Idempotency and Compensation
TL;DR
Idempotency makes operations safe to retry — the client generates a UUID, the server deduplicates by checking if that key was already processed. Compensation handles failures after partial completion: forward recovery retries the failed step, backward recovery undoes completed steps in reverse, and the pivot transaction marks the point of no return where the strategy switches from "undo everything" to "keep retrying forward." Order your workflow steps so hard-to-compensate actions happen last. Combine these with exponential backoff, dead letter queues, and human escalation for a complete error handling strategy.
Idempotency Keys — Making Retries Safe
The timeout problem from Lesson 1: you charged the customer's card but the response was lost. Did the charge go through? If you retry, you might double-charge them. If you don't retry, they might not be charged at all.
Idempotency solves this. An idempotent operation produces the same result regardless of how many times you execute it. Charging a card isn't naturally idempotent — but you can make it idempotent with a key.
How It Works
The client generates a unique ID (UUID) for each logical operation and sends it with the request. The server uses this key to deduplicate:
def charge_payment(order_id, amount, idempotency_key):
# Step 1: Check if we already processed this key
existing = db.query(
"SELECT result FROM idempotency_store WHERE key = %s",
idempotency_key,
)
if existing:
# Already processed — return the stored result
return existing.result
# Step 2: Process the charge
result = stripe.charges.create(
amount=amount,
currency="usd",
)
# Step 3: Store the result keyed by idempotency_key
db.execute(
"INSERT INTO idempotency_store (key, result, created_at) "
"VALUES (%s, %s, NOW())",
idempotency_key,
json.dumps(result),
)
return result
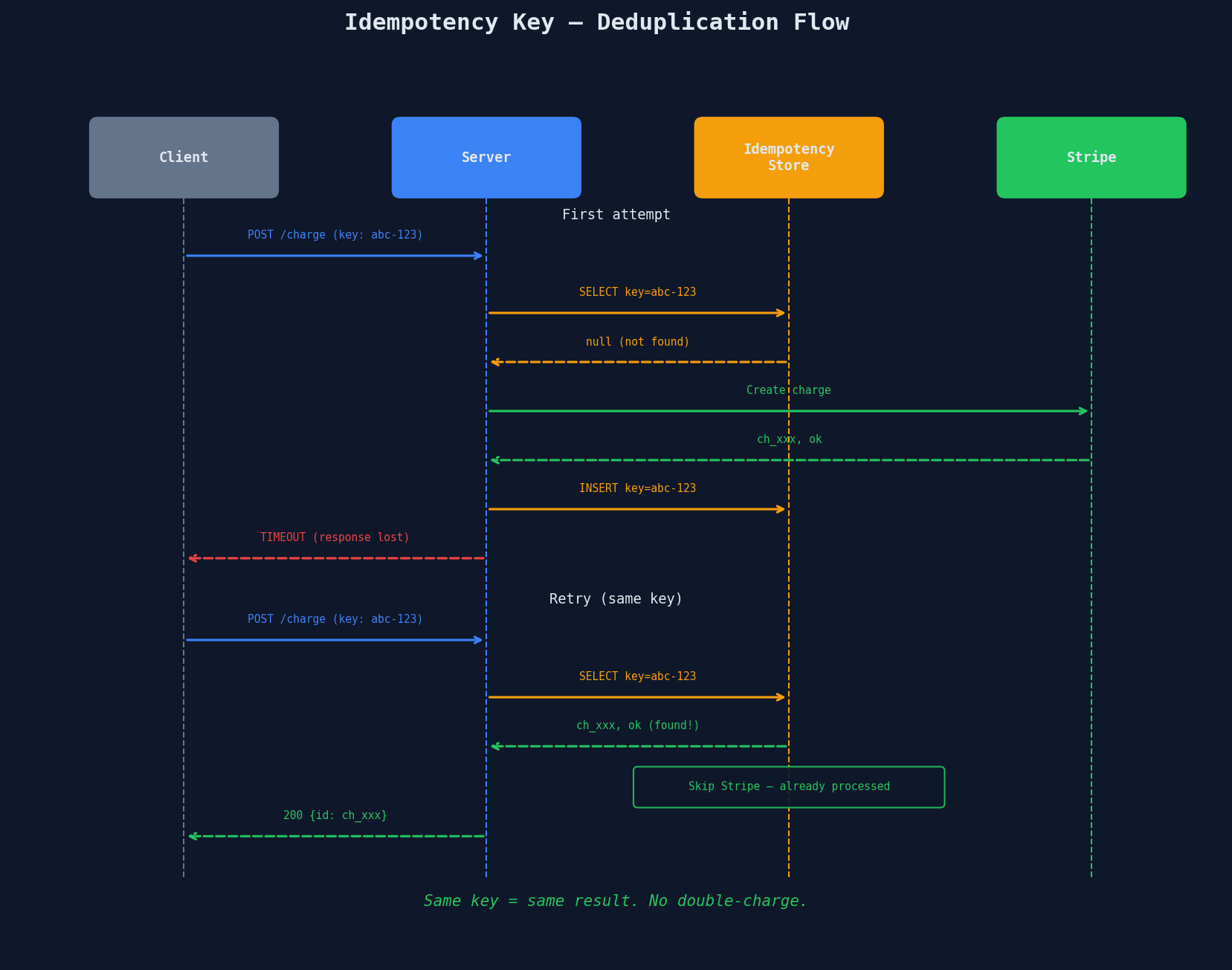
The retry hits the idempotency store, finds the existing result, and returns it without calling Stripe again. No double-charge. The client gets the correct response. Everyone's happy.
Key Design Decisions
Key format: Use {entity_type}-{entity_id}-{operation} or let the client generate a UUID. Example: order-12345-payment or 550e8400-e29b-41d4-a716-446655440000.
