Distributed Counters
TL;DR
When 100K users like the same post simultaneously, a single counter row becomes a bottleneck. Sharded counters split one counter into N pieces. HyperLogLog counts unique items approximately in 12KB. CRDTs (Conflict-free Replicated Data Types) let distributed nodes merge data without coordination. Change Data Capture eliminates the dual-write problem by streaming database changes to downstream systems.
The Hottest Row in the Database
A post goes viral. 100,000 users are mashing the like button every second. Every single one of them is executing this:
Every request contends for the same row lock. The database serializes these updates one at a time — acquire lock, read value, increment, write value, release lock. Your database can handle 10K writes per second total, and this one row is consuming all of that capacity.
Here's the critical insight: this is a contention problem, not a throughput problem. Even if your database is sharded across 50 machines, it doesn't help. That one row lives on one machine, behind one lock. Adding more shards doesn't reduce contention on a single row.
The Bottleneck — One Row, One Lock, 100K Writers
┌──────────────┐
User 1 ────────►│ │
User 2 ────────►│ ROW LOCK │──── UPDATE likes = likes + 1
User 3 ────────►│ (post 12345)│ WHERE id = 12345
... ────────►│ │
User 100K ──────►│ WAITING... │
└──────────────┘
Result: 99,999 requests waiting. Timeouts. 502 errors. Pager goes off.
So how do you handle 100K concurrent writes to the same logical counter? You stop making it the same physical counter.
Sharded Counters — Divide and Conquer
The idea is dead simple: instead of one counter row, create N counter shards. Each write picks a random shard. Each read sums all shards.
-- Schema: one row per shard per post
CREATE TABLE counter_shards (
post_id BIGINT,
shard_id INT,
count BIGINT DEFAULT 0,
PRIMARY KEY (post_id, shard_id)
);
-- Pre-create 10 shards for a post
INSERT INTO counter_shards (post_id, shard_id, count)
VALUES (12345, 0, 0), (12345, 1, 0), ..., (12345, 9, 0);
