Connecting WQS, Undo, and Slope Trick
Three Roads to the Same Mountain
In Chapter 5, you learned Greedy with Undo: pick the best element, leave a breadcrumb to reverse the choice later. In Lesson 1 of this chapter, you learned WQS Binary Search: penalize each pick by \(\lambda\), binary search until the count hits \(K\). In Chapter 5 Lesson 3, you met Slope Trick: store the breakpoints of a convex cost function in a heap.
Once you see the shared DNA between these three techniques, you can't unsee it: they are three different interfaces to the same underlying data structure. The "mountain" they all climb is the concave function \(h(k) =\) best value using exactly \(k\) items. They differ only in how they query it.
The Greedy Choice: All three techniques (WQS, Slope Trick, Greedy with Undo) query the same concave function \(h(k)\). Choose the technique based on whether you need one point, all points, or incremental construction.
This lesson makes that precise. We'll take one problem and solve it all three ways, watching the same numbers appear in each solution. Then we'll build a decision framework for which technique to reach for in contest.
The Running Example
Problem: Array \(a = [5, 8, 3, 9, 4]\). Pick exactly \(K\) non-adjacent elements to maximize the sum. Compute \(h(k)\) for all \(k\).
Non-adjacent subsets from indices \(\{0,1,2,3,4\}\), brute-forced:
| \(k\) | Best subset | \(h(k)\) | Marginal gain \(m(k) = h(k) - h(k-1)\) |
|---|---|---|---|
| 0 | {} | 0 | — |
| 1 | \(\{9\}\) (idx 3) | 9 | 9 |
| 2 | \(\{8,9\}\) (idx 1,3) | 17 | 8 |
| 3 | \(\{5,3,4\}\) (idx 0,2,4) | 12 | \(-5\) |
Marginal gains: 9, 8, \(-5\). Strictly decreasing — \(h(k)\) is concave. All three techniques apply.
The marginal gains are the entire story. Everything that follows is just different ways of computing, storing, or querying these numbers.
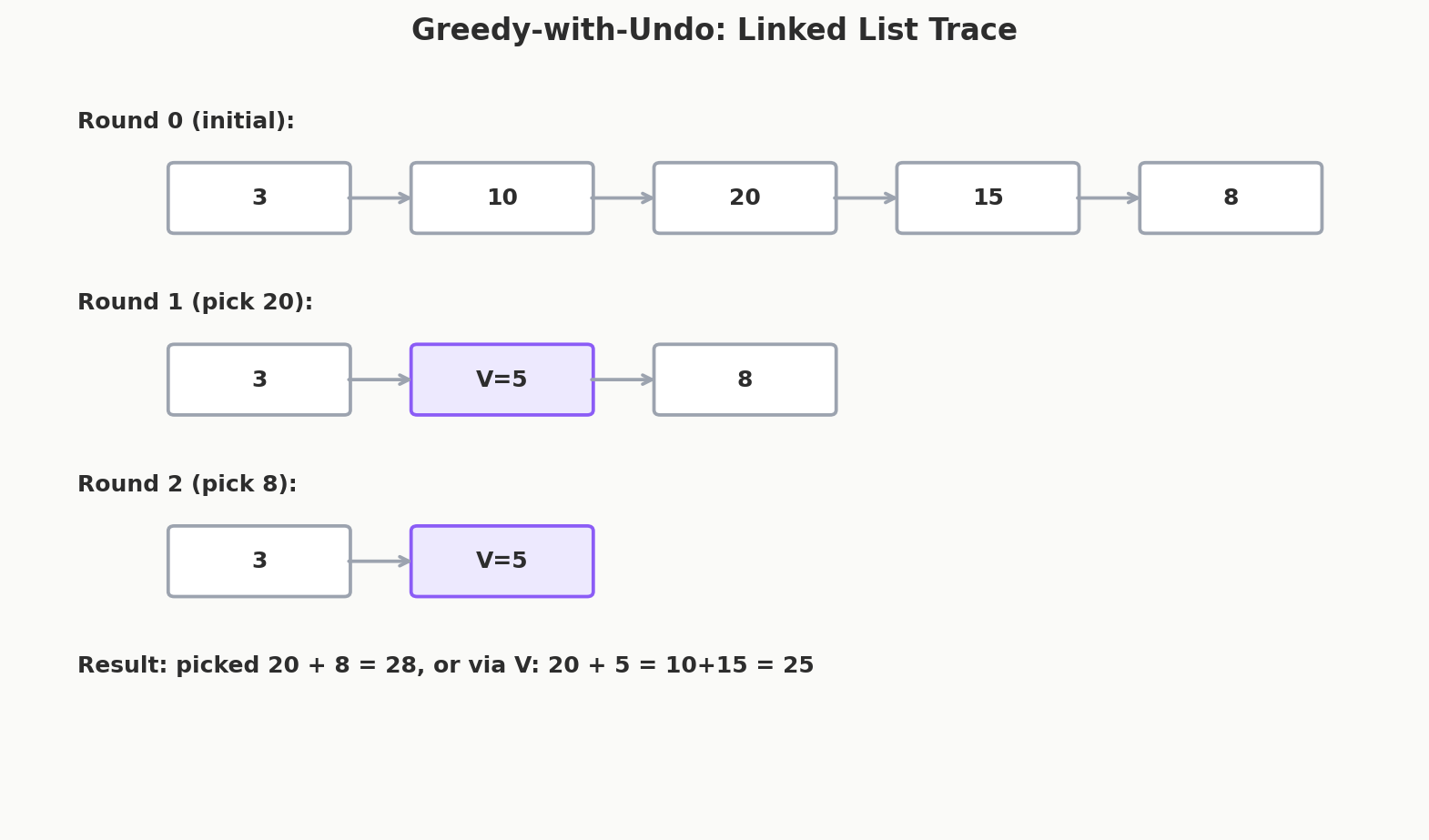
View 1: Greedy with Undo Builds \(h(k)\) Incrementally
The greedy-with-undo approach from Chapter 5 computes \(h(1)\), then \(h(2)\), then \(h(3)\), one at a time. Each iteration extracts one marginal gain.
Setup: Build a doubly-linked list of elements. Maintain a max-heap of available elements.
