Iterative DFS
Why Go Iterative?
Recursive DFS is clean. It maps directly to how trees work. So why would you ever replace it with a loop and an explicit stack?
Three reasons:
- Stack overflow. A tree with \(10^5\) nodes in a straight line (a skewed tree) makes \(10^5\) recursive calls. Many systems cap the call stack at \(10^4\) frames. Your program crashes.
- Pause and resume. Iterators, coroutines, "give me the next element" patterns — recursion can't pause mid-execution and hand control back to the caller. An explicit stack can.
- Interview expectations. You'll be asked to write iterative traversals. Not because they're better, but because they test whether you truly understand what the recursion is doing.
The core insight is straightforward:
The explicit stack variable does the exact same job as the call stack. Every recursive call becomes a push. Every return becomes a pop.
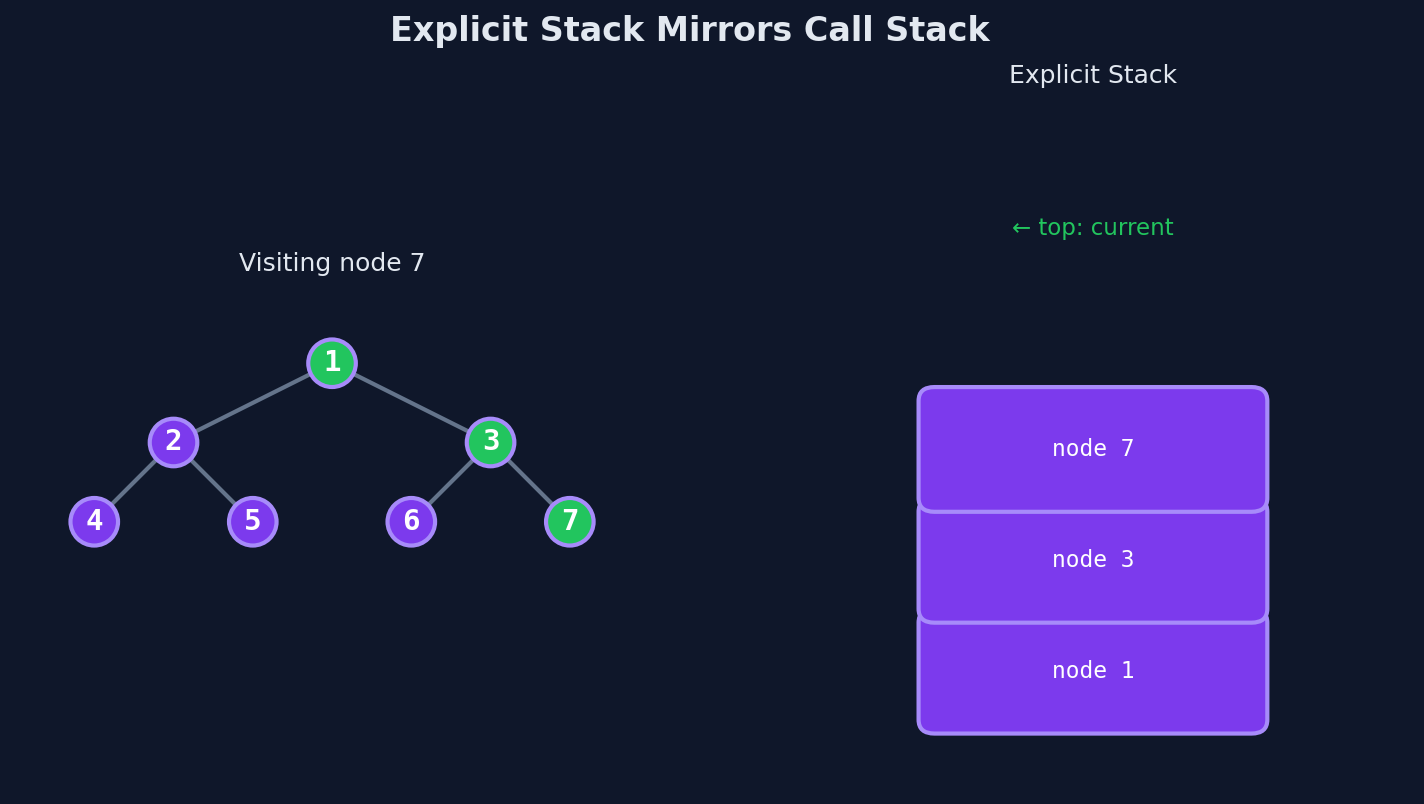
The Tree
Same tree as Lesson 1:
Iterative Preorder
Preorder is the simplest to convert because you process the node immediately — no waiting for children to finish.
