Heavy-Light Decomposition
The Problem With Path Queries
You have a tree with \(n\) nodes, each carrying a weight. You need to answer queries: "What is the maximum weight on the path from node \(u\) to node \(v\)?"
One query is easy — walk from \(u\) to \(v\) through their LCA. That's \(O(n)\) in the worst case. But with \(10^5\) queries on a tree of \(10^5\) nodes, naive traversal gives \(O(n \cdot q) = O(10^{10})\). Way too slow.
You need a way to answer path queries in \(O(\log^2 n)\) per query. Heavy-Light Decomposition (HLD) does exactly that.
The Core Idea
HLD splits the tree into chains. Each chain is a path from some node downward, and you arrange it so that any root-to-leaf path crosses at most \(O(\log n)\) chains.
Once you have chains, you flatten each chain into a contiguous segment of an array, then build a segment tree over the whole array. A path query becomes a handful of segment tree queries — one per chain crossed.
Step 1: Classify edges as heavy or light.
For each node, look at all its children. The child with the largest subtree is the heavy child. The edge to that child is a heavy edge. All other edges are light edges.
Step 2: Chains are sequences of heavy edges.
Follow heavy edges downward from any node — that's a heavy chain. Light edges break one chain and start another.
Step 3: The logarithmic guarantee.
When you traverse a light edge going up from a child to its parent, the subtree size at least doubles (the child was NOT the largest subtree, so it had at most half the parent's subtree). That means you can traverse at most \(O(\log n)\) light edges on any root-to-leaf path. Since each light edge separates two chains, any path crosses at most \(O(\log n)\) chains.