Round 1: Max element is 9 (index 3). Pick it. \(h(1) = 9\).
Remove neighbors: index 2 (value 3) and index 4 (value 4). Insert undo token at position 3 with value \(= 3 + 4 - 9 = -2\).
| Position | 0 | 1 | 3(undo) |
|---|---|---|---|
| Value | 5 | 8 | \(-2\) |
| Prev | — | 0 | 1 |
| Next | 1 | 3 | — |
Round 2: Heap contains \(\{8, 5, -2\}\). Max is 8 (index 1). Pick it. \(h(2) = 9 + 8 = 17\).
Remove neighbors: index 0 (value 5) and undo (value \(-2\)). Insert undo token: \(5 + (-2) - 8 = -5\).
| Position | 1(undo) |
|---|---|
| Value | \(-5\) |
Round 3: Only \(-5\) left. Pick it. \(h(3) = 17 + (-5) = 12\).
The marginal gains fell out in order: 9, 8, \(-5\). Each undo token encodes the cost of "undoing the best previous choice and picking neighbors instead." The fact that these gains are non-increasing is exactly the concavity of \(h(k)\).
The max-heap in Slope Trick is literally a storage container for these marginal gains. The undo trick produces them one at a time; Slope Trick stores all of them at once.
View 2: WQS Probes \(h(K)\) Directly
WQS doesn't build the whole curve. It finds \(h(K)\) for one specific \(K\) by probing from outside.
The geometric picture: \(h(k)\) is a concave curve. A line with slope \(\lambda\) sweeps against it. The tangent line at \(k = K\) has slope equal to the \(K\)-th marginal gain.
For \(K=2\): \(m(2) = 8\). The optimal \(\lambda\) should be between \(m(2)=8\) and \(m(3)=-5\). Any \(\lambda\) in \((-5, 8]\) should make the inner solver pick exactly 2 items.
Trace with \(\lambda = 7\):
Effective values: \([5-7, 8-7, 3-7, 9-7, 4-7] = [-2, 1, -4, 2, -3]\).
Inner DP (non-adjacent, no count constraint):
| \(i\) | \(a[i]-\lambda\) | dp[\(i\)][skip] | dp[\(i\)][pick] | Best choice |
|---|---|---|---|---|
| 0 | \(-2\) | 0 | \(-2\) | skip |
| 1 | 1 | 0 | 1 | pick |
| 2 | \(-4\) | 1 | \(0+(-4)=-4\) | skip |
| 3 | 2 | 1 | \(1+2=3\) | pick |
| 4 | \(-3\) | 3 | \(1+(-3)=-2\) | skip |
Result: pick indices 1 and 3. Count \(= 2\). \(g(7) = 3\).
Recovery: \(h(2) = g(7) + 7 \times 2 = 3 + 14 = 17\). Correct.
Why \(\lambda=7\) works: the penalty of 7 is high enough that the 3rd marginal gain (\(-5\)) isn't worth paying for, but low enough that the first two (9 and 8) still exceed the penalty.