TTL: Don't keep idempotency records forever. Stripe uses a 24-hour TTL — after that, the same key can trigger a new charge. This prevents the idempotency store from growing unbounded while covering the retry window.
Atomicity: The charge and the idempotency record insert must happen atomically (same database transaction or using a compare-and-swap operation). If you charge the card but crash before inserting the idempotency record, retries will double-charge.
| Decision | Recommendation |
|---|---|
| Key generation | Client-side UUID or deterministic {entity}-{id}-{op} |
| Storage | Same database as your application (transactional consistency) |
| TTL | 24 hours (covers retry storms, keeps storage bounded) |
| Scope | One key per logical operation, not per HTTP request |
| Concurrency | Use INSERT ... ON CONFLICT DO NOTHING or distributed lock |
Stripe's idempotency implementation is the gold standard — 24-hour TTL, client-generated keys, and atomic storage with the charge result.
Interview Tip
When you mention retries in a system design interview, always pair them with idempotency. "We'll retry failed payments with an idempotency key so retries don't double-charge." This is a signal of production experience — junior engineers add retries and forget about duplicates.
Compensation Strategies — Undoing the Damage
Idempotency makes individual steps safe to retry. But what about multi-step workflows where a later step fails after earlier steps succeeded? You need to compensate — undo the effects of completed steps.
There are three strategies, and the choice depends on where in the workflow the failure occurs.
Forward Recovery: Push Through
If the failed step is idempotent and retriable, just keep retrying. The workflow stalls temporarily but eventually completes.
Step 1: Charge payment ✓ (completed)
Step 2: Reserve inventory ✓ (completed)
Step 3: Schedule shipping ✗ (failed — carrier API down)
Forward recovery: Retry step 3 with exponential backoff
→ Attempt 2 (after 1s): ✗ still down
→ Attempt 3 (after 4s): ✗ still down
→ Attempt 4 (after 16s): ✓ carrier is back
→ Continue to step 4
When to use: The failing step is transient (network blip, temporary outage), the step is idempotent, and the business can tolerate the delay.
Backward Recovery: Undo in Reverse
If the failing step can't be retried (permanent error like "out of stock"), you must undo all completed steps in reverse order.
