Distributed Transactions
TL;DR
Traditional ACID transactions don't work across microservices. Two-Phase Commit (2PC) is correct but fragile and slow. The Saga pattern breaks a distributed operation into a sequence of local transactions with compensating actions for rollback. The Outbox pattern solves the dual-write problem of atomically updating a database and publishing an event.
The Dinner Table Problem
Two-Phase Commit is like getting everyone at a dinner table to agree on a restaurant before anyone moves. The coordinator asks each person: "Can you commit to Italian?" Everyone says yes. Then the coordinator says "Go." If even one person says no, nobody moves. It works -- but if the coordinator's phone dies mid-conversation, everyone is stuck standing in the hallway, unable to proceed.
Sagas are like everyone ordering their own meal separately, with a refund policy. If the appetizer arrives but the kitchen runs out of your entree, you get a refund for the appetizer. Each step is independent, and each has a plan for undoing itself.
The Problem: One Operation, Many Databases
In a monolith, a single database transaction can atomically update the orders table, the inventory table, and the payments table. One COMMIT, everything is consistent.
In microservices, each service owns its own database:
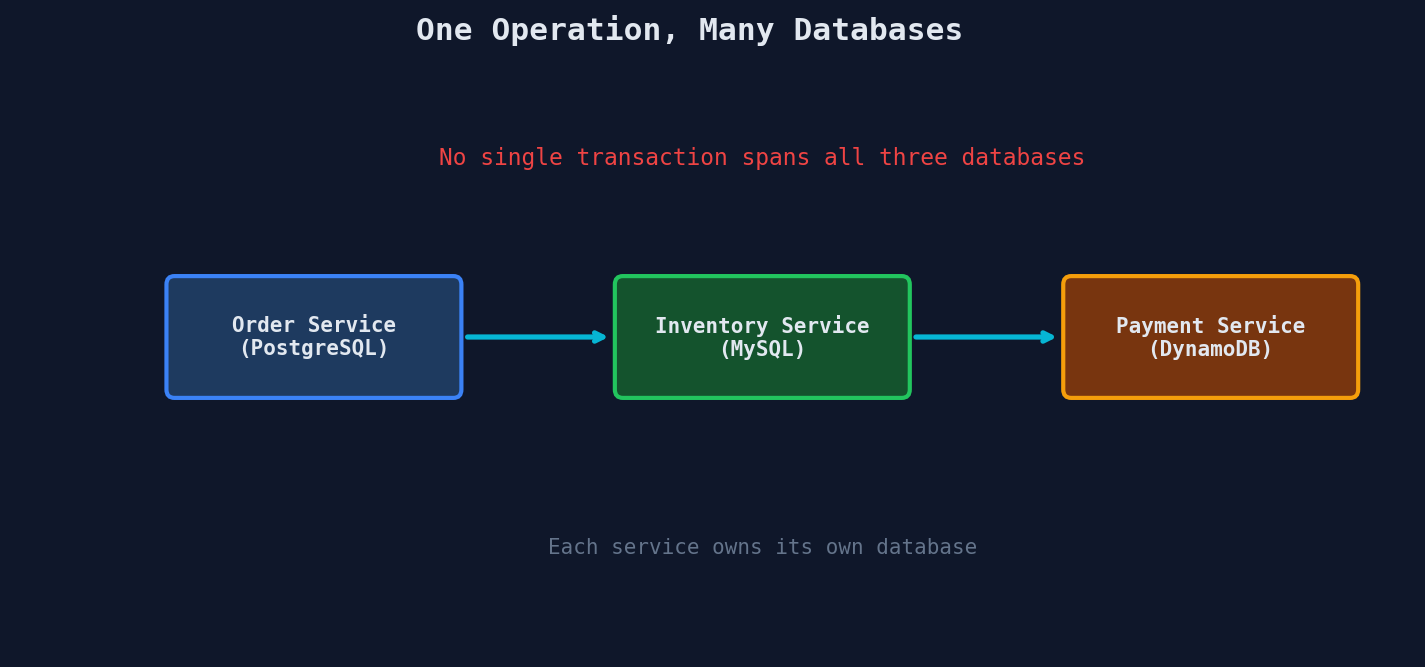
There's no single transaction that spans all three databases. If the payment fails after inventory was already reserved, you need a way to undo the reservation. This is the distributed transaction problem.