Write path — pick a random shard, increment it:
UPDATE counter_shards
SET count = count + 1
WHERE post_id = 12345 AND shard_id = FLOOR(RANDOM() * 10);
Read path — sum across all shards:
With 10 shards, contention is reduced by ~10x. Each shard handles ~10K writes/sec instead of 100K. No single lock is overwhelmed.
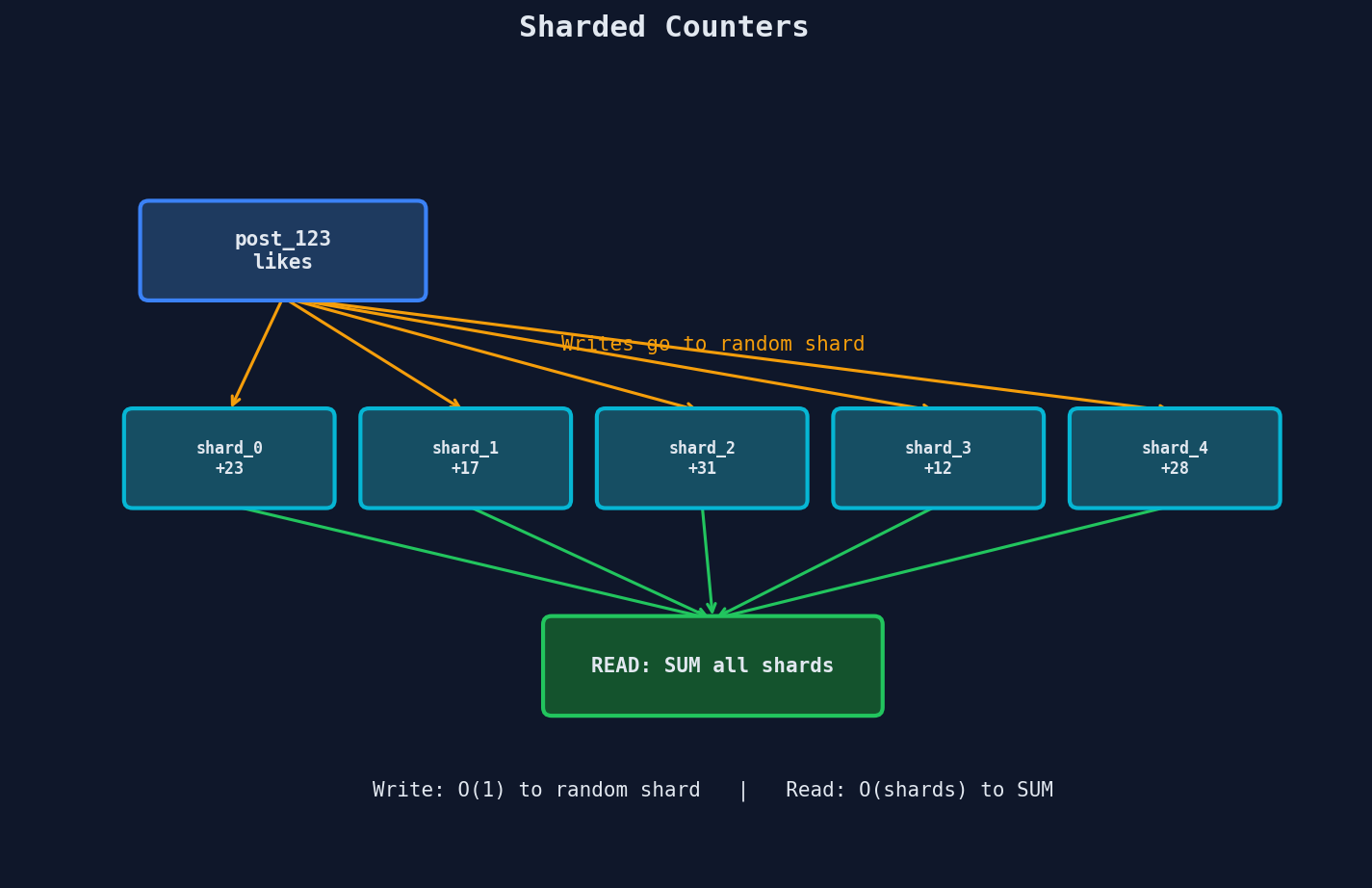
The trade-off is clean: writes are fast (each shard has low contention), reads are slightly slower (SUM query across N rows instead of reading one). For most use cases, you cache the SUM with a short TTL (1-5 seconds) and the read overhead disappears.
How many shards?
Start with 10. If contention is still too high, increase to 100. The number of shards should roughly match (expected_writes_per_sec / writes_per_sec_one_row_can_handle). Don't over-shard — more shards means more rows to sum on reads.
Google Cloud Firestore has built-in distributed counters using exactly this pattern. Their documentation recommends splitting counters into sub-documents when write rates exceed 1 write/sec per document.
HyperLogLog — Count Unique Items in 12KB
Different problem, same theme: counting at scale.
You want to know: "How many unique users visited this page?" The naive approach is storing every user ID in a set and counting the set size. That works until you have a billion unique visitors and your set consumes gigabytes of memory.
HyperLogLog (HLL) is a probabilistic data structure that can estimate the cardinality (unique count) of a dataset using a fixed 12KB of memory — regardless of whether you have 1,000 or 1 billion unique items.
The trade-off: accuracy. HLL has a standard error of ~0.81%. If the true count is 1,000,000 unique visitors, HLL reports somewhere between 991,900 and 1,008,100. For analytics dashboards, that's close enough.
How It Works (Intuition, Not Math)
Hash each incoming item to a binary string. Count the number of leading zeros. The more leading zeros you see, the more unique items you've probably processed — because getting many leading zeros requires many different hash outputs.