The algorithm: push the root. While the stack isn't empty, pop a node, process it, push its right child, then push its left child.
Why right before left? Because a stack is LIFO. You want the left child processed first, so it needs to be on top. Push right first so left ends up above it.
vector<int> iterativePreorder(Node* root) {
vector<int> result;
if (!root) return result;
stack<Node*> nodeStack;
nodeStack.push(root);
while (!nodeStack.empty()) {
Node* current = nodeStack.top();
nodeStack.pop();
result.push_back(current->value);
if (current->right) nodeStack.push(current->right);
if (current->left) nodeStack.push(current->left);
}
return result;
}
Preorder Trace
| Step | Pop | Process | Push Right | Push Left | Stack (top→bottom) | Result |
|---|---|---|---|---|---|---|
| 0 | — | — | — | — | [1] | [] |
| 1 | 1 | 1 | 3 | 2 | [2, 3] | [1] |
| 2 | 2 | 2 | 5 | 4 | [4, 5, 3] | [1, 2] |
| 3 | 4 | 4 | — | — | [5, 3] | [1, 2, 4] |
| 4 | 5 | 5 | — | — | [3] | [1, 2, 4, 5] |
| 5 | 3 | 3 | 7 | 6 | [6, 7] | [1, 2, 4, 5, 3] |
| 6 | 6 | 6 | — | — | [7] | [1, 2, 4, 5, 3, 6] |
| 7 | 7 | 7 | — | — | [] | [1, 2, 4, 5, 3, 6, 7] |
Result: [1, 2, 4, 5, 3, 6, 7] — matches recursive preorder exactly.
Iterative Inorder
Inorder is trickier. You can't process a node when you first see it — you need to go left first. But you also can't just push left and forget, because after going all the way left and processing the leftmost node, you need to come back up and go right.
The pattern uses a current pointer alongside the stack:
- Start with
current = root. - Go left as far as you can, pushing each node onto the stack.
- When you hit
nullptr, pop from the stack — that's the next node to process. - After processing, set
current = node->rightand repeat.
The loop continues as long as current is non-null OR the stack is non-empty.
vector<int> iterativeInorder(Node* root) {
vector<int> result;
stack<Node*> nodeStack;
Node* current = root;
while (current || !nodeStack.empty()) {
while (current) {
nodeStack.push(current);
current = current->left;
}
current = nodeStack.top();
nodeStack.pop();
result.push_back(current->value);
current = current->right;
}
return result;
}
Inorder Trace
| Step | Action | current | Stack (top→bottom) | Result |
|---|---|---|---|---|
| 0 | Start | 1 | [] | [] |
| 1 | Push 1, go left | 2 | [1] | [] |
| 2 | Push 2, go left | 4 | [2, 1] | [] |
| 3 | Push 4, go left | nullptr | [4, 2, 1] | [] |
| 4 | Pop 4, process, go right | nullptr | [2, 1] | [4] |
| 5 | Pop 2, process, go right | 5 | [1] | [4, 2] |
| 6 | Push 5, go left | nullptr | [5, 1] | [4, 2] |
| 7 | Pop 5, process, go right | nullptr | [1] | [4, 2, 5] |
| 8 | Pop 1, process, go right | 3 | [] | [4, 2, 5, 1] |
| 9 | Push 3, go left | 6 | [3] | [4, 2, 5, 1] |
| 10 | Push 6, go left | nullptr | [6, 3] | [4, 2, 5, 1] |
| 11 | Pop 6, process, go right | nullptr | [3] | [4, 2, 5, 1, 6] |
| 12 | Pop 3, process, go right | 7 | [] | [4, 2, 5, 1, 6, 3] |
| 13 | Push 7, go left | nullptr | [7] | [4, 2, 5, 1, 6, 3] |
| 14 | Pop 7, process, go right | nullptr | [] | [4, 2, 5, 1, 6, 3, 7] |
Result: [4, 2, 5, 1, 6, 3, 7] — matches recursive inorder.