View 3: Slope Trick Stores the Full Curve
Slope Trick maintains the entire set of marginal gains in a max-heap. Since marginal gains are non-increasing (concavity), the heap stores the complete curve.
To read off \(h(K)\): sum the \(K\) largest marginal gains.
In the "make array non-decreasing" formulation from Chapter 5 Lesson 3, the slope trick heap stores breakpoints of a convex cost function. Here, for a maximization problem, the heap stores marginal gains of a concave value function. These are the same thing viewed from the dual perspective (negate and you convert between the two).
The "push twice, pop once" rule from Slope Trick corresponds exactly to the undo token insertion: - Two pushes = "this element could contribute to a marginal gain" - Pop = "remove the weakest previous gain that's been invalidated" - Popped value = the undo token's value
The Same Numbers, Three Ways
For the running example \([5, 8, 3, 9, 4]\), targeting \(K=2\):
| Aspect | Greedy with Undo | WQS Binary Search | Slope Trick |
|---|---|---|---|
| What it computes | \(h(1)=9, h(2)=17\) | \(h(2)=17\) directly | \(h(k)\) for all \(k\) |
| Key values | Marginal gains: 9, 8 | \(\lambda^*=7\) (between \(m(2)=8\) and \(m(3)=-5\)) | Heap \(= \{9, 8, -5\}\) |
| How it uses gains | Extracts them one by one | Finds the threshold separating "worth picking" from "not" | Stores all of them |
| Data structure | Linked list + max-heap | Inner DP + binary search | Max-heap of breakpoints |
| Complexity | \(O(K \log n)\) | \(O(n \log V)\) | \(O(n \log n)\) |
| Answer | \(9 + 8 = 17\) | \(3 + 7 \times 2 = 17\) | top 2 of heap: \(9+8 = 17\) |
Three roads, same answer. They're all querying the same concave function \(h(k)\), just through different interfaces.
The Flat Edge Problem
What if two consecutive marginal gains are equal? Say the array gives \(m(3) = m(4) = 5\):
| \(k\) | \(h(k)\) | \(m(k)\) |
|---|---|---|
| 2 | 20 | — |
| 3 | 25 | 5 |
| 4 | 30 | 5 |
| 5 | 34 | 4 |
The tangent line with slope 5 touches the curve at BOTH \(k=3\) and \(k=4\). WQS at \(\lambda=5\) might report count=3 or count=4. If you wanted \(h(3)\) but the solver reports count=4, is the answer wrong?
No. The recovery formula \(h(3) = g(5) + 5 \times 3\) still works because the tangent line passes through both points. The y-intercept is the same regardless of which touching point you report.
But the binary search logic needs care. As \(\lambda\) crosses 5, the count might jump from 4 to 2, skipping 3 entirely. The fix: when count >= K, record the answer and keep increasing \(\lambda\). The last valid recording is correct.
Greedy with Undo doesn't have this problem — it produces gains one at a time, and equal gains just mean two iterations give the same delta.
Slope Trick doesn't have it either — equal gains are duplicate entries in the heap.
The flat edge is a WQS-specific headache. It's the price you pay for probing a single point.
The Undo Trick Is Network Flow in Disguise. The connection runs deeper than "same answer." In the Candies problem, the undo token \(V = \text{val}[L] + \text{val}[R] - \text{val}[\text{picked}]\) has a network flow interpretation. Model the problem as min-cost max-flow: source to each element to sink, with non-adjacency constraints as edge capacities. When you augment flow through element \(i\), you create residual edges to the neighbors. The undo token \(V\) is exactly the cost of the augmenting path through those residual edges. Picking \(V\) in the greedy corresponds to pushing flow along this augmenting path, which reverses the flow through \(i\) and routes it through \(L\) and \(R\) instead. This is why Greedy with Undo always finds the optimal: it's implicitly running successive shortest-path augmentation on the flow network, which is optimal for MCMF.
The Mathematical Hierarchy
Not all optimization problems have concave \(h(k)\). The structure determines which tools apply:
Level 1: Pure greedy works (matroids)
Exchange property holds. Pick the best, never look back.
Examples: MST, scheduling with deadlines (Chapter 2).
Level 2: Greedy + concavity tricks (this chapter)
h(k) is concave -> WQS / Slope Trick / Undo all apply.
Examples: non-adjacent K picks, Aliens, stock trading.
Level 3: Network flow required
No concavity, no matroid structure. LP may be fractional.
Examples: 3+ role assignment, general matching.
Level 4: NP-hard
No polynomial exact algorithm (unless P=NP).