Hash("user_abc") → 00010110... → 3 leading zeros
Hash("user_def") → 00000011... → 6 leading zeros
Hash("user_xyz") → 01001010... → 1 leading zero
Max leading zeros seen = 6 → estimate ≈ 2^6 = 64 unique items
HLL uses 16,384 independent "registers" (buckets), each tracking the max leading zeros for items hashed to that bucket. The harmonic mean across all registers gives the final estimate. That's how you get 12KB (16,384 registers x 6 bits each) and sub-1% error. You don't need to know the math for interviews — just the intuition and the trade-offs.
Redis HyperLogLog in Practice
PFADD page:12345:visitors "user_abc"
PFADD page:12345:visitors "user_def"
PFADD page:12345:visitors "user_abc" -- duplicate, automatically ignored
PFCOUNT page:12345:visitors → 2 (approximately)
-- Merge HLLs from different time periods
PFMERGE page:12345:visitors:total
page:12345:visitors:monday
page:12345:visitors:tuesday
page:12345:visitors:wednesday
PFCOUNT page:12345:visitors:total → merged unique count
When to Use (and When Not To)
| Exact Counting (SET) | HyperLogLog | |
|---|---|---|
| Memory | O(n) — grows with data | 12KB fixed |
| Accuracy | 100% exact | ~99.19% (0.81% error) |
| Speed | O(1) add, O(n) count | O(1) add, O(1) count |
| Can list items? | Yes | No — only the count |
| Merge support | Union of sets (expensive) | PFMERGE (cheap) |
Use HyperLogLog for
Unique visitor counts, unique search queries, cardinality estimation, "approximately how many distinct X" questions.
Do NOT use HyperLogLog for
Exact counts, financial data, billing metrics, anything where 0.81% error has real consequences. If someone asks "how many transactions did we process?" and the answer affects an invoice — use exact counting.
Count-Min Sketch — Who's Hogging the Resources?
Another probabilistic structure worth knowing: the Count-Min Sketch.
Problem: "How many times did each URL get accessed in the last hour?" You have billions of requests and millions of unique URLs. Tracking exact counts per URL requires a massive hash map.
A Count-Min Sketch uses a fixed-size matrix with multiple hash functions. Each item is hashed to one cell in each row, and that cell is incremented. To query the count of an item, you hash it to each row and take the minimum value across rows.
Count-Min Sketch (3 rows × 8 columns)
Item: "/api/users"
Hash1("/api/users") → column 3
Hash2("/api/users") → column 7
Hash3("/api/users") → column 1
Query: min(row1[3], row2[7], row3[1]) → estimated frequency
It can overcount (hash collisions inflate values) but never undercount. The minimum across rows minimizes the collision impact.
Use cases: heavy hitter detection (find the top-N most frequent items), rate limiting (has this IP exceeded K requests?), trending topic detection. You don't need to understand the math deeply — just know it exists, what it's for, and that it trades accuracy for fixed memory.
| Exact (HashMap) | Count-Min Sketch | |
|---|---|---|
| Memory | O(n) — one entry per unique key | Fixed size (e.g., 1MB) |
| Accuracy | Exact | Approximate (overcounts possible) |
| Supports deletion? | Yes | No (can use Count-Min-Log variant) |
| Best for | Small keyspaces | Massive keyspaces, streaming data |
CRDTs — Data Structures That Merge Themselves
Everything so far assumes a single database. What happens when you have multiple databases in different regions, all accepting writes independently?
Traditional approach: elect a leader, route all writes through it, replicate to followers. This works, but writes from Tokyo to a leader in Virginia add 150ms+ of latency. For some applications, that's unacceptable.
CRDTs (Conflict-free Replicated Data Types) are data structures specifically designed so that any two replicas can be merged without coordination, and the result always converges to the same state. No locks. No consensus protocol. No central authority.
