Tree Isomorphism via Hashing
When Are Two Trees "The Same"?
You have two binary trees. They might have different node values, different memory addresses, different orderings. But structurally — ignoring the labels — they have the same shape. How do you detect this efficiently?
This is the tree isomorphism problem, and the answer is hashing: assign each tree a canonical string (or hash value) based on its structure, then compare.
Rooted Tree Isomorphism: The AHU Algorithm
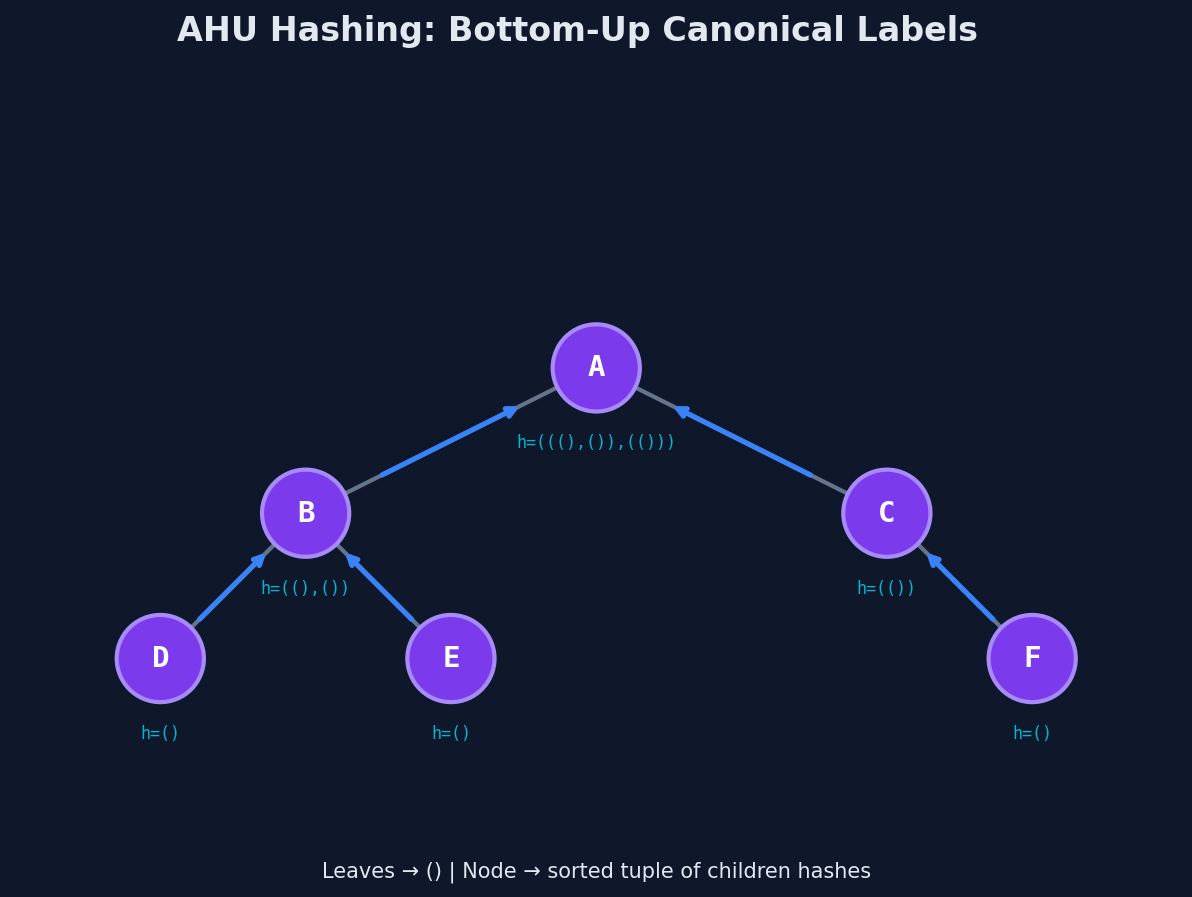
For rooted trees, the approach is clean. Hash bottom-up. Every subtree gets a canonical label based on the labels of its children.
Algorithm (AHU — Aho, Hopcroft, Ullman):
- Every
nullptr(empty subtree) gets the label"()". - For an internal node, collect the labels of all its children, sort them, concatenate, and wrap in parentheses.
- Two rooted trees are isomorphic if and only if their root labels match.
The sorting step is what makes this work. It erases the difference between "left child has shape X, right child has shape Y" and "left child has shape Y, right child has shape X." Structure is captured; ordering is discarded.
Trace: Hashing a 7-Node Tree
We hash bottom-up, starting from the leaves.
| Node | Children labels | Sorted | Hash |
|---|---|---|---|
| 7 | (), () |
(), () |
(()()) |
| 4 | hash(7), () → (()()), () |
(), (()()) |
(()(()())) |
| 5 | (), () |
(), () |
(()()) |
| 6 | (), () |
(), () |
(()()) |
| 2 | hash(4), hash(5) → (()(()())), (()()) |
(()()), (()(()())) |
((()())(()(()())) |
| 3 | (), hash(6) → (), (()()) |
(), (()()) |
(()(()())) |
| 1 | hash(2), hash(3) | (sorted) | full root hash |
Two trees are isomorphic iff their root hashes are identical strings.