Examples: general knapsack, TSP.
The Programmers-and-Artists problem from Chapter 2 Lesson 4 lives at Level 2 (the LP has TUM structure). Add a third role, and it drops to Level 3. The 2-item knapsack from that same lesson lives outside Level 2 because marginal gains are constant (no diminishing returns).
The Decision Framework
When you encounter a "pick exactly \(K\) items to optimize" problem, follow this path:
Step 1: Does \(h(k)\) have decreasing marginal gains?
Check: does the \((k+1)\)-th pick always contribute less than the \(k\)-th? If you're unsure, compute \(h(k)\) for small cases by brute force and check.
- NO: WQS/Slope Trick/Undo won't work. Use DP with the count dimension, or MCMF.
- YES: proceed to Step 2.
Step 2: Do you need \(h(K)\) for a single \(K\), or for all \(K\)?
- Single \(K\), and the inner solver is fast: WQS Binary Search. \(O(T_{\text{inner}} \cdot \log V)\).
- All \(K\), or the problem is naturally incremental: proceed to Step 3.
Step 3: Can you process elements one by one, maintaining a heap?
- YES: Greedy with Undo / Slope Trick. \(O(n \log n)\) total.
- NO (complex 2D structure, etc.): WQS is still your best bet, applied once per needed \(K\).
| Scenario | Best technique | Why |
|---|---|---|
| One specific \(K\), large \(n\) | WQS | \(O(n \log V)\), avoids \(K\) dimension |
| All \(K\) values needed | Slope Trick | \(O(n \log n)\), full curve |
| Small \(K\), need the actual solution | Greedy + Undo | \(O(K \log n)\), concrete picks |
| Unsure about concavity | DP or MCMF | Safety first |
The Code
#include <bits/stdc++.h>
using namespace std;
pair<long long, int> calculateUnconstrained(const vector<int>& elements, long long penaltyLambda) {
int numElements = elements.size();
vector<array<long long, 2>> maxAdjustedValue(numElements, {0, 0});
vector<array<int, 2>> elementsPickedCount(numElements, {0, 0});
maxAdjustedValue[0][0] = 0;
elementsPickedCount[0][0] = 0;
maxAdjustedValue[0][1] = elements[0] - penaltyLambda;
elementsPickedCount[0][1] = 1;
for (int i = 1; i < numElements; i++) {
if (maxAdjustedValue[i-1][0] >= maxAdjustedValue[i-1][1]) {
maxAdjustedValue[i][0] = maxAdjustedValue[i-1][0];
elementsPickedCount[i][0] = elementsPickedCount[i-1][0];
} else {
maxAdjustedValue[i][0] = maxAdjustedValue[i-1][1];
elementsPickedCount[i][0] = elementsPickedCount[i-1][1];
}
long long baseProfit = (i >= 2) ? max(maxAdjustedValue[i-2][0], maxAdjustedValue[i-2][1]) : 0;
int baseCount = 0;
if (i >= 2) {
baseCount = (maxAdjustedValue[i-2][0] >= maxAdjustedValue[i-2][1]) ? elementsPickedCount[i-2][0] : elementsPickedCount[i-2][1];
}
maxAdjustedValue[i][1] = baseProfit + elements[i] - penaltyLambda;
elementsPickedCount[i][1] = baseCount + 1;
}
if (maxAdjustedValue[numElements-1][0] >= maxAdjustedValue[numElements-1][1]) {
return {maxAdjustedValue[numElements-1][0], elementsPickedCount[numElements-1][0]};
} else {
return {maxAdjustedValue[numElements-1][1], elementsPickedCount[numElements-1][1]};
}
}
long long solveUsingWQS(vector<int>& elements, int targetK) {
long long lowPenalty = 0, highPenalty = 2e9, finalResult = 0;
while (lowPenalty <= highPenalty) {
long long penaltyLambda = lowPenalty + (highPenalty - lowPenalty) / 2;
auto [adjustedValue, count] = calculateUnconstrained(elements, penaltyLambda);
if (count >= targetK) {
finalResult = adjustedValue + penaltyLambda * targetK;
lowPenalty = penaltyLambda + 1;
} else {
highPenalty = penaltyLambda - 1;
}
}
return finalResult;
}
long long solveUsingUndo(vector<int>& elements, int targetK) {
int numElements = elements.size();
vector<long long> currentValues(numElements);
vector<int> previousIndex(numElements), nextIndex(numElements);
vector<bool> isRemoved(numElements, false);
for (int i = 0; i < numElements; i++) {
currentValues[i] = elements[i];
previousIndex[i] = i - 1;
nextIndex[i] = i + 1;
}
priority_queue<pair<long long, int>> availableGains;
for (int i = 0; i < numElements; i++) {
availableGains.push({currentValues[i], i});
}
long long totalAccumulatedValue = 0;