Step 1: Charge payment ✓ → Compensate: Refund payment
Step 2: Reserve inventory ✓ → Compensate: Release reservation
Step 3: Schedule shipping ✗ (permanent failure)
Backward recovery (reverse order):
→ Release inventory reservation
→ Refund payment
→ Mark order as cancelled
Why reverse order? Because later steps may depend on earlier ones. You can't release inventory before refunding the payment if the refund logic checks inventory status. Reversing the order respects the dependency chain.
The Pivot Transaction
Here's the key insight that ties forward and backward recovery together. In most workflows, there's a point of no return — a step after which you switch from "undo everything if it fails" to "keep retrying until it succeeds."
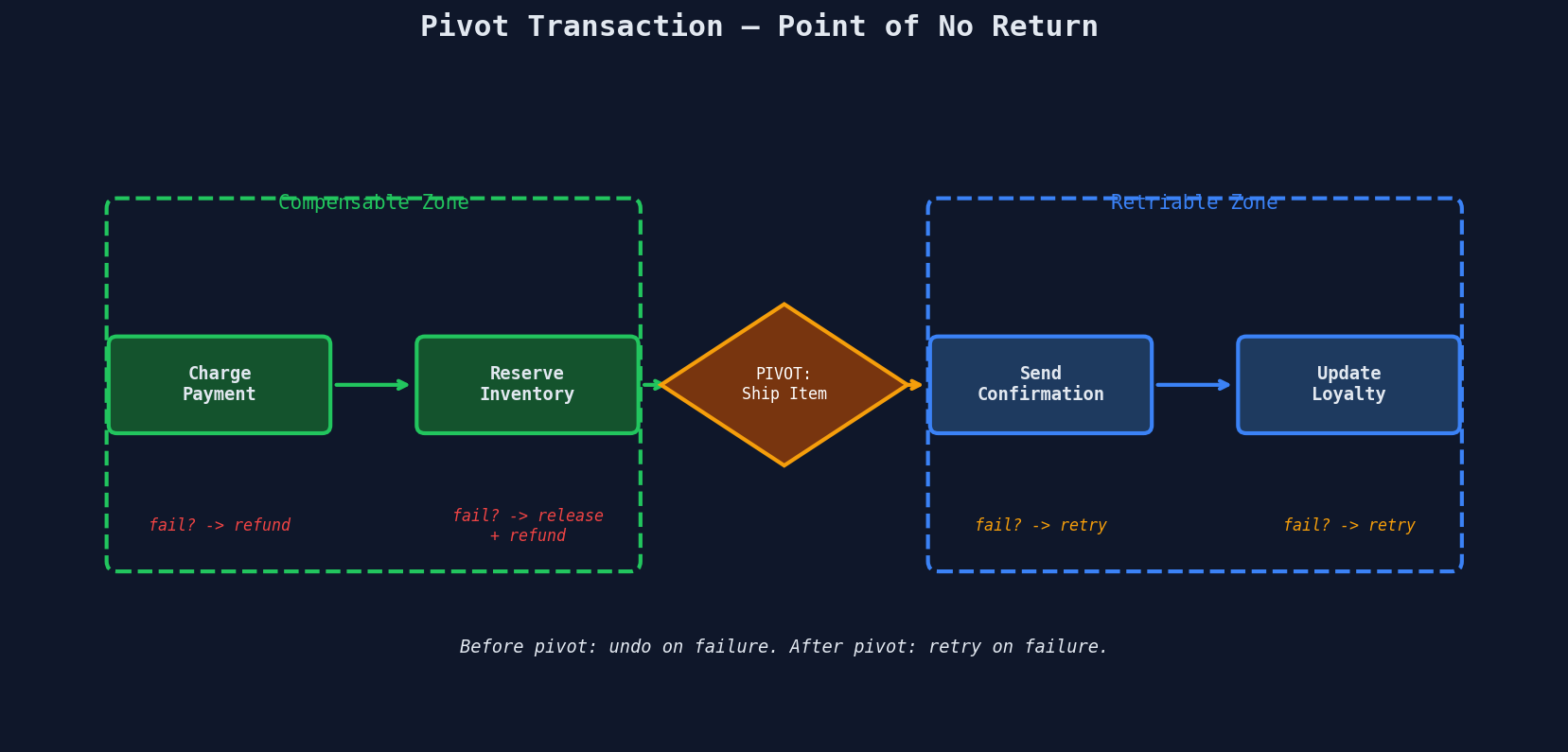
Before the pivot: Every step has a compensating action. If anything fails, run compensation in reverse.