Two-Phase Commit (2PC)
The oldest solution. A coordinator manages the transaction across all participants.
Phase 1: Prepare
The coordinator asks each participant: "Can you commit this?" Each participant acquires locks, validates the operation, and responds YES or NO.
Phase 2: Commit (or Abort)
If all participants said YES, the coordinator sends COMMIT. If any said NO, the coordinator sends ABORT and everyone rolls back.
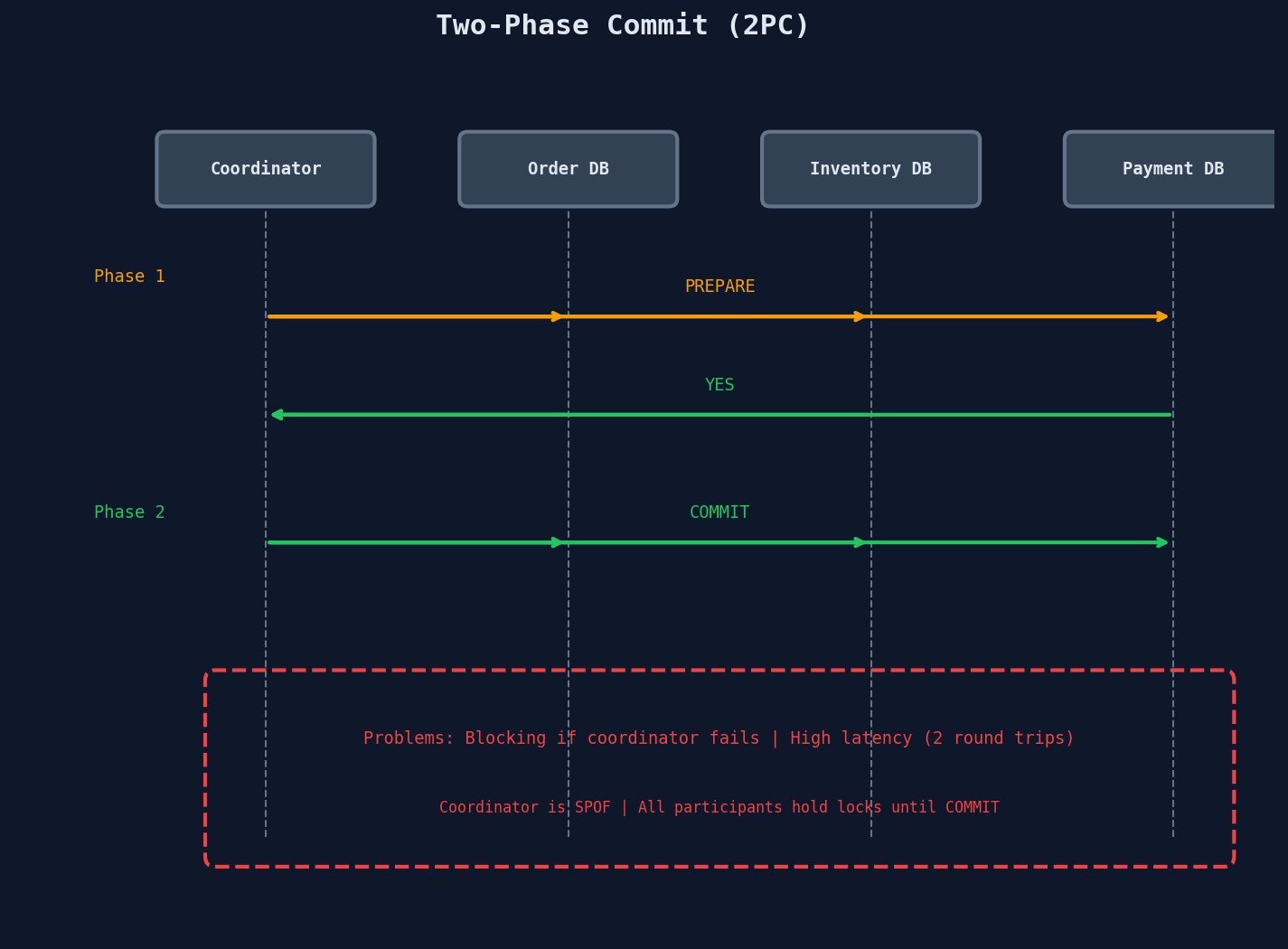
Why 2PC Is Problematic
| Problem | Explanation |
|---|---|
| Blocking | If the coordinator crashes after PREPARE but before COMMIT, all participants hold locks indefinitely, waiting for a decision that never comes |
| Latency | Two network round-trips minimum. Cross-region, this adds 100-400ms |
| Tight coupling | All participants must implement the 2PC protocol. Adding a new service means integrating it into the coordination layer |
| Single point of failure | The coordinator is a bottleneck. If it dies, the entire transaction is in limbo |
2PC is still used within a single database (that's how PostgreSQL handles multi-table transactions internally). But across services over a network, it's generally avoided.