for (int iteration = 0; iteration < targetK; iteration++) {
while (isRemoved[availableGains.top().second]) {
availableGains.pop();
}
auto [bestGain, currentIndex] = availableGains.top();
availableGains.pop();
totalAccumulatedValue += bestGain;
long long undoValue = -bestGain;
int leftSide = previousIndex[currentIndex];
int rightSide = nextIndex[currentIndex];
if (leftSide >= 0) undoValue += currentValues[leftSide];
if (rightSide < numElements) undoValue += currentValues[rightSide];
if (leftSide >= 0) {
isRemoved[leftSide] = true;
if (previousIndex[leftSide] >= 0) {
nextIndex[previousIndex[leftSide]] = currentIndex;
}
previousIndex[currentIndex] = previousIndex[leftSide];
}
if (rightSide < numElements) {
isRemoved[rightSide] = true;
if (nextIndex[rightSide] < numElements) {
previousIndex[nextIndex[rightSide]] = currentIndex;
}
nextIndex[currentIndex] = nextIndex[rightSide];
}
currentValues[currentIndex] = undoValue;
availableGains.push({undoValue, currentIndex});
}
return totalAccumulatedValue;
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
int numElements, targetK;
cin >> numElements >> targetK;
vector<int> elements(numElements);
for (int i = 0; i < numElements; i++) {
cin >> elements[i];
}
long long resultWQS = solveUsingWQS(elements, targetK);
long long resultUndo = solveUsingUndo(elements, targetK);
cout << resultWQS << " " << resultUndo << "\n";
return 0;
}
Try It
Implement both methods in the starter code and verify they agree.
Test case 1:
Before coding, predict: what marginal gains will the greedy-with-undo produce? What \(\lambda\) will WQS converge to?Test case 2:
What would happen if you asked for \(K=4\)? Is \(h(4)\) even defined? With 7 elements and non-adjacency, what's the maximum number of picks?Test case 3 (flat edge detector):
Here \(m(1) = 5\) and \(m(2) = 5\) — a flat edge. Does WQS binary search find the right \(\lambda\)? What happens when the inner solver reports count=3 at one \(\lambda\) and count=1 at the next?Challenge: Prove that \(h(k)\) is always concave for the "non-adjacent picks" problem on ANY array. (Hint: consider adding the \((k+1)\)-th element — you must skip neighbors of all \(k\) existing picks, leaving fewer and worse options. The available pool shrinks, so marginal gains must decrease.)
Looking Ahead: JOISC 2018 Safety
The ultimate test of the unification. The naive DP is \(O(N \cdot V)\) where \(V\) can be \(10^9\). Slope Trick with two priority queues solves it in \(O(N \log N)\).
Problem (simplified): \(N\) guards on a number line at positions \(p_i\). Move guards so that consecutive guards are at least \(L\) apart. Minimize total movement cost (L1 distance).
Slope Trick approach: The cost function (as a function of the last guard's position) is piecewise linear and convex. Maintain its slopes in two priority queues: one for the left part (slopes \(\leq 0\), max-heap) and one for the right part (slopes \(\geq 0\), min-heap).
For each new guard: 1. Add the new guard's cost function (a V-shape centered at \(p_i\)): push \(p_i\) to both heaps 2. Apply the spacing constraint (shift by \(L\)): add \(L\) to all entries in the right heap (lazy offset) 3. Merge if heaps cross: if the max of the left heap exceeds the min of the right heap, pop both and swap
The lazy shifting avoids touching all heap entries. Each guard needs \(O(\log N)\) heap operations. Total: \(O(N \log N)\) — a factor of \(10^9\) improvement over naive DP.
If you can solve this problem, you've fully mastered this chapter.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| IOI 2016 — Aliens | oj.uz/problem/view/IOI16_aliens | IOI Hard |
| JOISC 2018 — Safety | oj.uz/problem/view/JOI18_safety | Very Hard |
| CF 713C — Sonya and Problem Without a Legend | codeforces.com/problemset/problem/713/C | 2000 |
| CF 865D — Buy Low, Sell High | codeforces.com/problemset/problem/865/D | 2400 |
| CF 802O — April Fools' Problem | codeforces.com/problemset/problem/802/O | 2900 |
| APIO 2014 — Sequence | oj.uz/problem/view/APIO14_sequence | Hard |