify another system — sending an email, updating a search index, invalidating a cache — you face the dual-write problem. Have the outbox pattern and CDC ready as answers. Interviewers love asking about this because it separates candidates who've built real distributed systems from those who haven't.
Proof Points
Real companies, real patterns:
-
Stripe uses idempotency keys with a 24-hour TTL. Every API call includes a client-generated key. If Stripe sees the same key twice within 24 hours, it returns the original result instead of processing again. This makes retries safe and is the backbone of their Saga-like payment flows.
-
Uber built Cadence (now open-sourced as Temporal) specifically to orchestrate ride lifecycle Sagas — matching riders, dispatching drivers, handling cancellations, processing payments. Each ride is a workflow with dozens of steps and compensations.
-
Amazon uses orchestrated Sagas across their order pipeline. The order placement flow touches inventory, payment, fraud detection, warehouse allocation, and shipping — each a separate service with its own database.
Quick Recap
| Concept | Key Takeaway |
|---|---|
| 2PC | Correct but blocking. Coordinator crash = participants frozen holding locks. Works within a single DB, not across services. |
| Saga | Sequence of local transactions with compensating actions. No cross-service locks. Eventual consistency. |
| Choreography | Event-driven, no coordinator. Simple flows (2-4 steps). Hard to debug. |
| Orchestration | Central coordinator directs steps. Complex flows (5+ steps). Easy to modify and monitor. |
| Compensation ordering | Hard-to-undo steps last. Minimizes blast radius of failures. |
| Dual-write problem | Can't atomically update DB + publish event. Outbox pattern or CDC solves it. |
| Outbox pattern | Write event to outbox table in same DB transaction. Relay publishes to Kafka. |
| CDC | Debezium reads WAL, streams to Kafka. No outbox table needed. |
Interview Tip
If the interviewer describes a multi-service operation — "the user places an order, we need to charge payment, reserve inventory, and schedule shipping" — say: "I'd use the Saga pattern with an orchestrator. Each service executes a local transaction. If any step fails, the orchestrator runs compensating actions in reverse order. For reliable event publishing, I'd use the outbox pattern to avoid dual-write issues." This is the answer they want 90% of the time. It shows you understand distributed transactions, compensation, and the practical pitfalls.