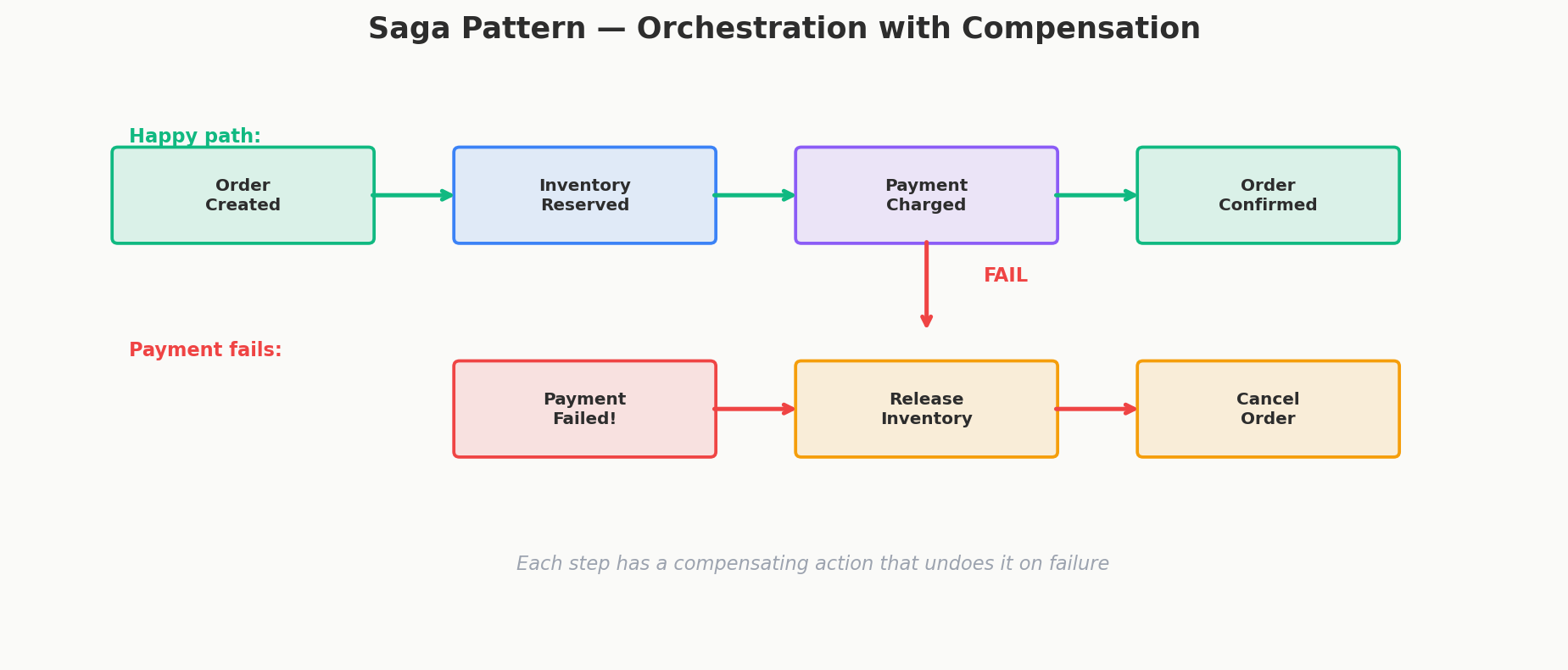
The Saga Pattern
A Saga breaks a distributed operation into a sequence of local transactions. Each local transaction updates one service's database and triggers the next step. If any step fails, previously completed steps are undone by compensating transactions.