HLD decomposes a tree into \(O(n)\) chains such that any root-to-leaf path crosses \(O(\log n)\) of them. Flatten the chains into an array, and path queries become segment tree range queries.
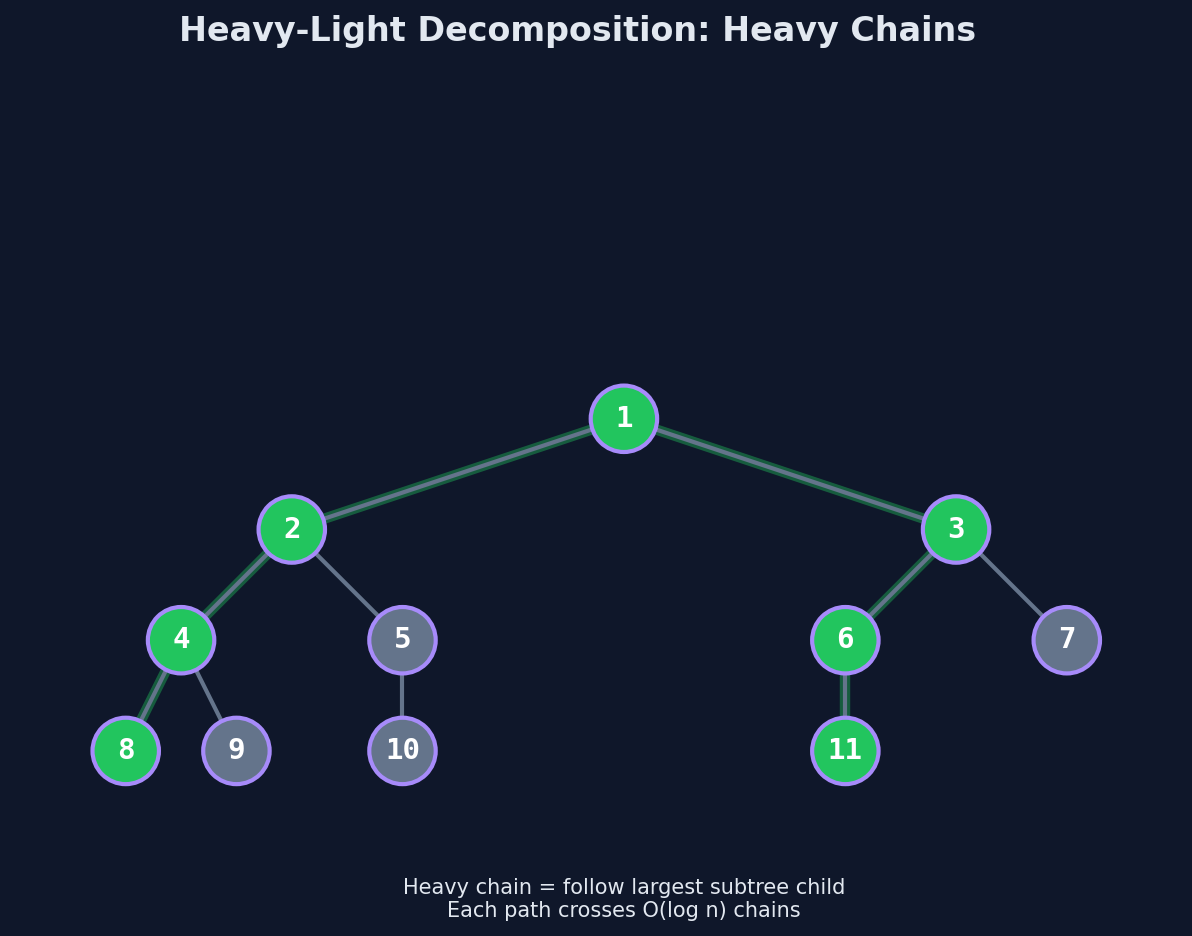
Trace: Decomposing a 10-Node Tree
Subtree sizes (computed bottom-up):
| Node | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Size | 10 | 7 | 3 | 4 | 1 | 2 | 2 | 1 | 1 | 1 |
Heavy children (child with largest subtree):
| Node | Children | Heavy child |
|---|---|---|
| 1 | 2 (size 7), 3 (size 3) | 2 |
| 2 | 4 (size 4), 5 (size 1) | 4 |
| 3 | 6 (size 2) | 6 |
| 4 | 7 (size 2), 8 (size 1) | 7 |
| 6 | 9 (size 1) | 9 |
| 7 | 10 (size 1) | 10 |
Heavy chains (follow heavy edges):
| Chain | Nodes | Head |
|---|---|---|
| Chain A | 1 → 2 → 4 → 7 → 10 | 1 |
| Chain B | 5 | 5 |
| Chain C | 8 | 8 |
| Chain D | 3 → 6 → 9 | 3 |
Flattened array positions:
| Position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Node | 1 | 2 | 4 | 7 | 10 | 5 | 8 | 3 | 6 | 9 |
Each chain occupies a contiguous range. Chain A is positions [0,4]. Chain D is positions [7,9].
Answering a Path Query
Query: Maximum weight on path from node 10 to node 9.
The path goes 10 → 7 → 4 → 2 → 1 → 3 → 6 → 9.
Walk from both endpoints toward their LCA, jumping chain by chain:
| Step | Current node | Chain head | Query range | Jump to |
|---|---|---|---|---|
| 1 | Node 10 (Chain A) | Head = 1 | depth[head=1] < depth[head=3], so process node 9's side first | — |
| 1 | Node 9 (Chain D) | Head = 3 | Query seg tree [7, 9] | parent[3] = 1 |
| 2 | Node 1 (Chain A) | Head = 1 | Same chain as node 10 now | — |
| 3 | Nodes 1 and 10 both in Chain A | — | Query seg tree [0, 4] | Done |
Total: 2 segment tree queries. Each is \(O(\log n)\), so the total is \(O(\log^2 n)\).
