LCA via Euler Tour and RMQ
You've Seen the Pieces — Now the Full Build
Chapter 11 Lesson 3 introduced the idea: build an Euler tour, reduce LCA to Range Minimum Query. This lesson puts it all together with complete code, a full trace, and a head-to-head comparison with binary lifting.
Recap: The Three Components
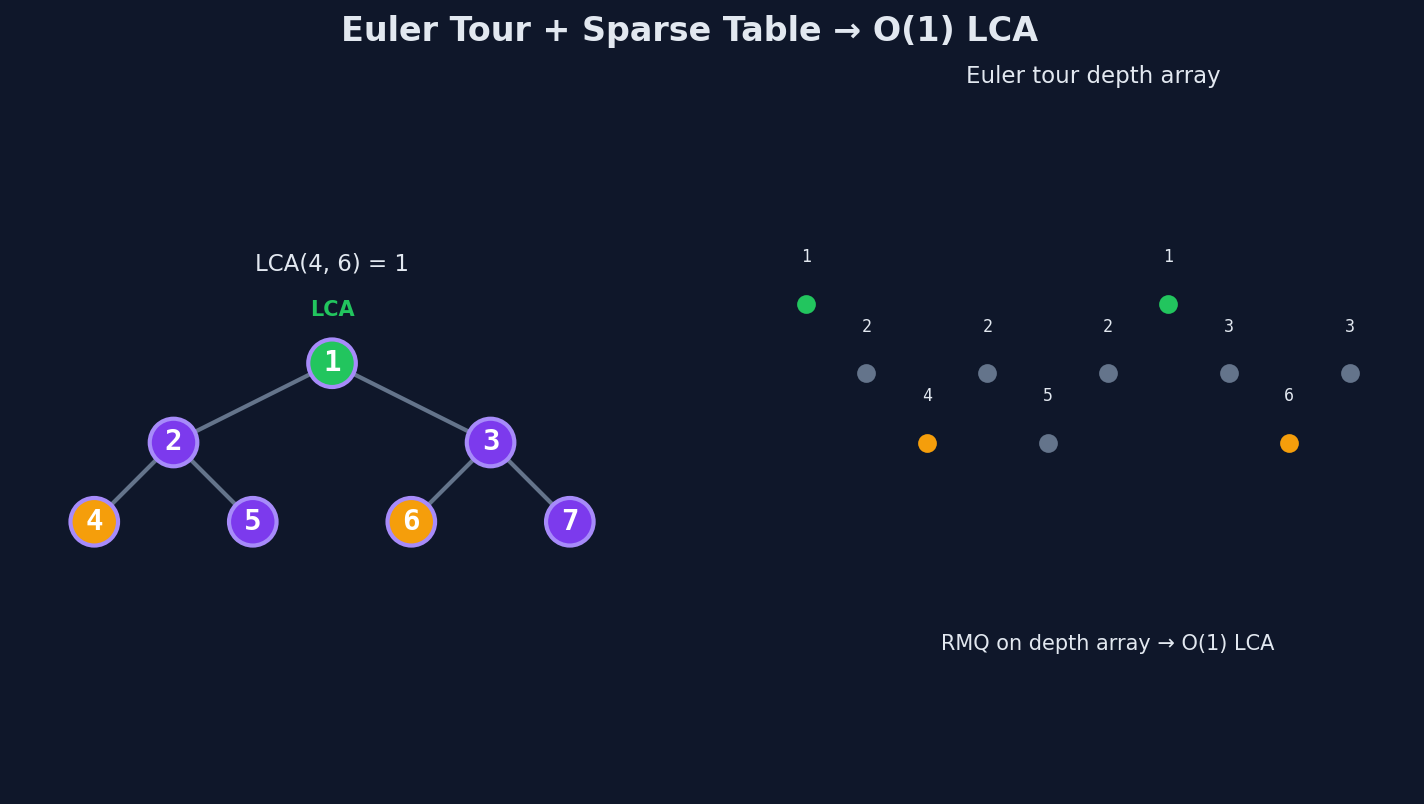
1. Euler Tour. Walk the tree with DFS. Every time you're at a node — entering it or returning from a child — append it to an array. A tree with \(n\) nodes produces a tour of length \(2n - 1\).