E-Commerce Order Example
Happy path:
1. Order Service → Create order (status: PENDING)
2. Inventory Service → Reserve items
3. Payment Service → Charge credit card
4. Order Service → Update order (status: CONFIRMED)
5. Shipping Service → Schedule shipment
Failure path (payment fails at step 3):
3. Payment Service → Charge fails
2. Inventory Service → COMPENSATE: Release reservation
1. Order Service → COMPENSATE: Cancel order (status: CANCELLED)
Each step is a local ACID transaction within a single service. The Saga coordinates the sequence. The key insight: instead of one big atomic operation, you get a series of small atomic operations with explicit undo logic.
Choreography vs Orchestration
There are two ways to coordinate a Saga:
Choreography: Each service publishes events, and other services react. No central coordinator.
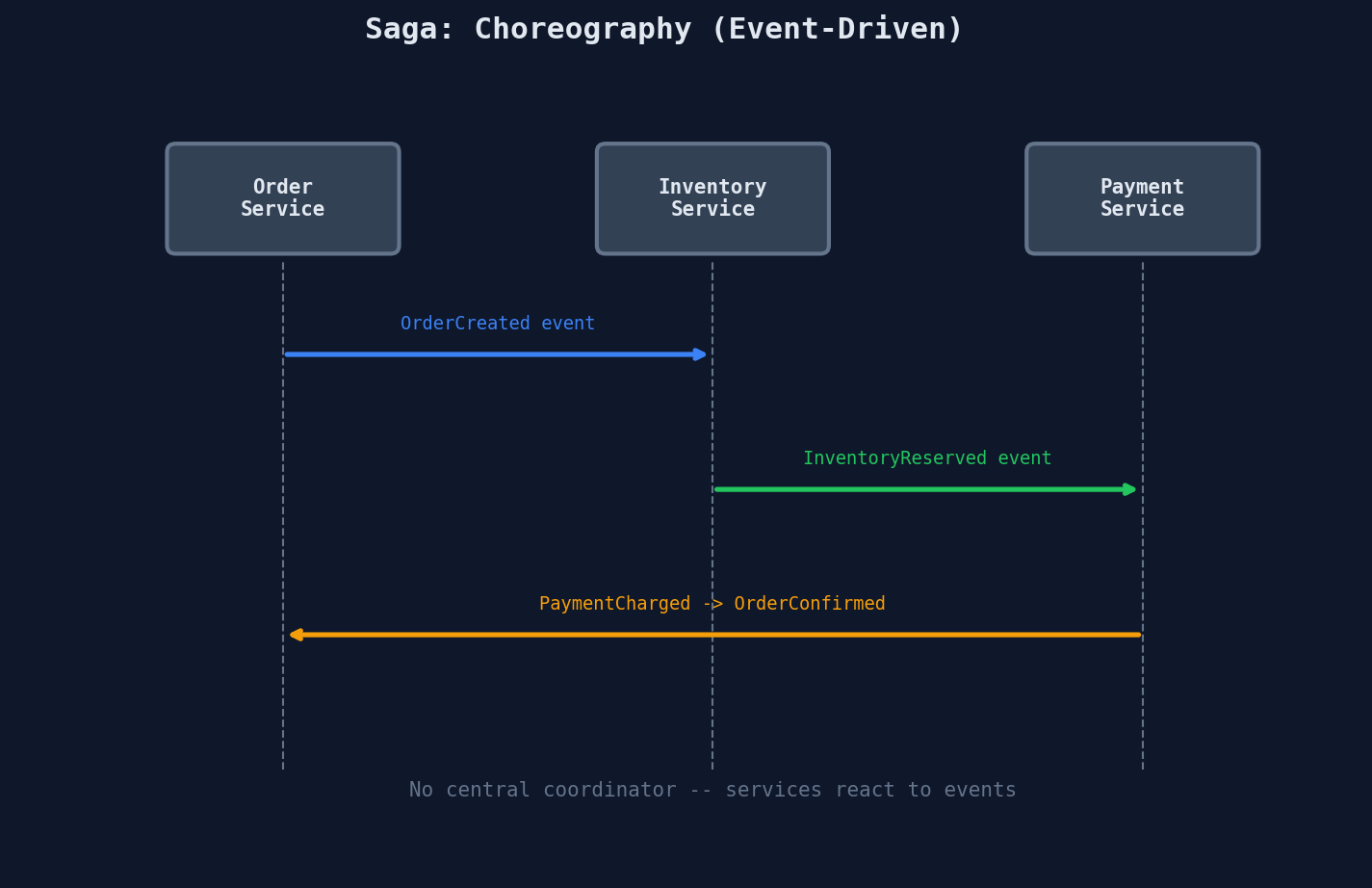
- Pros: Simple for small flows. No single point of failure. Services are loosely coupled.
- Cons: Hard to track the overall flow. Debugging is painful -- you're chasing events across 5 services. Adding a step means modifying multiple services.