The inner
while (current)loop replaces the recursive "go left" call. The outer loop replaces the "return from recursion and go right" call.
Iterative Postorder: Two-Stack Method
Postorder is the hardest to do iteratively because you process a node last — after both children. You can't just pop and process.
The two-stack method is the easiest to understand. The idea: preorder visits nodes in Root-Left-Right order. If you flip the child push order, you get Root-Right-Left. Now reverse that entire sequence and you get Left-Right-Root — which is postorder.
Instead of reversing at the end, use a second stack to collect nodes in reverse.
vector<int> postorderTwoStacks(Node* root) {
vector<int> result;
if (!root) return result;
stack<Node*> firstStack;
stack<Node*> secondStack;
firstStack.push(root);
while (!firstStack.empty()) {
Node* current = firstStack.top();
firstStack.pop();
secondStack.push(current);
if (current->left) firstStack.push(current->left);
if (current->right) firstStack.push(current->right);
}
while (!secondStack.empty()) {
result.push_back(secondStack.top()->value);
secondStack.pop();
}
return result;
}
Notice: in the first stack loop, we push left before right (opposite of preorder). This gives us Root-Right-Left on the second stack. Popping the second stack reverses it to Left-Right-Root.
Two-Stack Trace
| Step | Pop from S1 | Push to S2 | Push to S1 (L, R) | S1 (top→bottom) | S2 (top→bottom) |
|---|---|---|---|---|---|
| 0 | — | — | — | [1] | [] |
| 1 | 1 | 1 | 2, 3 | [3, 2] | [1] |
| 2 | 3 | 3 | 6, 7 | [7, 6, 2] | [3, 1] |
| 3 | 7 | 7 | — | [6, 2] | [7, 3, 1] |
| 4 | 6 | 6 | — | [2] | [6, 7, 3, 1] |
| 5 | 2 | 2 | 4, 5 | [5, 4] | [2, 6, 7, 3, 1] |
| 6 | 5 | 5 | — | [4] | [5, 2, 6, 7, 3, 1] |
| 7 | 4 | 4 | — | [] | [4, 5, 2, 6, 7, 3, 1] |
Pop S2: [4, 5, 2, 6, 7, 3, 1] — matches recursive postorder.
Iterative Postorder: One-Stack Method
The two-stack method uses \(O(n)\) extra space for the second stack. You can do it with one stack, but the logic is more subtle.
The key: you pop a node only when its right child has already been processed (or doesn't exist). You track the lastVisited node to know whether you're coming back from the right child.
vector<int> postorderOneStack(Node* root) {
vector<int> result;
stack<Node*> nodeStack;
Node* current = root;
Node* lastVisited = nullptr;
while (current || !nodeStack.empty()) {
while (current) {
nodeStack.push(current);
current = current->left;
}
Node* topNode = nodeStack.top();
if (topNode->right && topNode->right != lastVisited) {
current = topNode->right;
} else {
result.push_back(topNode->value);
lastVisited = topNode;
nodeStack.pop();
}
}
return result;
}
The logic at each step: look at the stack's top. If it has a right child you haven't visited yet, go right. Otherwise, process it and pop.