2. First Occurrence. For each node \(v\), record the index where it first appears in the tour. This is the "representative position" of \(v\).
3. Sparse Table. A data structure that answers "index of minimum value in range \([l, r]\)" in \(O(1)\), after \(O(m \log m)\) preprocessing on an array of length \(m\).
The connection: \(LCA(u, v)\) is the shallowest node on the path from \(u\) to \(v\). In the Euler tour, the segment between the first occurrences of \(u\) and \(v\) contains exactly the nodes visited while traveling from \(u\) to \(v\). The shallowest one — the one with minimum depth — is the LCA.
Full Trace: 8-Node Tree
Step 1: Build the Euler Tour.
Walk the tree. Every entry and every return gets appended.
| Event | Action | Append | Depth |
|---|---|---|---|
| Enter 1 | first visit | 1 | 0 |
| Enter 2 | first visit | 2 | 1 |
| Enter 5 | first visit | 5 | 2 |
| Enter 8 | first visit | 8 | 3 |
| Return to 5 | backtrack from 8 | 5 | 2 |
| Return to 2 | backtrack from 5 | 2 | 1 |
| Enter 6 | first visit | 6 | 2 |
| Return to 2 | backtrack from 6 | 2 | 1 |
| Return to 1 | backtrack from 2 | 1 | 0 |
| Enter 3 | first visit | 3 | 1 |
| Return to 1 | backtrack from 3 | 1 | 0 |
| Enter 4 | first visit | 4 | 1 |
| Enter 7 | first visit | 7 | 2 |
| Return to 4 | backtrack from 7 | 4 | 1 |
| Return to 1 | backtrack from 4 | 1 | 0 |
Tour length: \(2 \times 8 - 1 = 15\).
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Node | 1 | 2 | 5 | 8 | 5 | 2 | 6 | 2 | 1 | 3 | 1 | 4 | 7 | 4 | 1 |
| Depth | 0 | 1 | 2 | 3 | 2 | 1 | 2 | 1 | 0 | 1 | 0 | 1 | 2 | 1 | 0 |
Step 2: First Occurrences.
| Node | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| First | 0 | 1 | 9 | 11 | 2 | 6 | 12 | 3 |
Step 3: Build Sparse Table on the depth array.
\(st[i][0] = i\) for all \(i\) (each element is its own range of length 1).
\(k = 1\) (length 2): compare adjacent pairs, store index of the shallower one. \(k = 2\) (length 4): combine two length-2 results. \(k = 3\) (length 8): combine two length-4 results.
(Full table omitted for brevity — the construction is identical to Ch11 L3.)
Answering Queries
Query: LCA(8, 6).
\(first[8] = 3, first[6] = 6\). Range \([3, 6]\).
| Index | 3 | 4 | 5 | 6 |
|---|---|---|---|---|
| Node | 8 | 5 | 2 | 6 |
| Depth | 3 | 2 | 1 | 2 |
Minimum depth = 1, at index 5, node 2. \(LCA(8, 6) = 2\).
Query: LCA(8, 7).
\(first[8] = 3, first[7] = 12\). Range \([3, 12]\).
| Index | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|
| Depth | 3 | 2 | 1 | 2 | 1 | 0 | 1 | 0 | 1 | 2 |
Minimum depth = 0, at index 8 (or 10), node 1. \(LCA(8, 7) = 1\).
Query: LCA(5, 6).
\(first[5] = 2, first[6] = 6\). Range \([2, 6]\).
| Index | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| Depth | 2 | 3 | 2 | 1 | 2 |
Minimum depth = 1, at index 5, node 2. \(LCA(5, 6) = 2\).
All correct. Each query: two lookups in the sparse table, one comparison. \(O(1)\).