Orchestration: A central Saga orchestrator directs each step explicitly.
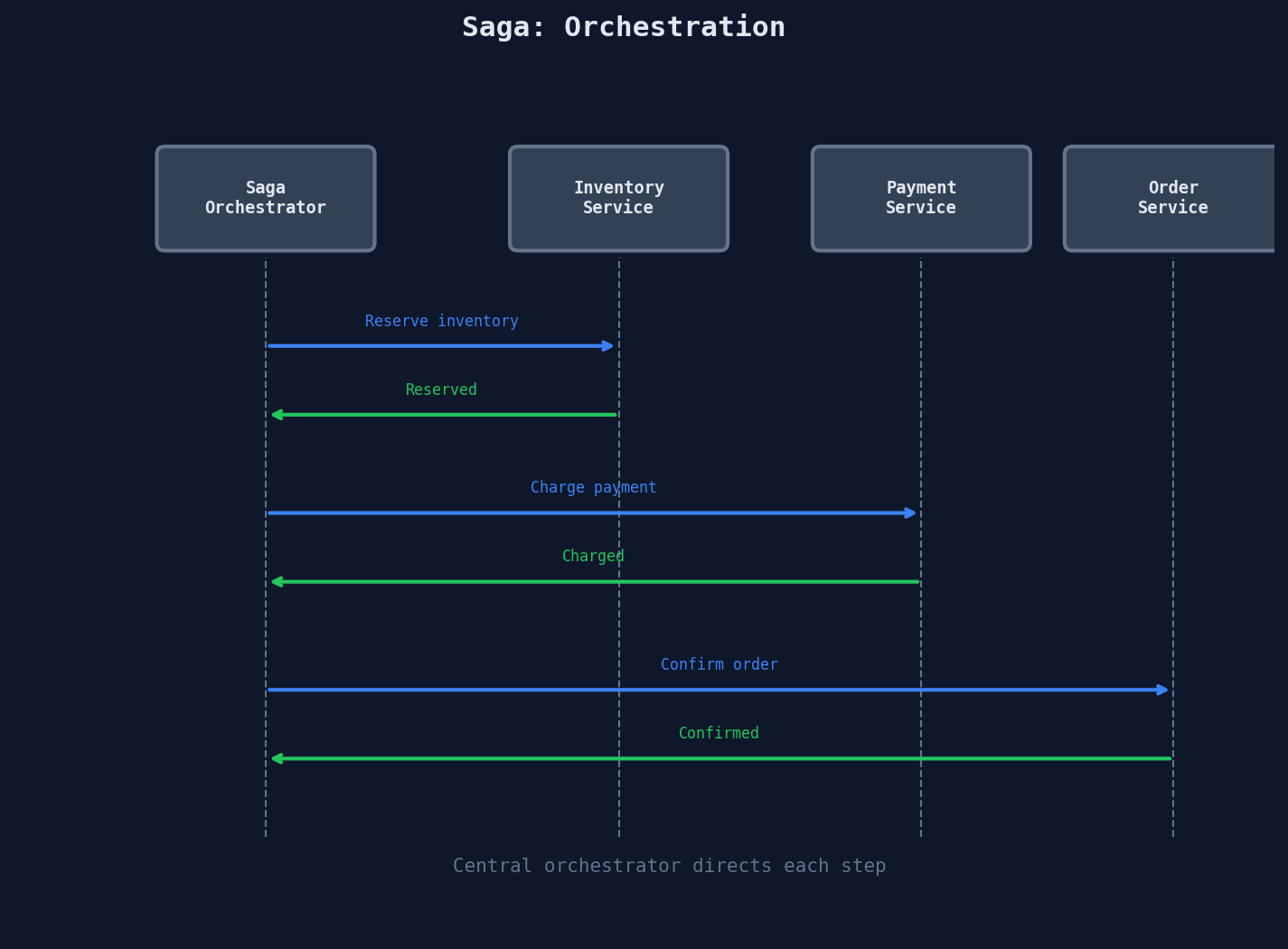
- Pros: Easy to understand the flow. Easy to add or reorder steps. Centralized error handling and retry logic.
- Cons: The orchestrator is a single point of failure (mitigated by making it stateful and persistent). Can become a bottleneck.
In practice, most teams at scale use orchestration. Netflix built Conductor, Uber built Cadence (now Temporal) -- both are Saga orchestration frameworks.
Compensating Transactions Are Tricky
Not every operation is easy to undo:
| Step | Compensation | Difficulty |
|---|---|---|
| Reserve inventory | Release reservation | Easy -- just delete the reservation |
| Charge credit card | Refund | Medium -- refunds take days, may incur fees |
| Send email notification | Send "sorry, ignore that" email | Awkward but possible |
| Ship physical goods | Recall shipment or schedule return | Hard and expensive |
This is why Saga design matters. Order your steps so that hard-to-compensate actions happen last. Charge the credit card before shipping. Don't ship before payment is confirmed.