One-Stack Trace
| Step | Action | topNode | lastVisited | Stack (top→bottom) | Result |
|---|---|---|---|---|---|
| 0 | Push 1→2→4, go left to nullptr | — | nullptr | [4, 2, 1] | [] |
| 1 | Top=4, no right child → process 4 | 4 | 4 | [2, 1] | [4] |
| 2 | Top=2, right=5, 5 != lastVisited → go right | 2 | 4 | [2, 1] | [4] |
| 3 | Push 5, go left to nullptr | — | 4 | [5, 2, 1] | [4] |
| 4 | Top=5, no right child → process 5 | 5 | 5 | [2, 1] | [4, 5] |
| 5 | Top=2, right=5, 5 == lastVisited → process 2 | 2 | 2 | [1] | [4, 5, 2] |
| 6 | Top=1, right=3, 3 != lastVisited → go right | 1 | 2 | [1] | [4, 5, 2] |
| 7 | Push 3→6, go left to nullptr | — | 2 | [6, 3, 1] | [4, 5, 2] |
| 8 | Top=6, no right child → process 6 | 6 | 6 | [3, 1] | [4, 5, 2, 6] |
| 9 | Top=3, right=7, 7 != lastVisited → go right | 3 | 6 | [3, 1] | [4, 5, 2, 6] |
| 10 | Push 7, go left to nullptr | — | 6 | [7, 3, 1] | [4, 5, 2, 6] |
| 11 | Top=7, no right child → process 7 | 7 | 7 | [3, 1] | [4, 5, 2, 6, 7] |
| 12 | Top=3, right=7, 7 == lastVisited → process 3 | 3 | 3 | [1] | [4, 5, 2, 6, 7, 3] |
| 13 | Top=1, right=3, 3 == lastVisited → process 1 | 1 | 1 | [] | [4, 5, 2, 6, 7, 3, 1] |
Result: [4, 5, 2, 6, 7, 3, 1] — correct.
The
lastVisitedpointer tells you whether you're returning from the left subtree (go right next) or from the right subtree (process and pop). It replaces the information that the call stack tracks implicitly.
When to Use Iterative Over Recursive
| Situation | Use |
|---|---|
| Standard tree problem, tree fits in memory | Recursive — cleaner, less error-prone |
| Tree could be extremely deep (linked-list shape) | Iterative — avoids stack overflow |
| Need to produce elements one at a time (iterator) | Iterative — can pause between elements |
| Need to interleave traversals or do two-pointer on a BST | Iterative — independent stack control |
| Interview asks "do it without recursion" | Iterative — obviously |
The recursive and iterative versions produce identical output. The iterative version just makes the call stack explicit, giving you manual control over when things happen.
Try It
The starter code has an iterativeInorder function with a TODO. Fill it in and verify:
Predict before running: What does the stack contain right before the first node is processed? Trace it: push 1, go left, push 2, go left, push 4, go left, hit nullptr. Stack = [4, 2, 1]. Pop 4 and process it. So the stack was [4, 2, 1] — the path from root to the leftmost node.
Challenge: Implement iterative preorder, then modify it to get postorder without using a second stack. (Hint: the one-stack method above is one approach. Can you find another using a lastVisited variable from the start?)
Challenge 2: Write an iterative inorder traversal that finds the \(k\)-th smallest element in a BST. Stop early — don't traverse the whole tree.
Edge Cases to Watch For
- Iterative preorder push order: Push RIGHT before LEFT. If you reverse this, you get a right-first DFS, which produces the wrong preorder. This is the most common bug in iterative preorder implementations.
- Iterative postorder with lastVisited: If you forget to update
lastVisitedafter processing a node, you will loop infinitely — the stack top will repeatedly check its right child without ever popping.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| LC 144 — Binary Tree Preorder Traversal | leetcode.com/problems/binary-tree-preorder-traversal | Easy |
| LC 94 — Binary Tree Inorder Traversal | leetcode.com/problems/binary-tree-inorder-traversal | Easy |
| LC 145 — Binary Tree Postorder Traversal | leetcode.com/problems/binary-tree-postorder-traversal | Easy |
| LC 230 — Kth Smallest Element in a BST | leetcode.com/problems/kth-smallest-element-in-a-bst | Medium |
| LC 173 — Binary Search Tree Iterator | leetcode.com/problems/binary-search-tree-iterator | Medium |