Slope Trick Intro
The Problem That Ties Everything Together
This is the deepest lesson in the greedy course. Not because the code is complex — the final solution is 20 lines. But because it reveals that three techniques you've been learning are actually the same thing wearing different hats.
Here's the problem: given an array, make it strictly increasing by changing elements. Minimize the total cost, where cost \(= \sum |a_i - b_i|\) (L1 distance).
The Greedy Choice: Push each element twice into a max-heap (adds a V-shape to the cost function), pop once (trims the right side to enforce monotonicity). The cost increases by exactly the trimmed amount.
This is CF713C (Sonya and Problem Without a Legend, rated 2000).
The brute-force DP has a continuous state space. Slope trick compresses it into a priority queue.
But first, the punchline:
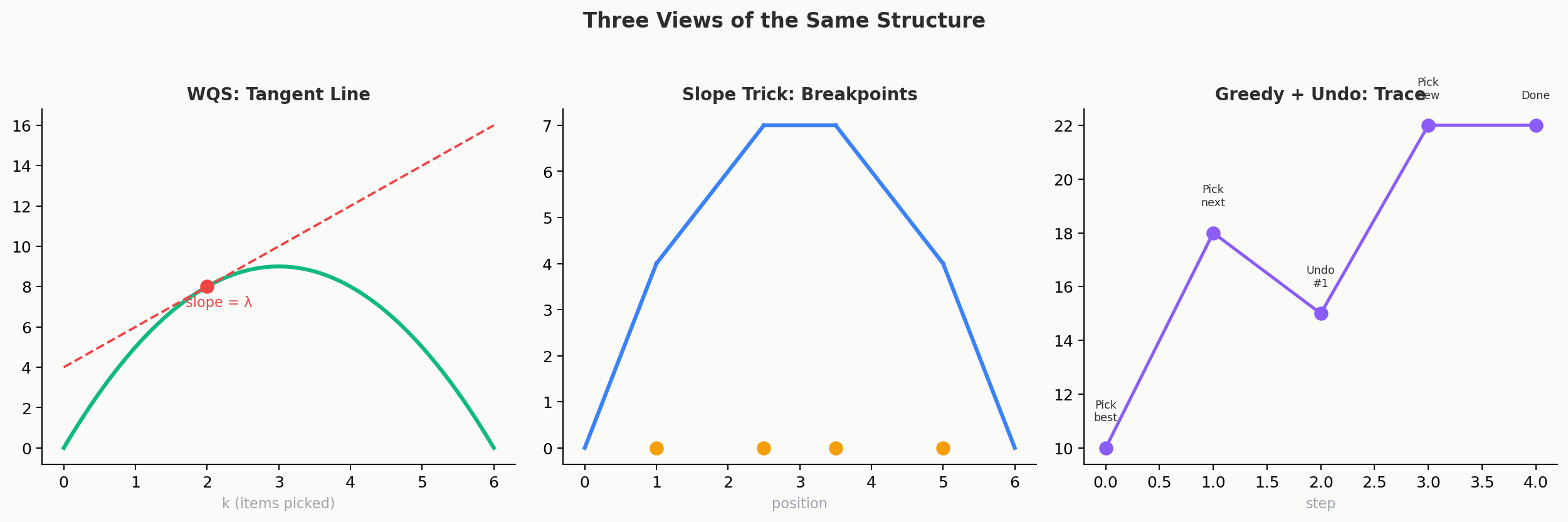
Slope Trick, Greedy with Undo, and WQS Binary Search are three views of the same underlying mathematical structure.
By the end of this lesson, you'll see that "push twice, pop once" IS "pick element, insert undo token" from Lesson 1, just described in the language of convex functions instead of linked lists.
The Three Views (Preview)
Don't worry if this table doesn't make complete sense yet. Use it as a roadmap. By the end of this lesson, you will understand exactly what each row means.
| View | Metaphor | What it does |
|---|---|---|
| WQS Binary Search | A ruler held against a curve | Penalize each pick by \(\lambda\), binary search to hit target \(k\) |
| Slope Trick | A map of all slopes | Store breakpoints of convex DP cost function in a PQ |
| Greedy with Undo | Plain English Slope Trick | Pick best, leave breadcrumb to reverse |
Step 1: The Transformation
Strictly increasing means \(b_1 < b_2 < \ldots < b_n\), i.e., \(b_{i+1} - b_i \geq 1\).