The pivot itself: The point of no return. Once you ship a physical item, you can't un-ship it cheaply. This step must be retriable and idempotent.
After the pivot: Steps are retriable (email, loyalty points). If they fail, retry — don't undo the shipment.
The pivot transaction is usually the step that causes a real-world side effect that's expensive or impossible to reverse: shipping a package, publishing a document, executing a trade.
Compensation Difficulty Is Not Equal
Not all compensating actions are created equal. This matters because it determines how you order your workflow steps:
| Step | Compensating Action | Difficulty | Time to Complete |
|---|---|---|---|
| Reserve inventory | Release reservation | Easy | Milliseconds |
| Charge payment | Refund | Medium | 5-10 business days |
| Send email | Send correction email | Medium | Cannot unsend |
| Ship package | Recall shipment | Hard | Days, expensive |
| Execute trade | Reverse trade | Very Hard | Market conditions changed |
The Golden Rule of Step Ordering
Order your workflow steps so that hard-to-compensate actions happen last, as close to the pivot as possible. Reserve inventory (easy to undo) before charging the card (refunds take days). Charge the card before shipping the package (can't un-ship). This minimizes the damage of partial failures.
Error Handling Patterns
Idempotency and compensation handle the what. These patterns handle the how.
Exponential Backoff with Jitter
Don't retry immediately. Don't retry at fixed intervals. Use exponential backoff so you don't hammer a struggling service, and add jitter so multiple clients don't retry in lockstep.
import random
def retry_with_backoff(fn, max_attempts=5):
for attempt in range(max_attempts):
try:
return fn()
except TransientError:
if attempt == max_attempts - 1:
raise # final attempt failed
# Exponential backoff: 1s, 2s, 4s, 8s, 16s
base_delay = 2 ** attempt
# Add jitter: ±50% of base delay
jitter = base_delay * random.uniform(0.5, 1.5)
sleep(jitter)
Retry schedule with jitter:
─────────────────────────────────────────
Attempt 1: immediate
Attempt 2: ~1s (0.5 - 1.5s)
Attempt 3: ~2s (1.0 - 3.0s)
Attempt 4: ~4s (2.0 - 6.0s)
Attempt 5: ~8s (4.0 - 12.0s)
─────────────────────────────────────────
Total max wait: ~22.5 seconds
Without jitter, if 1,000 clients all fail at the same time (because the service went down), they all retry at exactly t+1s, creating a thundering herd that crushes the recovering service.
Dead Letter Queues
After all retries are exhausted, the message goes to a dead letter queue (DLQ) instead of being dropped. The DLQ is a parking lot for permanently failing work items.