The Dual-Write Problem
Here's a subtle but critical problem. After your Order Service creates an order, it needs to do two things:
- Insert the order into its database
- Publish an "OrderCreated" event to Kafka so other services can react
These are two separate systems. You can't wrap a PostgreSQL insert and a Kafka publish in a single ACID transaction. What happens if the database write succeeds but the Kafka publish fails? Or vice versa?
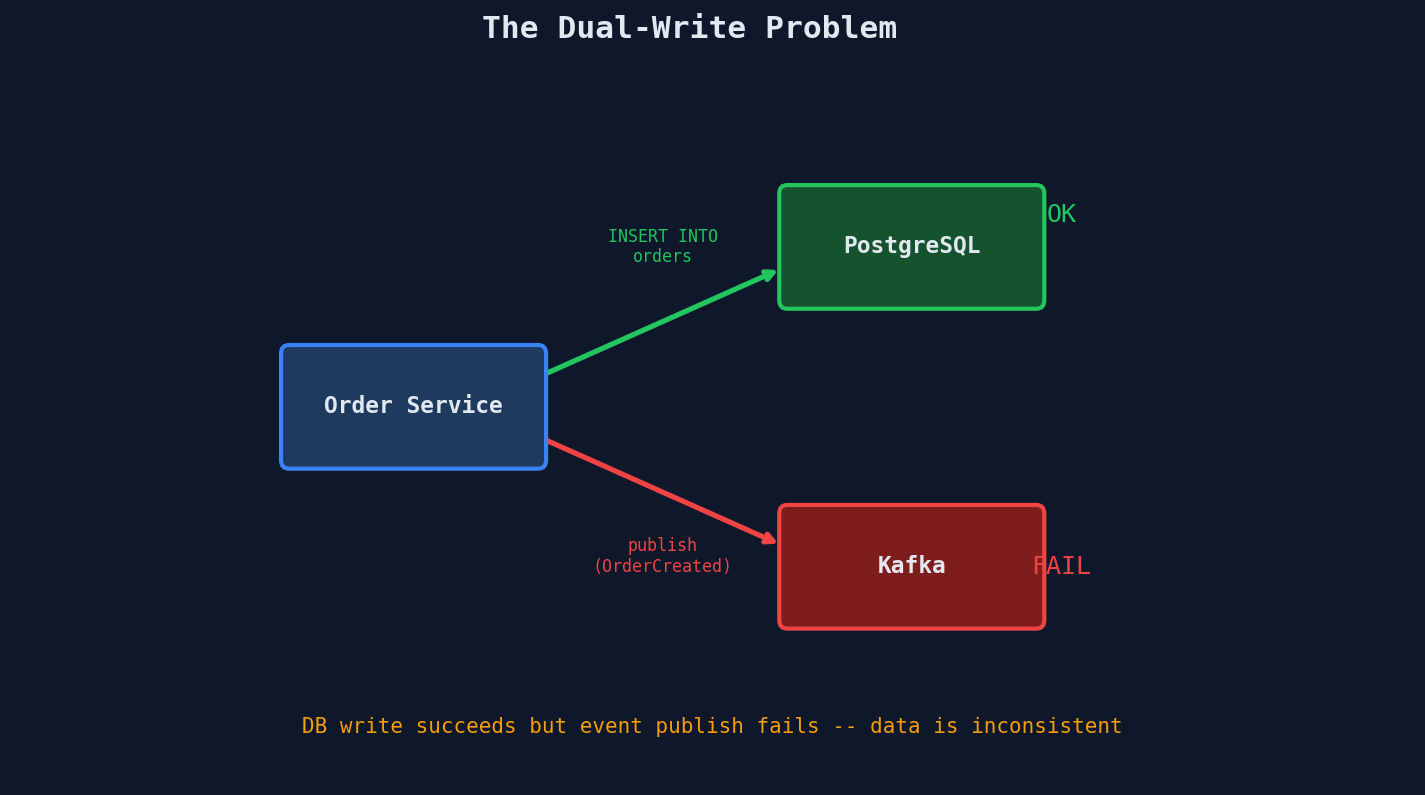
This is the dual-write problem: you need to atomically update a database AND publish an event, but they're in different systems.
The Outbox Pattern
The Outbox pattern solves dual-writes by using the database itself as the message queue.
How It Works
- In the same database transaction, write the business data AND an event record to an
outboxtable. - A separate process reads the outbox table and publishes events to the message broker.
- After successful publishing, mark the outbox row as processed (or delete it).
-- Step 1: Single atomic transaction
BEGIN;
INSERT INTO orders (id, customer_id, total, status)
VALUES ('ord-123', 'cust-456', 99.99, 'PENDING');
INSERT INTO outbox (id, aggregate_type, aggregate_id, event_type, payload, created_at)
VALUES (
'evt-789',
'Order',
'ord-123',
'OrderCreated',
'{"order_id": "ord-123", "customer_id": "cust-456", "total": 99.99}',
NOW()
);
COMMIT;
-- Step 2: Outbox relay process (polling or CDC)
SELECT * FROM outbox WHERE processed = false ORDER BY created_at LIMIT 100;
-- After successfully publishing each event to Kafka:
UPDATE outbox SET processed = true WHERE id = 'evt-789';
Why This Works
Both writes happen in the same database transaction. If the transaction commits, both the order and the event record exist. If it rolls back, neither exists. The outbox relay process can retry failed publishes because the event is durably stored in the database.
Outbox Relay: Polling vs CDC
Polling: A background job periodically queries the outbox table for unprocessed events. Simple but adds latency (events aren't published until the next poll cycle) and puts load on the database.