The canonical form is a parenthesization of the tree's structure. Each pair of parentheses represents one node. The nesting captures the parent-child relationship. Sorting makes it order-independent.
Unrooted Tree Isomorphism
For unrooted trees, you can't just pick any root — different root choices give different hashes for the same tree.
The fix: root at the centroid.
Centroid of a tree: A node whose removal leaves no component larger than \(n/2\). Every tree has either 1 or 2 centroids.
- 1 centroid: Root there, hash with AHU, compare.
- 2 centroids: They're always adjacent. Try both as root. Two unrooted trees are isomorphic iff the hash from either centroid of tree A matches the hash from either centroid of tree B.
Finding the centroid: Compute subtree sizes with one DFS. Then find the node where the largest component (considering both subtree children and the "parent component" of size \(n - \text{subtreeSize}\)) is at most \(n/2\).
LC 652: Find Duplicate Subtrees
Problem: Given a binary tree, return the root nodes of all duplicate subtrees. A duplicate subtree is one that appears (structurally identical with same values) at two or more places in the tree.
This is a direct application of subtree hashing — but here we include node values in the hash, not just structure.
Approach: For each node, compute a hash string that encodes the subtree's structure AND values. Store each hash in a map counting occurrences. When a hash reaches count 2, record that subtree.
vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
unordered_map<string, int> hashCount;
vector<TreeNode*> duplicates;
function<string(TreeNode*)> serialize = [&](TreeNode* node) -> string {
if (!node) return "#";
string subtreeHash = to_string(node->val) + ","
+ serialize(node->left) + ","
+ serialize(node->right);
hashCount[subtreeHash]++;
if (hashCount[subtreeHash] == 2) {
duplicates.push_back(node);
}
return subtreeHash;
};
serialize(root);
return duplicates;
}
Complexity: \(O(n^2)\) in the worst case due to string concatenation. You can reduce this to \(O(n)\) with integer hashing.
Practical Optimization: Polynomial Hashing
String comparison is \(O(n)\) in the worst case, which makes the AHU approach \(O(n^2)\) overall. For competitive programming, replace strings with polynomial hash values:
- Maintain a global map from canonical string → integer ID.
- When you first see a new canonical form, assign it the next integer.
- Each node's hash becomes a tuple of integers (its children's IDs), which you hash to a single integer using polynomial hashing.
This gives \(O(n)\) total time with high probability (hash collisions are rare with a good modulus).
map<vector<int>, int> canonicalToId;
int nextId = 0;
int hashSubtree(TreeNode* node) {
if (!node) return -1;
int leftId = hashSubtree(node->left);
int rightId = hashSubtree(node->right);
vector<int> childIds = {leftId, rightId};
sort(childIds.begin(), childIds.end());
if (canonicalToId.find(childIds) == canonicalToId.end()) {
canonicalToId[childIds] = nextId++;
}
return canonicalToId[childIds];
}
Two subtrees are structurally isomorphic iff they get the same integer ID. No string operations, no quadratic blowup.
The Full Picture
| Scenario | Method | Time |
|---|---|---|
| Rooted tree isomorphism | AHU hash at root | \(O(n)\) with int hashing |
| Unrooted tree isomorphism | Find centroid, root there, AHU | \(O(n)\) |
| Find duplicate subtrees (with values) | Hash each subtree, count in map | \(O(n)\) with int hashing |
| Check if tree B is a subtree of tree A | Hash all subtrees of A, check B's root hash | \(O(n + m)\) |
Tree hashing reduces structural comparison to integer comparison. Once you have the hash, isomorphism is \(O(1)\).
Try It
Fill in hashSubtree in the starter code to return the canonical string form.
Predict before running: Two trees — one is a mirror image of the other (left and right children swapped at every node). Do they get the same AHU hash? Yes — the sorting step makes them identical.
Challenge: Given two unrooted trees as edge lists, write a function to check if they're isomorphic. You'll need: (1) find the centroid of each, (2) root at centroid, (3) hash with AHU, (4) compare.
Edge Cases to Watch For
- Unrooted tree with 2 centroids: When the tree has 2 centroids (always adjacent), you must try both as root and compare hashes. If you only root at one, two isomorphic trees may produce different hashes depending on which centroid is chosen — giving a false negative.
- Hash collisions with polynomial hashing: Rare but possible, and undetectable without verification. Use double hashing (two different moduli) for contest safety. A single collision gives a false positive on non-isomorphic trees.
- String-based canonical form gives \(O(n^2)\): Long canonical strings cause \(O(n)\) per comparison. Use integer ID mapping (assign each unique child-hash multiset a new integer) for \(O(n)\) total.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| LC 652 — Find Duplicate Subtrees | leetcode.com/problems/find-duplicate-subtrees | Medium |
| LC 572 — Subtree of Another Tree | leetcode.com/problems/subtree-of-another-tree | Easy |
| CF 1800G — Symmetree | codeforces.com/contest/1800/problem/G | Hard |