Trick: Define \(c_i = a_i - i\). Then requiring the \(b\) sequence to be strictly increasing is equivalent to requiring the transformed sequence \(d_i = c_i + \delta_i\) to be non-decreasing.
Why? If \(b_i < b_{i+1}\), then \(b_{i+1} \geq b_i + 1\). Subtract indices: \((b_{i+1} - (i+1)) \geq (b_i - i)\). The transformed sequence only needs weak monotonicity. Simpler to work with.
The cost doesn't change: \(|a_i - b_i| = |c_i - d_i|\) (we subtracted the same \(i\) from both).
From now on: we work with \(c_i = a_i - i\) and find a non-decreasing \(d\) minimizing \(\sum |c_i - d_i|\).
Step 2: The DP (and Why It Seems Impossible)
Think about building the non-decreasing sequence one element at a time. After deciding the first \(i-1\) elements, the only thing that matters for element \(i\) is: "what value did I assign to element \(i-1\)?" If I set element \(i-1\) to value \(u\), then element \(i\) must be \(\geq u\). The cost I paid for element \(i-1\) depends on \(u\) too. So we track the cost as a function of the last assigned value.
Define:
Recurrence:
The answer is \(\min_v f_n(v)\).
The trap: \(v\) is any integer — not drawn from a fixed set. Our DP "table" would need one column per possible integer value, which is infinitely wide. You can't iterate over all \(v\).
Here is the structural intuition that saves us: \(f_i(v)\) has a completely predictable shape.
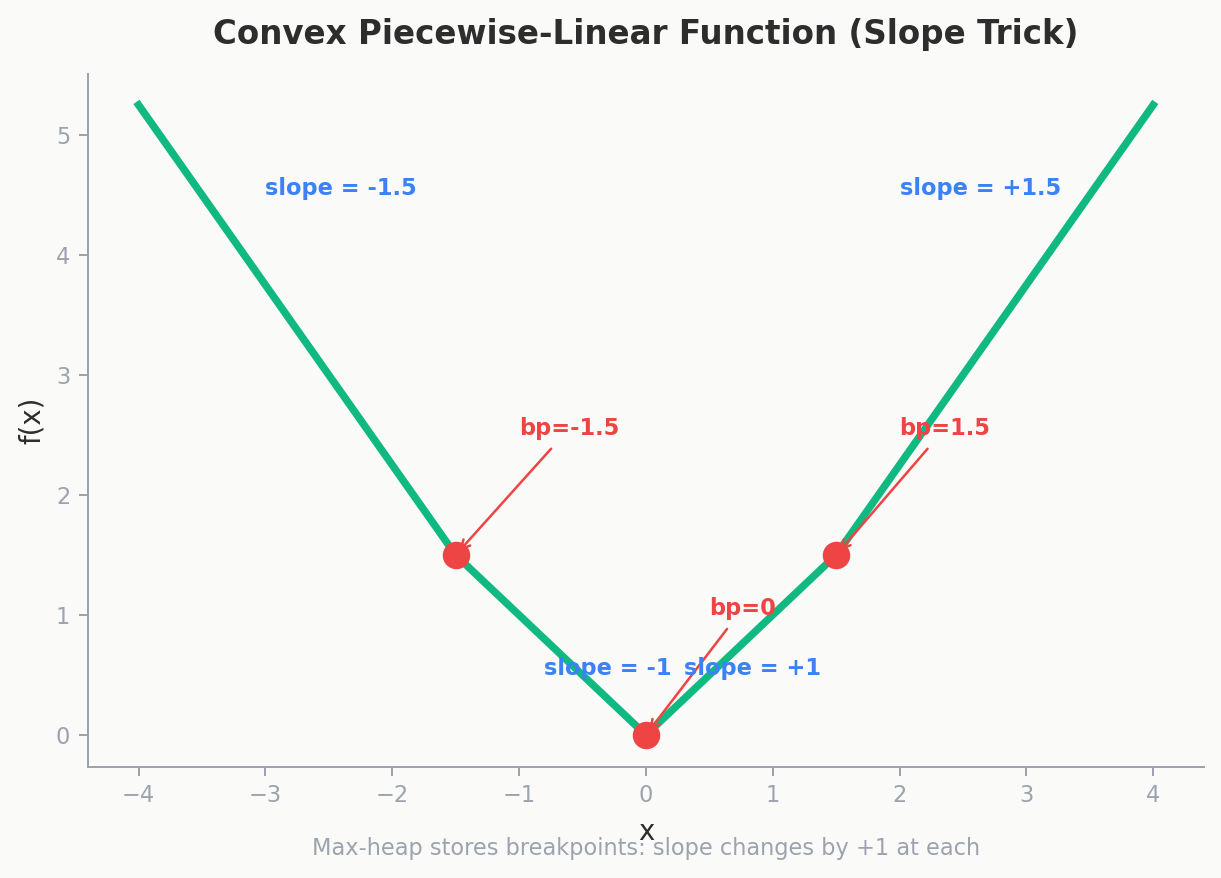
Step 3: Why \(f_i(v)\) Is Convex (and Why That Saves Us)
Claim: \(f_i(v)\) is a convex piecewise-linear function for every \(i\). Think of a curve made entirely of straight line segments that bends strictly upward — high cost on both sides, low in the middle, like a bowl.