G-Counter (Grow-Only Counter)
The simplest CRDT. Each node maintains its own counter. The total is the sum across all nodes. To merge, take the max value per node.
Node A increments locally: {A: 5, B: 0, C: 0} → Total = 5
Node B increments locally: {A: 0, B: 3, C: 0} → Total = 3
Node C increments locally: {A: 0, B: 0, C: 7} → Total = 7
Merge (take max per node): {A: 5, B: 3, C: 7} → Total = 15 ✓
Why does this work? Each node only increments its own slot. The max operation is idempotent — merging the same state twice doesn't change the result. You can merge in any order, at any time, and always get the same answer.
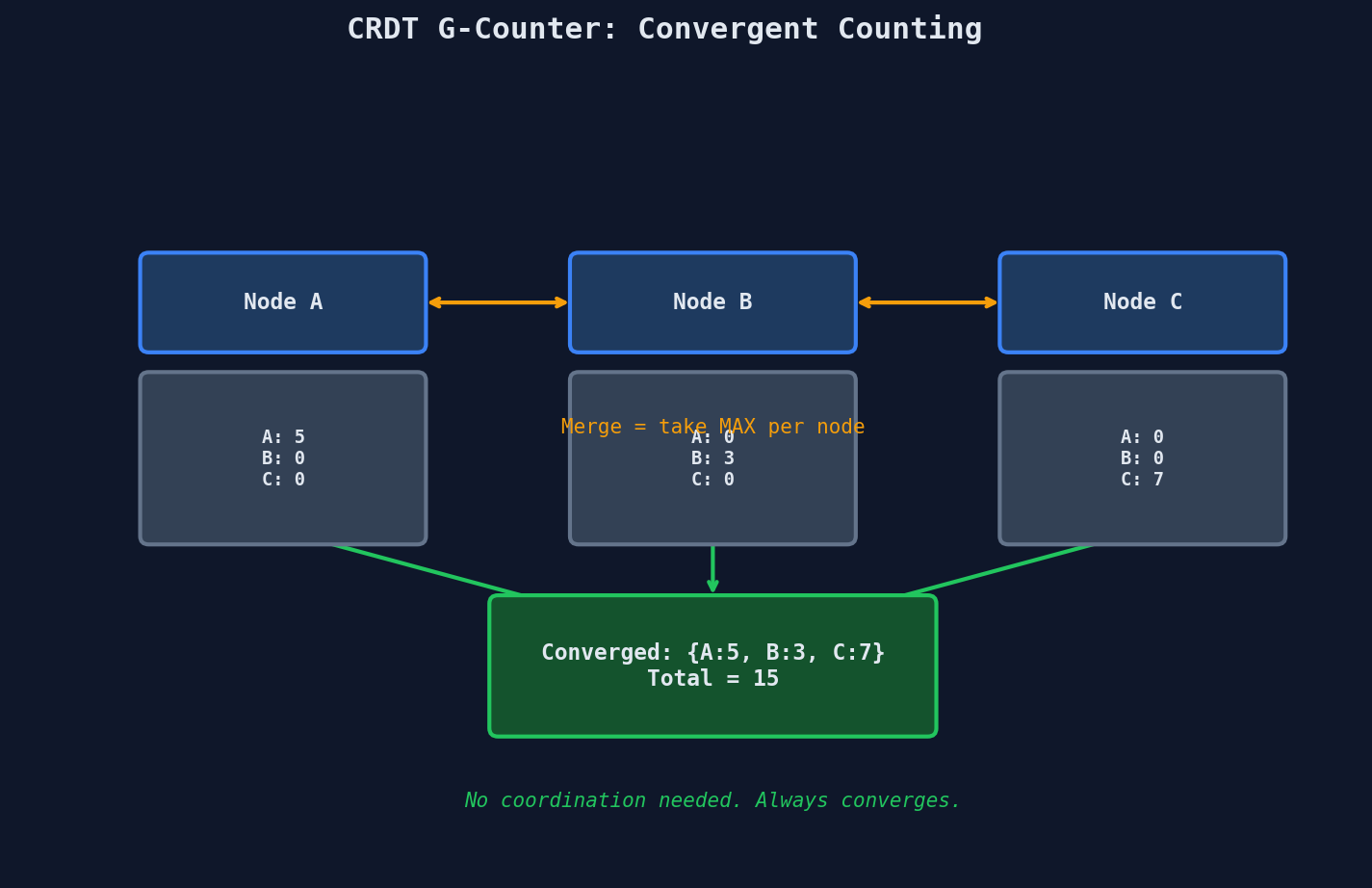
PN-Counter (Positive-Negative Counter)
A G-Counter can only go up. What if you need decrements too (likes and unlikes)?