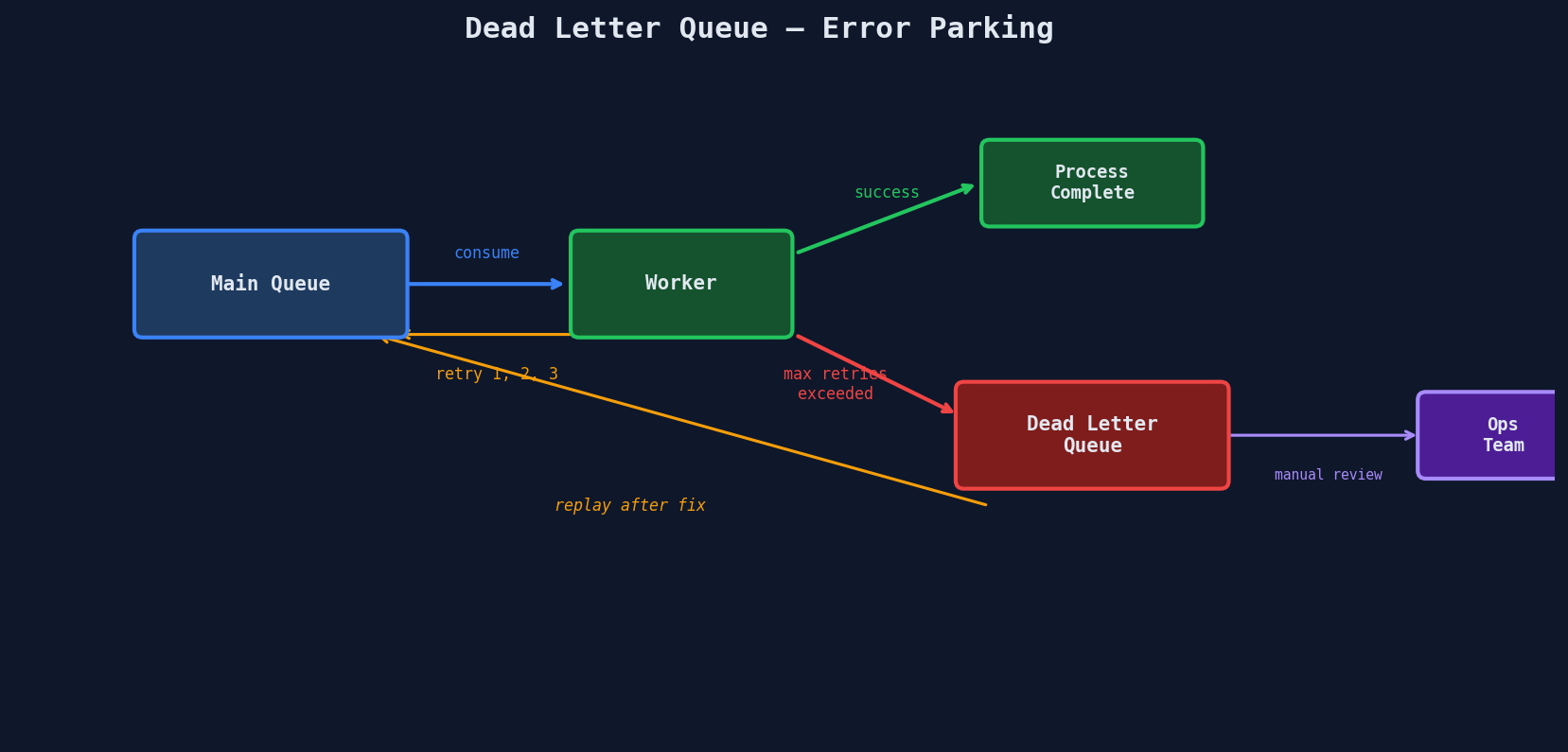
DLQs prevent data loss. Without one, a permanently failing step silently drops the work item and the order is stuck forever with no trace. With a DLQ, you get a clear inventory of broken items to investigate.
Human-in-the-Loop Escalation
Some failures require human judgment. The automated system has done everything it can, and a person needs to decide what happens next.
Escalation ladder:
───────────────────────────────────────────────
Level 1: Automatic retry (3 attempts)
Level 2: Delay and retry (exponential backoff)
Level 3: Dead letter queue + alert to on-call
Level 4: Support ticket created for manual review
Level 5: Customer notified of delay
───────────────────────────────────────────────
Design your workflows to handle this gracefully. Temporal signals and durable timers are perfect for human escalation — the workflow waits (potentially for days) for a human to take action, then resumes.