The Code
void dfsSetup(int node, int par, int dep) {
parentNode[node] = par;
depthNode[node] = dep;
subtreeSize[node] = 1;
heavyChild[node] = -1;
int maxChildSize = 0;
for (int neighbor : adj[node]) {
if (neighbor == par) continue;
dfsSetup(neighbor, node, dep + 1);
subtreeSize[node] += subtreeSize[neighbor];
if (subtreeSize[neighbor] > maxChildSize) {
maxChildSize = subtreeSize[neighbor];
heavyChild[node] = neighbor;
}
}
}
void decompose(int node, int head) {
chainHead[node] = head;
flatPosition[node] = timer;
flatArray[timer] = nodeWeight[node];
timer++;
if (heavyChild[node] != -1) {
decompose(heavyChild[node], head);
}
for (int neighbor : adj[node]) {
if (neighbor == parentNode[node]) continue;
if (neighbor == heavyChild[node]) continue;
decompose(neighbor, neighbor);
}
}
void buildSegTree(int treeNode, int lo, int hi) {
if (lo == hi) {
segTree[treeNode] = flatArray[lo];
return;
}
int mid = (lo + hi) / 2;
buildSegTree(2 * treeNode, lo, mid);
buildSegTree(2 * treeNode + 1, mid + 1, hi);
segTree[treeNode] = max(segTree[2 * treeNode], segTree[2 * treeNode + 1]);
}
int querySegTree(int treeNode, int lo, int hi, int qlo, int qhi) {
if (qlo > hi || qhi < lo) return 0;
if (qlo <= lo && hi <= qhi) return segTree[treeNode];
int mid = (lo + hi) / 2;
return max(querySegTree(2 * treeNode, lo, mid, qlo, qhi),
querySegTree(2 * treeNode + 1, mid + 1, hi, qlo, qhi));
}
int pathMaxQuery(int u, int v, int numNodes) {
int result = 0;
while (chainHead[u] != chainHead[v]) {
if (depthNode[chainHead[u]] < depthNode[chainHead[v]]) swap(u, v);
result = max(result, querySegTree(1, 0, numNodes - 1,
flatPosition[chainHead[u]], flatPosition[u]));
u = parentNode[chainHead[u]];
}
if (depthNode[u] > depthNode[v]) swap(u, v);
result = max(result, querySegTree(1, 0, numNodes - 1,
flatPosition[u], flatPosition[v]));
return result;
}
Complexity: \(O(n)\) preprocessing. \(O(\log^2 n)\) per path query (\(O(\log n)\) chains, \(O(\log n)\) per segment tree query).
When to Use HLD
HLD is for path queries and path updates on trees: - Max/min/sum on a path between two nodes - Update all edges/nodes on a path - Any query that a segment tree can answer on an array, but you need it on a tree path
If you only need subtree queries, Euler tour + segment tree is simpler. HLD is specifically for paths.
Try It
Input: 5 nodes, weights [3, 7, 2, 5, 1], edges (1,2),(1,3),(2,4),(2,5)
Query: max on path from 4 to 3
Output: 7 (path is 4→2→1→3, weights 5,7,3,2, max is 7)
Predict before running: On a path graph of \(n\) nodes, how many chains does HLD produce? Just 1 — the entire path is a single heavy chain. Every node's heavy child is its only child.
Challenge: Modify the code to support point updates — changing the weight of a single node — in \(O(\log n)\) per update.
Edge Cases to Watch For
- Path query where \(u = v\) (single node): Both endpoints are in the same chain, and the segment tree range is a single element. Some segment tree implementations handle length-1 ranges incorrectly (especially with lazy propagation) — verify this case explicitly.
- Star graph: Every edge is light except one. Paths between leaves cross 2 chains (leaf-to-center, center-to-leaf), each of length 1. The chain-head array must be populated correctly even for length-1 chains.
- Edge-weighted HLD: When the problem uses edge weights (not node weights), the LCA node's weight must be excluded from the path query. The standard node-weighted code includes it — add a guard to skip the LCA's position in the segment tree range.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| SPOJ QTREE — Query on a Tree | spoj.com/problems/QTREE | Hard |
| CF 243D — Clever Queries on Tree | codeforces.com/problemset/problem/243/D | Hard |
What's Next?
HLD handles path queries by decomposing into chains. But what about queries over ALL paths (like counting paths of length K)? Centroid Decomposition in Chapter 15 solves this by recursively splitting the tree.