Base case: \(f_1(v) = |c_1 - v|\). A V-shape centered at \(c_1\). Slopes: \(-1\) then \(+1\). Convex.
Inductive step: Assume \(f_{i-1}\) is convex piecewise-linear. Two operations happen:
-
Prefix minimum: \(g(v) = \min_{u \leq v} f_{i-1}(u)\). Imagine sweeping a pointer from left to right along \(f_{i-1}\), tracking the smallest value seen so far. On the left side (negative slopes), \(f_{i-1}\) is decreasing, so each new value IS the new minimum — \(g\) copies \(f_{i-1}\) exactly. Once we pass the bowl's bottom, \(f_{i-1}\) starts increasing — but our running minimum stays flat at the bottom value. The entire right side becomes a plateau at slope 0. All positive slopes are erased. This is why we only need a max-heap: we track positive-slope breakpoints, and prefix minimum wipes them when they're too far right.
-
Add the V-shape: \(f_i(v) = g(v) + |c_i - v|\). Sum of two convex functions is convex. The V-shape at \(c_i\) introduces new slope changes, and \(g\) provides the "history" of previous elements.
A convex piecewise-linear function is fully described by two things:
- Its minimum value (the bottom of the bowl)
- Its breakpoints — the x-values where the slope changes by \(+1\)
Instead of storing the entire function, store the breakpoints in a max-heap. That's slope trick.
Step 4: The Update Rule — "Push Twice, Pop Once"
Let's translate that shape into operations. When processing element \(c_i\):
Adding \(|c_i - v|\): Each element in our priority queue represents a point where the slope of our bowl increases by exactly \(+1\). The V-shape \(|c_i - v|\) bends the slope upward by \(+2\) total (from \(-1\) on the left to \(+1\) on the right). To model this, we must insert two \(+1\) breakpoints at position \(c_i\). So: push \(c_i\) twice into the max-heap.
Taking prefix minimum (enforcing non-decreasing): The prefix minimum operation \(g(v) = \min_{u \leq v} f_{i-1}(u)\) forces the right side of the bowl to be perfectly flat at slope 0. If the rightmost breakpoint is at position \(t > c_i\), its positive slope shouldn't be there anymore. Popping the maximum breakpoint deletes the steepest positive slope on the far right, successfully enforcing this flat right side. So: pop the max from the heap.
Updating cost: If the popped breakpoint \(t > c_i\), cost increases by \((t - c_i)\). This is the "trimming cost" — we're clipping the right side of the bowl.
The complete update:
1. Push c_i into max-heap (twice)
2. Pop the maximum breakpoint t
3. totalCost += t - c_i (always >= 0 since c_i was just pushed)
Since \(c_i\) was just pushed, the max is at least \(c_i\), so \(t \geq c_i\). The cost increment is always non-negative.
What breaks if you get this wrong?
- Push once instead of twice: You're adding a slope change of \(+1\) instead of \(+2\). The V-shape \(|c_i - v|\) changes slope by 2 (from \(-1\) to \(+1\)). Push once and you're modeling the wrong function — the algorithm silently gives incorrect answers.