Binary Lifting vs Euler Tour + RMQ
| Binary Lifting | Euler Tour + RMQ | |
|---|---|---|
| Preprocessing | \(O(n \log n)\) | \(O(n \log n)\) |
| Per query | \(O(\log n)\) | \(O(1)\) |
| Memory | \(O(n \log n)\) | \(O(n \log n)\) |
| \(k\)-th ancestor | Yes (\(O(\log n)\)) | No |
| Code complexity | ~30 lines | ~40 lines |
| Constant factor | Smaller | Slightly larger |
Choose binary lifting when: - You also need \(k\)-th ancestor queries. - You're coding under time pressure and want fewer lines. - \(O(\log n)\) per query is fast enough (it usually is for \(q \leq 2 \times 10^5\)).
Choose Euler tour + RMQ when: - You have a very large number of queries (\(q > 10^6\)). - Each query must be \(O(1)\) because it's inside another loop (e.g., inside a sweep or binary search). - You're solving a problem that already requires an Euler tour for other reasons.
In practice, binary lifting is more common in contests because it's simpler and the \(O(\log n)\) factor rarely matters. But knowing both gives you the flexibility to pick the right one.
The Code
vector<int> adjacency[200005];
int eulerTour[400005];
int eulerDepth[400005];
int firstOccurrence[200005];
int sparseTable[400005][20];
int logTable[400005];
int tourSize = 0;
void buildEulerTour(int node, int parent, int currentDepth) {
firstOccurrence[node] = tourSize;
eulerTour[tourSize] = node;
eulerDepth[tourSize] = currentDepth;
tourSize++;
for (int child : adjacency[node]) {
if (child != parent) {
buildEulerTour(child, node, currentDepth + 1);
eulerTour[tourSize] = node;
eulerDepth[tourSize] = currentDepth;
tourSize++;
}
}
}
void buildSparseTable() {
logTable[1] = 0;
for (int i = 2; i <= tourSize; i++)
logTable[i] = logTable[i / 2] + 1;
for (int i = 0; i < tourSize; i++)
sparseTable[i][0] = i;
for (int power = 1; (1 << power) <= tourSize; power++) {
for (int i = 0; i + (1 << power) - 1 < tourSize; i++) {
int left = sparseTable[i][power - 1];
int right = sparseTable[i + (1 << (power - 1))][power - 1];
sparseTable[i][power] = (eulerDepth[left] <= eulerDepth[right]) ? left : right;
}
}
}
int lca(int u, int v) {
int left = firstOccurrence[u];
int right = firstOccurrence[v];
if (left > right) swap(left, right);
int length = right - left + 1;
int k = logTable[length];
int candidateLeft = sparseTable[left][k];
int candidateRight = sparseTable[right - (1 << k) + 1][k];
int bestIndex = (eulerDepth[candidateLeft] <= eulerDepth[candidateRight]) ? candidateLeft : candidateRight;
return eulerTour[bestIndex];
}
Complexity: \(O(n \log n)\) preprocessing, \(O(1)\) per LCA query. Memory: \(O(n \log n)\) for the sparse table.
Try It
Fill in all three functions in the starter code.
Predict before running: On the chain 1 → 2 → 3 → 4, the Euler tour is \([1, 2, 3, 4, 3, 2, 1]\). Length = \(2 \times 4 - 1 = 7\). \(LCA(4, 2)\): \(first[4] = 3, first[2] = 1\). Range \([1, 3]\), depths \([1, 2, 3]\). Min depth = 1, node 2. Correct.
Challenge: What is the Euler tour of a star graph (node 1 connected to nodes 2, 3, 4, 5)? It's \([1, 2, 1, 3, 1, 4, 1, 5, 1]\). Length = \(2 \times 5 - 1 = 9\). Node 1 appears 5 times. Every LCA query returns 1.
Edge Cases to Watch For
first[u]>first[v]— RMQ range inverted: Always ensure the range is ordered before querying. Passing an inverted range to the sparse table returns garbage.- Sparse table memory for large \(n\): For \(n = 2 \times 10^5\), the tour is \(\sim 4 \times 10^5\) entries, and the table uses \(\sim 28\) MB. If the judge has a tight memory limit (e.g., 64 MB), this may MLE — check constraints before choosing this approach over binary lifting.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| CSES — Company Queries II | cses.fi/problemset/task/1688 | Medium |
| CSES — Distance Queries | cses.fi/problemset/task/1135 | Medium |
| CF 191C — Fools and Roads | codeforces.com/problemset/problem/191/C | Hard |