Dynamic Connectivity
Why DFS Falls Apart When Edges Keep Arriving
You have a graph with no edges. Edges arrive one at a time. After each edge, someone asks: "How many connected components? How large is the biggest?" If you re-run DFS after every edge, that's O(m * (n + m)) total work. For n = 200,000 and m = 200,000, that's 40 billion operations. Good luck.
DSU handles this in O(m * alpha(n)). Each edge is one unite call. No re-traversal. No rebuilding. The structure absorbs new edges incrementally.
The Problem: CSES Road Construction
Statement: There are N cities and M roads are being built one by one. After each road is built, report:
- The number of connected components.
- The size of the largest component.
Constraints: N, M <= 200,000. Each answer must be printed after processing each edge. This is an online problem -- you can't batch the queries.
Why DSU Is the Right Tool
DSU is inherently online. Each unite(a, b) call processes one edge and updates the structure permanently. No past information is lost, no future information is needed.
Compare with the alternatives:
| Approach | Per-edge cost | Total cost | Verdict |
|---|---|---|---|
| DFS from scratch | O(n + current edges) | O(m * n) | Too slow |
| BFS from scratch | O(n + current edges) | O(m * n) | Too slow |
| DSU | O(alpha(n)) | O(m * alpha(n)) | Fast |
💡 Key insight. DSU is a "monotone" data structure. It can merge sets but never split them. This makes it perfect for graphs where edges are only added, never removed.
Tracking Components and Max Size
We need two extra pieces of state beyond the basic DSU:
components: starts at N (every node is isolated). Decrements by 1 on each successful union.max_size: starts at 1. After a union, compare the new merged size against the current max.
We switch from union by rank to union by size here, because we need the actual component sizes.
int par[200005], sz[200005];
int components, max_size;
int find(int x) {
if (par[x] != x)
par[x] = find(par[x]);
return par[x];
}
void unite(int a, int b) {
a = find(a); b = find(b);
if (a == b) return;
if (sz[a] < sz[b]) swap(a, b);
par[b] = a;
sz[a] += sz[b];
components--;
max_size = max(max_size, sz[a]);
}
⚠ Gotcha. When
find(a) == find(b), the edge connects two nodes already in the same component. Don't decrementcomponents-- nothing merged.
Full Trace
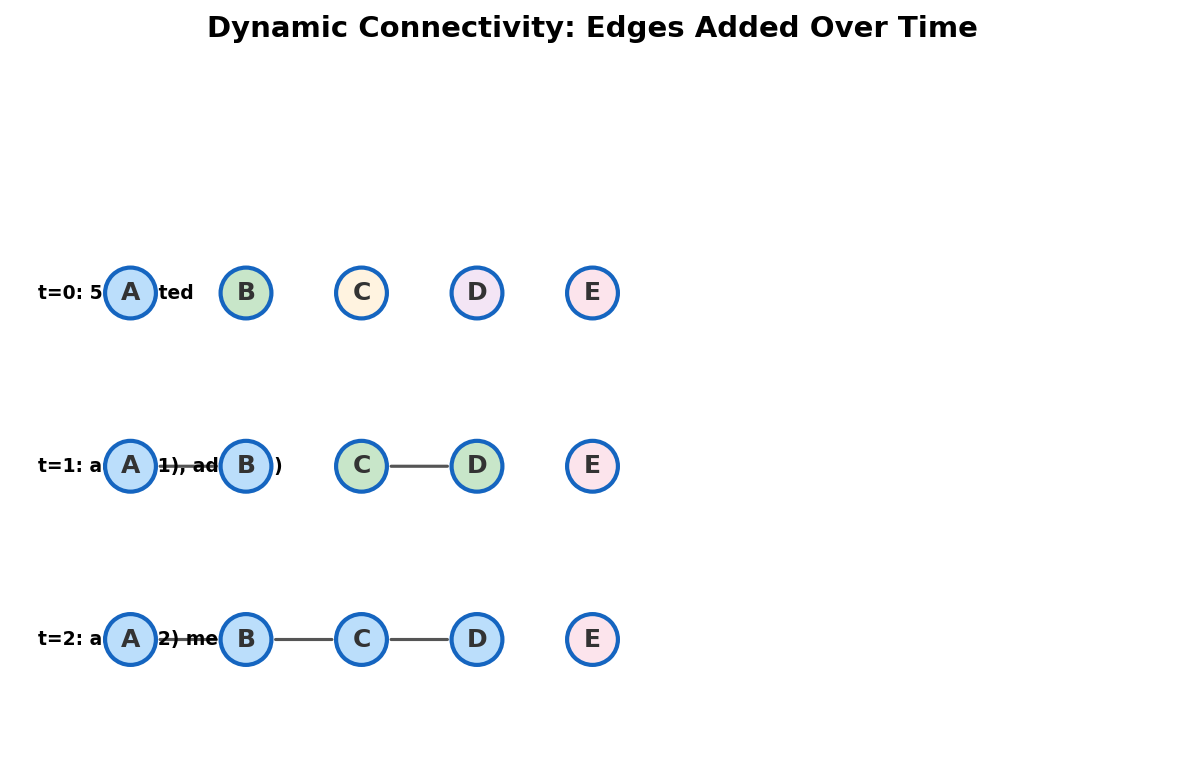
Start with 5 nodes, no edges. Process edges: (1,2), (3,4), (2,3), (5,5), (1,5).