A PN-Counter is simply a pair of G-Counters: one for increments (P), one for decrements (N). The actual value is sum(P) - sum(N).
P-Counter (increments): {A: 10, B: 5, C: 8} → sum = 23
N-Counter (decrements): {A: 2, B: 1, C: 0} → sum = 3
Value = 23 - 3 = 20
Each counter merges independently using the same max-per-node rule. Subtraction gives you the net count.
LWW-Register (Last-Writer-Wins)
For storing a single value (not a counter), the LWW-Register attaches a timestamp to each write. When merging, the value with the highest timestamp wins.
Node A writes: ("Alice", timestamp=1000)
Node B writes: ("Bob", timestamp=1002)
Merge → "Bob" wins (higher timestamp)
Simple. But lossy — Alice's write is silently discarded. If two nodes write at the exact same timestamp, you need a tiebreaker (e.g., node ID). LWW is fine for "last profile update wins" but dangerous for anything where you can't afford to lose writes.
OR-Set (Observed-Remove Set)
A set where you can add and remove elements across multiple nodes without conflicts. Each add operation gets a unique tag. A remove only removes the specific tags it has seen. This means concurrent add + remove doesn't lose the add.
This is the CRDT behind collaborative editing — you can add and remove items from a shared list across multiple replicas, and everything converges correctly.
When CRDTs Shine
| Scenario | Traditional (Leader-Based) | CRDTs |
|---|---|---|
| Write latency | Round-trip to leader | Local write, instant |
| Availability during partition | Writes blocked | Writes continue |
| Conflict resolution | Manual or app-level | Automatic by design |
| Complexity | Lower | Higher (limited data types) |
| Data types supported | Anything | Only CRDT-compatible types |
Redis Enterprise uses CRDTs for active-active replication across data centers, enabling sub-millisecond writes in every region. Figma uses CRDTs to power real-time collaborative design, where dozens of designers edit the same file simultaneously without conflicts.
Interview Pattern
CRDTs are the answer when the interviewer asks "How do you handle writes in multiple regions without a single leader?" You don't need to implement them from scratch — just explain the concept: each node writes locally, data structures are designed so any merge order produces the same result.
Change Data Capture — Solving the Dual-Write Problem
One of the most common mistakes in distributed systems: the dual write.
Your application needs to update the database AND do something else — update the search index, invalidate a cache, send an analytics event. So you write code like this:
def create_order(order):
db.insert(order) # Step 1: write to database
search.index(order) # Step 2: update search index
cache.invalidate("orders") # Step 3: invalidate cache
kafka.publish("order.created", order) # Step 4: publish event
What happens when step 1 succeeds but step 3 fails? The database has the order, the search index has it, but the cache is stale and no event was published. You're now inconsistent across systems with no easy way to detect or fix it.
The Dual-Write Problem
Any time you write to two different systems in a non-atomic operation, you risk partial failure. You can't wrap a database write and a Kafka publish in the same transaction — they're different systems with different transactional guarantees.