Change Data Capture (CDC): Tools like Debezium read the database's transaction log (WAL in PostgreSQL, binlog in MySQL) and stream changes to Kafka in near-real-time. No polling, lower latency, no extra load on the database.
Polling approach:
App → DB (outbox table) ← Poller → Kafka
CDC approach:
App → DB → Transaction log → Debezium → Kafka
CDC is the preferred approach at scale. Debezium + Kafka Connect is the most common implementation.
Durable Execution Frameworks
Modern frameworks like Temporal (evolved from Uber's Cadence) and Netflix Conductor abstract away much of the Saga complexity.
With Temporal, you write your workflow as normal code. The framework handles:
- Persistence: Each step's result is durably stored. If the process crashes, it resumes from the last completed step.
- Retries: Failed steps are automatically retried with configurable backoff.
- Timeouts: Steps that hang are detected and handled.
- Compensation: You define compensating logic inline, and the framework runs it on failure.
# Pseudocode for a Temporal workflow
@workflow.defn
class OrderWorkflow:
@workflow.run
async def run(self, order):
# Each step is automatically persisted and retried
reservation = await workflow.execute_activity(
reserve_inventory, order.items, start_to_close_timeout=30
)
try:
payment = await workflow.execute_activity(
charge_payment, order.total, start_to_close_timeout=60
)
except Exception:
# Compensate: release the inventory reservation
await workflow.execute_activity(
release_inventory, reservation.id
)
raise
await workflow.execute_activity(confirm_order, order.id)
This is essentially Saga orchestration with the infrastructure handled for you. Stripe uses Temporal for payment orchestration. Snap uses it for data pipelines.
Interview Tip
If asked "How would you handle a transaction that spans multiple microservices?", don't jump straight to 2PC. Explain that 2PC is blocking and fragile across services, then propose the Saga pattern. Mention choreography vs orchestration, lean toward orchestration for complex flows, and bring up the outbox pattern for reliable event publishing. If you mention Temporal or a similar framework, you'll signal that you know how production systems actually solve this.
Quick Recap
| Approach | How It Works | Pros | Cons |
|---|---|---|---|
| 2PC | Coordinator asks all participants to prepare, then commit | Strong consistency across services | Blocking, slow, coordinator is SPOF |
| Saga (Choreography) | Services publish events, others react | Loosely coupled, no SPOF | Hard to debug, implicit flow |
| Saga (Orchestration) | Central coordinator directs each step | Clear flow, easy to modify | Orchestrator is a dependency |
| Outbox Pattern | Write event to DB table, relay to broker | Solves dual-write atomically | Extra table, relay process needed |
| Durable Execution | Framework persists each step | Handles retries, crashes, compensation | Vendor/framework dependency |
Idempotency Keys — Making Retries Safe
Distributed transactions often require retries — networks fail, services timeout, messages get duplicated. But retrying a payment charge without protection might charge the customer twice.
Idempotency keys solve this. The client generates a unique key (typically a UUID) for each operation and includes it with every request and retry:
POST /api/charges
Idempotency-Key: 550e8400-e29b-41d4-a716-446655440000
{amount: 99.99, currency: "usd"}
The server stores the key and result. If the same key appears again, it returns the stored result without re-executing the operation. Stripe's API uses this exact pattern — every charge, refund, and transfer supports idempotency keys.
def charge_with_idempotency(idempotency_key, amount):
# Check if we've already processed this request
existing = db.execute(
"SELECT result FROM idempotency_keys WHERE key = %s", idempotency_key
)
if existing:
return existing.result # replay stored result
result = payment_gateway.charge(amount) # actually charge
db.execute(
"INSERT INTO idempotency_keys (key, result, created_at) VALUES (%s, %s, NOW())",
idempotency_key, json.dumps(result)
)
return result
The same request with the same key always returns the same result — even if the network dropped the first response and the client retried.
This is especially important for Saga steps — if a Saga retries a step that already succeeded, idempotency ensures the step isn't performed twice.
In practice, most modern systems use orchestrated Sagas with the Outbox pattern for event publishing, often powered by a durable execution framework like Temporal.