- Don't pop: You never enforce the non-decreasing constraint. The function accumulates breakpoints without limit, the right side's slope grows unboundedly. You're computing the unconstrained sum of absolute values, ignoring that each element must be \(\geq\) the previous.
Full Trace
Array: \(a = [5, 3, 4, 2, 6]\). Transformed: \(c_i = a_i - i = [5, 2, 2, -1, 2]\).
Stare at this table. Every column matters.
| \(i\) | \(c_i\) | Push \(c_i\) twice | Heap (max first) | Pop max \(t\) | cost \(+= t - c_i\) | Total cost | Heap after pop |
|---|---|---|---|---|---|---|---|
| 0 | 5 | push 5, 5 | {5, 5} | \(t = 5\) | \(5 - 5 = 0\) | 0 | {5} |
| 1 | 2 | push 2, 2 | {5, 2, 2} | \(t = 5\) | \(5 - 2 = 3\) | 3 | {2, 2} |
| 2 | 2 | push 2, 2 | {2, 2, 2, 2} | \(t = 2\) | \(2 - 2 = 0\) | 3 | {2, 2, 2} |
| 3 | -1 | push -1, -1 | {2, 2, 2, -1, -1} | \(t = 2\) | \(2 - (-1) = 3\) | 6 | {2, 2, -1, -1} |
| 4 | 2 | push 2, 2 | {2, 2, 2, 2, -1, -1} | \(t = 2\) | \(2 - 2 = 0\) | 6 | {2, 2, 2, -1, -1} |
Answer: 6.
Manual Verification
The optimal non-decreasing sequence for \(c = [5, 2, 2, -1, 2]\) is \(d = [2, 2, 2, 2, 2]\). Cost \(= |5-2| + |2-2| + |2-2| + |-1-2| + |2-2| = 3 + 0 + 0 + 3 + 0 = 6\). Matches.
What about \(d = [2, 2, 2, -1, 2]\)? That's not non-decreasing (\(-1 < 2\)). Invalid.
What about \(d = [-1, -1, -1, -1, 2]\)? Cost \(= 6 + 3 + 3 + 0 + 0 = 12\). Worse.
The algorithm found the global optimum.
Why "Push Twice, Pop Once" IS the Undo Trick
Here's the connection that unifies the chapter:
Push twice = greedily include element \(c_i\) and leave a breadcrumb. Pop once = a conflict occurred; undo the most punishing past decision.
When we pop breakpoint \(t > c_i\), we're saying: "some earlier element wanted the sequence to go up to \(t\), but \(c_i\) is only \(c_i\), so we pay \((t - c_i)\) to trim that ambition." We push \(c_i\) as a replacement — the undo token — letting future elements undo THIS decision too.
This is the same operation as "pick element \(i\), insert \(V = L + R - \text{picked}\)" from Lesson 1, but in the language of convex function breakpoints.
The Three Views Unified
Let's tie this back to the three paradigms we introduced earlier.
WQS = Probe the Curve
WQS Binary Search asks: "if I penalize each selected item by \(\lambda\), what's the optimal count?" By varying \(\lambda\), you trace the convex envelope. \(\lambda\) is a ruler at different angles; the tangent point tells you the optimal \(k\) for that angle.
Slope Trick = Store the Curve
Slope trick stores the entire slope structure of the DP cost function — all breakpoints, the full piecewise-linear shape. While WQS asks "what's the tangent at angle \(\lambda\)?", slope trick has the whole curve.
The max-heap literally encodes every slope change. You have the complete information.
Greedy with Undo = Build the Curve Incrementally
Greedy with undo is slope trick in plain English. "Pick the best available" = "process next element, update breakpoints." "Insert undo token" = "push new breakpoints." "Pop if conflict" = "trim the rightmost breakpoint."
The linked list + heap from Lesson 1 was maintaining breakpoints of a convex function. We just never called it that.
The Mathematical Bridge
The priority queue in slope trick maintains the slopes of the convex cost function. Popping the max breakpoint is equivalent to finding the next optimal \(\lambda\) in WQS. And the undo formula \(V = A_L + A_R - A_i\) from Lesson 1 is the marginal gain:
where \(f(j)\) is the optimal value when picking \(j\) items. The undo element's value tells you exactly how much the total changes when you pick one more item. This is the derivative of the cost curve — the slope — which is what the priority queue stores.