CDC to the Rescue
Change Data Capture flips the model: write to the database only. A CDC tool reads the database's transaction log (WAL in Postgres, binlog in MySQL) and streams every change to downstream systems.
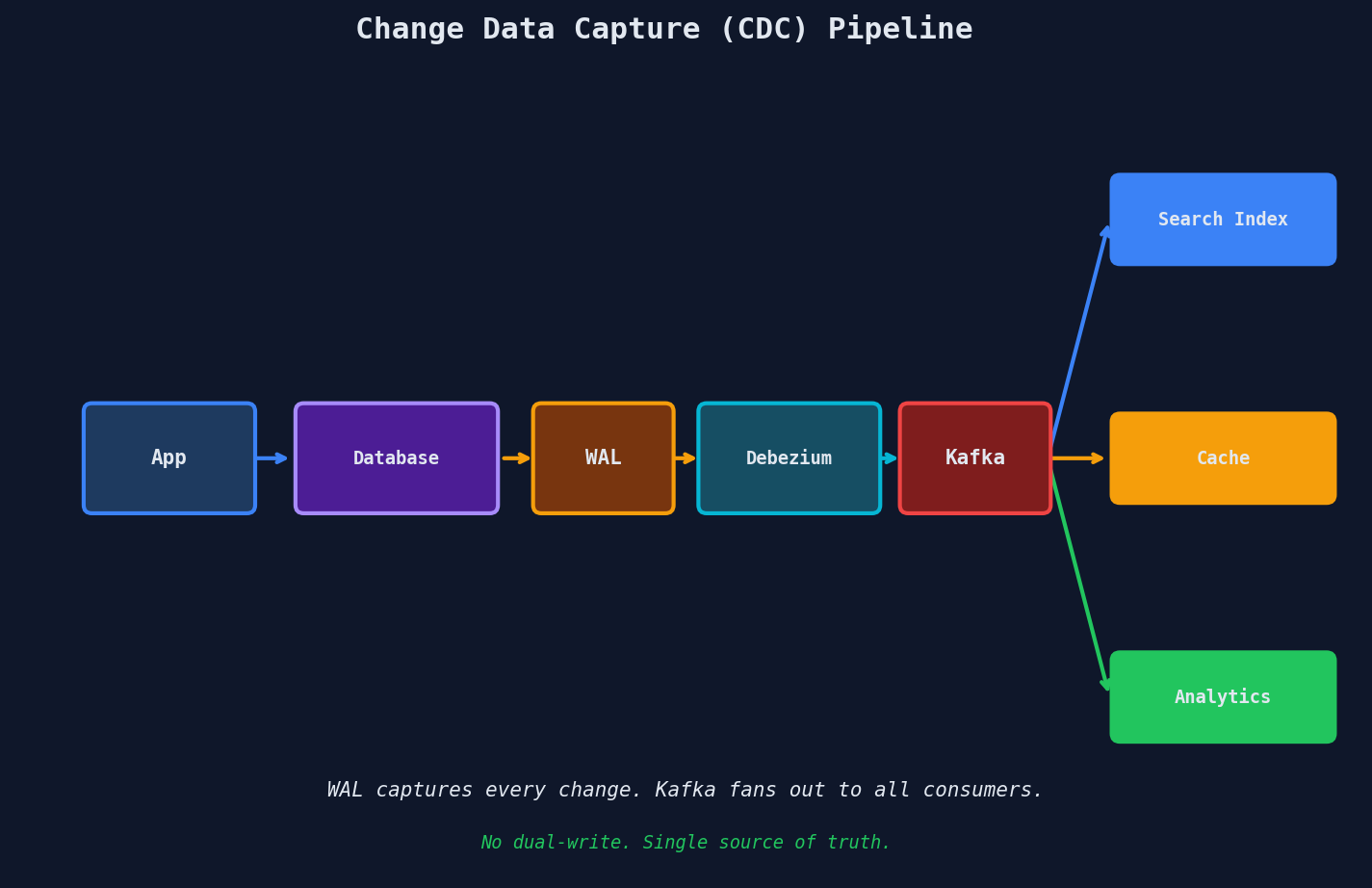
Why this works: if the database write succeeds, the change is guaranteed to be in the transaction log. The CDC tool captures it. If the CDC tool crashes, it resumes from its last position in the log — no data is lost.