| Edge | find(a) | find(b) | Merge? | par[] | sz[] | Components | Max Size |
|---|---|---|---|---|---|---|---|
| init | -- | -- | -- | [1,2,3,4,5] | [1,1,1,1,1] | 5 | 1 |
| (1,2) | 1 | 2 | yes | [1,1,3,4,5] | [2,1,1,1,1] | 4 | 2 |
| (3,4) | 3 | 4 | yes | [1,1,3,3,5] | [2,1,2,1,1] | 3 | 2 |
| (2,3) | 1 | 3 | yes | [1,1,1,3,5] | [4,1,2,1,1] | 2 | 4 |
| (5,5) | 5 | 5 | no | [1,1,1,3,5] | [4,1,2,1,1] | 2 | 4 |
| (1,5) | 1 | 5 | yes | [1,1,1,3,1] | [5,1,2,1,1] | 1 | 5 |
Note edge (5,5): a self-loop. Both endpoints have the same root, so no merge happens. Components and max size stay unchanged.
⚠ Gotcha. Self-loops and duplicate edges are common in competitive programming inputs. DSU handles them gracefully -- the
if (a == b) returncheck covers both cases.
Complete Solution
#include <bits/stdc++.h>
using namespace std;
int par[200005], sz[200005];
int components, max_size;
int find(int x) {
if (par[x] != x)
par[x] = find(par[x]);
return par[x];
}
void unite(int a, int b) {
a = find(a); b = find(b);
if (a == b) return;
if (sz[a] < sz[b]) swap(a, b);
par[b] = a;
sz[a] += sz[b];
components--;
max_size = max(max_size, sz[a]);
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n, m;
cin >> n >> m;
components = n;
max_size = 1;
for (int i = 1; i <= n; i++) {
par[i] = i;
sz[i] = 1;
}
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
unite(u, v);
cout << components << " " << max_size << "\n";
}
}
Clean. No adjacency list. No BFS queue. No visited array. Just two arrays doing all the work.
Union by Size vs Union by Rank
Lesson 1 used union by rank. Here we switched to union by size. When should you use which?
| Feature | Union by Rank | Union by Size |
|---|---|---|
| What it tracks | Upper bound on tree height | Exact count of nodes |
| When to use | Don't need component sizes | Need component sizes |
| Complexity | O(alpha(n)) | O(alpha(n)) |
| Extra info | None | Component size for free |
In practice, union by size is more versatile. You almost always want component sizes at some point. The rank variant is slightly more elegant for proofs but rarely matters in implementation.
💡 Key insight. You can use union by size everywhere. It gives the same asymptotic guarantees as union by rank, plus free size tracking.
Try It
The starter code provides the DSU with find already implemented. Fill in unite and the main loop.
Test case 1:
Test case 2:
Challenge: Extend the solution to also track the minimum node label in each component. Print components, max_size, and the minimum label of the largest component after each edge.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| CSES Road Construction | cses.fi/problemset/task/1676 | Easy |
| LC 1319 — Number of Operations to Make Network Connected | leetcode.com/problems/number-of-operations-to-make-network-connected | Medium |
| LC 2421 — Number of Good Paths | leetcode.com/problems/number-of-good-paths | Hard |