So:
- Lesson 1's undo element = a slope / marginal gain
- Slope trick's breakpoint = same slope, stored explicitly
- WQS's \(\lambda\) = the specific slope being probed
Three names for the same quantity.
Where This Fits in the Landscape
Matroids / Greedoids
Pure greedy is optimal (exchange property holds)
Examples: MST, scheduling with deadlines
Submodular Functions
Greedy gives (1 - 1/e) approximation
Examples: set cover, influence maximization
"Escapes" from non-matroid structures:
WQS Binary Search — probe the convex hull
Slope Trick — store the convex hull
Greedy with Undo — incrementally build the convex hull
Min-Cost Max-Flow — the "universal solvent" (always works, but slow)
When the structure is not a matroid (like "no adjacent elements"), pure greedy fails. These four techniques all exploit the same convexity/concavity structure to recover optimality. They differ in which aspect they make explicit.
Min-cost max-flow is the most general but slowest (\(O(n^2)\) or worse). Slope trick and greedy-with-undo achieve \(O(n \log n)\) by exploiting piecewise-linear structure.
The Code
#include <bits/stdc++.h>
using namespace std;
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
int numElements;
cin >> numElements;
vector<long long> originalArray(numElements);
for (int i = 0; i < numElements; i++) {
cin >> originalArray[i];
originalArray[i] -= i;
}
auto maxHeapCompare = [](long long a, long long b) {
return a < b;
};
priority_queue<long long, vector<long long>, decltype(maxHeapCompare)> breakpointHeap(maxHeapCompare);
long long totalCost = 0;
for (int i = 0; i < numElements; i++) {
breakpointHeap.push(originalArray[i]);
breakpointHeap.push(originalArray[i]);
long long largestBreakpoint = breakpointHeap.top();
breakpointHeap.pop();
totalCost += largestBreakpoint - originalArray[i];
}
cout << totalCost << "\n";
return 0;
}
20 lines of logic. The entire machinery of "convex DP with breakpoint tracking" compresses to: push twice, pop once, accumulate cost.
The Final Boss: JOISC 2018 — Safety
For the ambitious: JOISC 2018 Safety combines slope trick with a two-queue architecture and lazy shifting.
The problem requires two priority queues (left slopes, right slopes) and global offset operations (shift all breakpoints by a constant) done lazily. The lazy shift avoids \(O(n)\) updates when the function translates.
This is the most technically demanding slope trick problem in competitive programming. If you can solve it, you've fully mastered this chapter. We won't cover the full solution here, but knowing it's "just" slope trick with bookkeeping should give you confidence that the framework scales.
Try It
Exercise 1 (predict first): Array \(a = [3, 1, 2, 4]\). Compute \(c_i = a_i - i\) by hand. Before running the algorithm, predict: does the first pop increase cost or not? Why?
Now trace push-twice-pop-once on your \(c\) values. Fill in this table:
| \(i\) | \(c_i\) | Push | Heap after push | Pop \(t\) | cost += | Total cost |
|---|---|---|---|---|---|---|
| 0 | ? | |||||
| 1 | ? | |||||
| 2 | ? | |||||
| 3 | ? |
Verify by finding the optimal non-decreasing \(d\) sequence and computing the L1 cost by hand.
Exercise 2 (the happy path): Array \(c = [1, 3, 5, 7]\) — already non-decreasing. Trace the algorithm. What gets popped each time? What's the total cost? Why does slope trick "know" no work is needed?
Challenge: Can slope trick handle L2 cost \((\sum (a_i - b_i)^2)\) instead of L1? The convexity still holds, but think about what changes. (Hint: the breakpoints are no longer sufficient — you need a different representation. This is why L1 is the natural home for slope trick.)
Problems
| Problem | Link | Difficulty |
|---|---|---|
| CF713C — Sonya and Problem Without a Legend | codeforces.com/problemset/problem/713/C | 2000 |
| CF1534G — A New Problem Every Day | codeforces.com/problemset/problem/1534/G | 2900 |
| JOISC 2018 — Safety | oj.uz/problem/view/JOI18_safety | Very Hard |