Timeout Handling
Every external call needs a timeout. Every timeout needs a plan.
| Timeout Type | Duration | Action on Timeout |
|---|---|---|
| API call | 5-30 seconds | Retry with idempotency key |
| Queue processing | 1-5 minutes | Requeue for another worker |
| Human action | Hours to days | Send reminder, then escalate |
| Workflow overall | Depends on SLA | Cancel + compensate + notify |
Webhook Delivery — Idempotency at Scale
Webhooks are how services notify each other asynchronously. But what happens when the receiver is down? You need a retry schedule.
Webhook retry schedule (typical):
═══════════════════════════════════════════════
Attempt 1: Immediate
Attempt 2: 1 second later
Attempt 3: 5 seconds later
Attempt 4: 30 seconds later
Attempt 5: 5 minutes later
Attempt 6: 30 minutes later
Attempt 7: 2 hours later
Attempt 8: 8 hours later
Attempt 9: 24 hours later
═══════════════════════════════════════════════
After 24 hours: Mark as failed, alert, stop retrying
The receiver MUST be idempotent because it will receive the same webhook multiple times — both from retries and from at-least-once delivery guarantees. Every webhook should include an event ID that the receiver uses for deduplication.
# Webhook receiver (idempotent)
def handle_webhook(event):
if db.exists("processed_webhooks", event["id"]):
return 200 # Already processed — acknowledge without re-processing
process_event(event)
db.insert("processed_webhooks", event["id"], ttl=72*3600)
return 200
Stripe retries webhooks on the schedule above for up to 72 hours. Airbnb uses durable timers to give hosts exactly 24 hours to accept a booking — if the timer expires, the workflow automatically moves to the next host.
Putting It All Together
Here's the complete error handling strategy for a distributed workflow:
┌─────────────────────────────────────────────────────────┐
│ ERROR HANDLING STACK │
├─────────────────────────────────────────────────────────┤
│ │
│ Layer 1: IDEMPOTENCY │
│ → Every step is safe to retry │
│ → Client UUID + server deduplication │
│ │
│ Layer 2: RETRY with BACKOFF │
│ → Transient failures resolve themselves │
│ → Exponential backoff + jitter prevents thundering herd│
│ │
│ Layer 3: COMPENSATION │
│ → Permanent failures trigger undo in reverse │
│ → Pivot transaction marks point of no return │
│ → Hard-to-compensate steps happen last │
│ │
│ Layer 4: DEAD LETTER QUEUE │
│ → Permanently failing items are parked, not dropped │
│ → Inventory for investigation and replay │
│ │
│ Layer 5: HUMAN ESCALATION │
│ → Automated systems hand off to humans │
│ → Durable timers wait for human action │
│ │
│ Layer 6: OBSERVABILITY │
│ → Correlation IDs across all services │
│ → Distributed tracing shows exact failure point │
│ → Dashboards show workflow completion rates │
│ │
└─────────────────────────────────────────────────────────┘
Quick Recap
| Concept | Key Takeaway |
|---|---|
| Idempotency keys | Client UUID + server deduplication = safe retries |
| TTL on idempotency | 24 hours covers retry storms without unbounded storage |
| Forward recovery | Retry the failed step (transient errors, idempotent steps) |
| Backward recovery | Undo completed steps in reverse order |
| Pivot transaction | Point of no return — compensable before, retriable after |
| Step ordering | Hard-to-compensate actions go last |
| Exponential backoff | 2^attempt delay with jitter prevents thundering herd |
| Dead letter queue | Parking lot for permanently failing work items |
| Human escalation | Automated systems hand off when they can't resolve |
| Webhook retries | Progressive schedule up to 24h, receiver must be idempotent |
Interview Tip
When designing a distributed workflow in an interview, sketch the steps on the whiteboard, then draw a vertical line marking the pivot transaction. Label everything before the pivot as "compensable" and everything after as "retriable." Then say: "We order the steps so hard-to-undo actions are as close to the pivot as possible." This demonstrates a structured approach to error handling that most candidates miss entirely. It turns a hand-wavy "we'll add retries" into a concrete, defensible strategy.