# The application becomes simple:
def create_order(order):
db.insert(order) # Only one write. CDC handles the rest.
Latency: typically 100ms to 1 second from the database write to the downstream event appearing in Kafka. For most use cases (search indexing, cache invalidation, analytics), this is perfectly acceptable.
Key properties of CDC:
- At-least-once delivery — downstream consumers must be idempotent (handle duplicate events gracefully)
- Ordered per partition — changes to the same row arrive in order; changes across rows may not
- Schema evolution — CDC captures the raw row data, so schema changes in the source DB propagate automatically
- No application changes — CDC reads the transaction log, not your application code. Even manual SQL updates get captured.
The Outbox Pattern — CDC Without CDC Tooling
Not every team wants to deploy Debezium and manage a CDC pipeline. The outbox pattern achieves the same goal using the database itself.
Instead of writing to Kafka directly, write an event to an outbox table in the same database transaction as the main write:
BEGIN;
-- The actual business write
INSERT INTO orders (id, user_id, amount)
VALUES (uuid(), 42, 99.99);
-- The event, written atomically in the same transaction
INSERT INTO outbox (id, event_type, payload, created_at)
VALUES (uuid(), 'order.created', '{"user_id": 42, "amount": 99.99}', NOW());
COMMIT;
A relay process polls the outbox table (or uses a DB trigger), publishes events to Kafka, and deletes processed rows. Because the business write and the event are in the same transaction, they either both succeed or both fail.
CDC vs Outbox
| CDC (Debezium + WAL) | Outbox Pattern | |
|---|---|---|
| Infrastructure | Debezium, Kafka Connect | Just the existing database |
| Schema changes | Transparent — captures any table | Must explicitly write to outbox |
| Latency | 100ms-1s (log tailing) | Depends on polling interval |
| Delivery guarantee | At-least-once | At-least-once |
| Operational complexity | Higher (CDC pipeline to manage) | Lower (just a table + cron) |
| Captures all changes | Yes (even manual SQL) | No (only changes that write to outbox) |
| Best for | Large orgs, many consumers | Smaller teams, fewer integrations |
Interview Must-Know
The dual-write problem comes up in EVERY system design interview where you need to keep multiple systems in sync. Have both CDC and the outbox pattern ready. Start with: "We can't do a dual write because if one fails we're inconsistent. Instead, we write to the database only and use CDC (or the outbox pattern) to propagate changes to downstream systems."
Putting It All Together — Choosing the Right Tool
You now have four tools for handling writes at scale. Here's when to reach for each:
Decision Tree — Which Pattern Do I Need?
Is the problem "too many writes to one row"?
└── YES → Sharded Counters
Is the problem "count unique items with minimal memory"?
└── YES → HyperLogLog
Is the problem "writes in multiple regions without a leader"?
└── YES → CRDTs (G-Counter, PN-Counter, OR-Set)
Is the problem "keeping multiple systems in sync after a write"?
└── YES → CDC or Outbox Pattern
These patterns compose. A real system might use sharded counters for like counts, HyperLogLog for unique viewer counts, and CDC to stream those counters to a search index and analytics pipeline — all in the same service.
Interview Tip
If the interviewer mentions counting, metrics, or analytics at scale — sharded counters and HyperLogLog are the patterns they're looking for. If they mention multi-region writes — CRDTs. If they mention keeping multiple systems in sync — CDC or the outbox pattern. Name the pattern, explain the trade-off, and sketch the architecture. That's what distinguishes a senior answer from a junior one.