BFS on Graphs
BFS Is a Shortest Path Algorithm
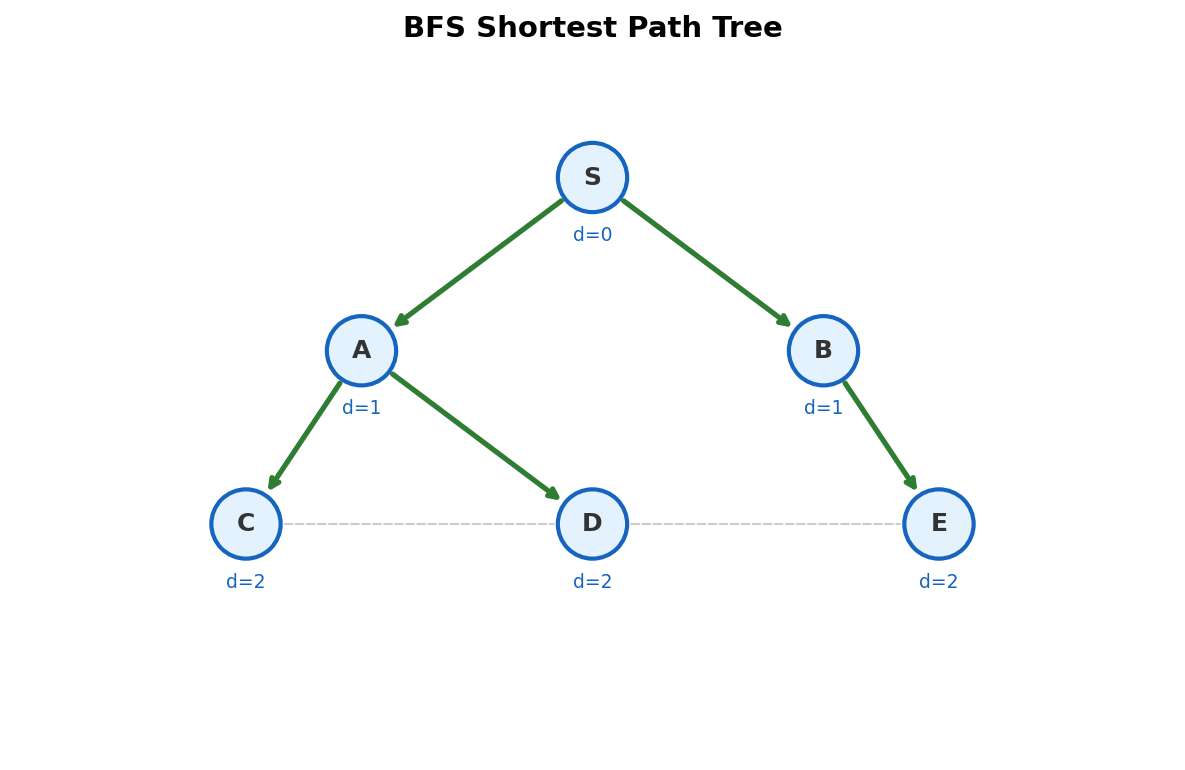
On trees, BFS is a nice way to get level-order output. On graphs, BFS solves a fundamentally harder problem: shortest paths in unweighted graphs.
This isn't a side effect. It's the defining property. BFS visits all nodes at distance 1 before any node at distance 2, all at distance 2 before any at distance 3, and so on. The first time BFS reaches a node, it found the shortest path to that node. Always.
If you only remember one thing from this lesson: BFS on an unweighted graph gives shortest paths. DFS does not.
Why BFS Gives Shortest Paths
The argument is simple. BFS uses a FIFO queue. When you process a node at distance \(d\), you enqueue its unvisited neighbors at distance \(d+1\). Those go to the back of the queue. All other distance-\(d\) nodes are still at the front. So you finish all distance-\(d\) nodes before touching any distance-\((d+1)\) node.
By induction: the first time you reach any node, you reached it with the minimum number of edges.
💡 Key insight. DFS can find a path, but it might find a long winding path through the entire graph. BFS always finds the shortest one. This is why "shortest path in unweighted graph" is always BFS.
The BFS Template
int dist[200005];
bool visited[200005];
int parent[200005];
vector<int> adj[200005];
void bfs(int start) {
memset(dist, -1, sizeof(dist));
memset(parent, -1, sizeof(parent));
queue<int> q;
q.push(start);
dist[start] = 0;
visited[start] = true;
while (!q.empty()) {
int u = q.front();
q.pop();
for (int v : adj[u]) {
if (!visited[v]) {
visited[v] = true;
dist[v] = dist[u] + 1;
parent[v] = u;
q.push(v);
}
}
}
}
Three arrays:
visited[]-- prevents revisiting nodes (same role as in DFS).dist[]-- stores the shortest distance fromstartto each node.parent[]-- stores how we reached each node (for path reconstruction).
Mark Visited on Push, Not on Pop
This is the single most common BFS bug. It matters.
Wrong -- marking on pop:
while (!q.empty()) {
int u = q.front();
q.pop();
visited[u] = true; // TOO LATE
for (int v : adj[u]) {
if (!visited[v]) {
q.push(v);
}
}
}
Why it breaks: Suppose nodes A and B are both in the queue, and both have neighbor C. A is popped first, pushes C. B is popped next, C isn't marked visited yet (we mark on pop, and C hasn't been popped), so B pushes C again. Now C is in the queue twice.
In the best case, you waste time processing C twice. In the worst case -- on dense graphs -- the queue explodes to \(O(m)\) size instead of \(O(n)\).
Correct -- marking on push:
while (!q.empty()) {
int u = q.front();
q.pop();
for (int v : adj[u]) {
if (!visited[v]) {
visited[v] = true; // mark IMMEDIATELY
q.push(v);
}
}
}
The moment you decide to push a node, mark it visited. This guarantees each node enters the queue exactly once.
⚠ Gotcha. Mark visited when pushing, not when popping. This is the #1 BFS bug. It causes TLE on large graphs because nodes get pushed into the queue multiple times.
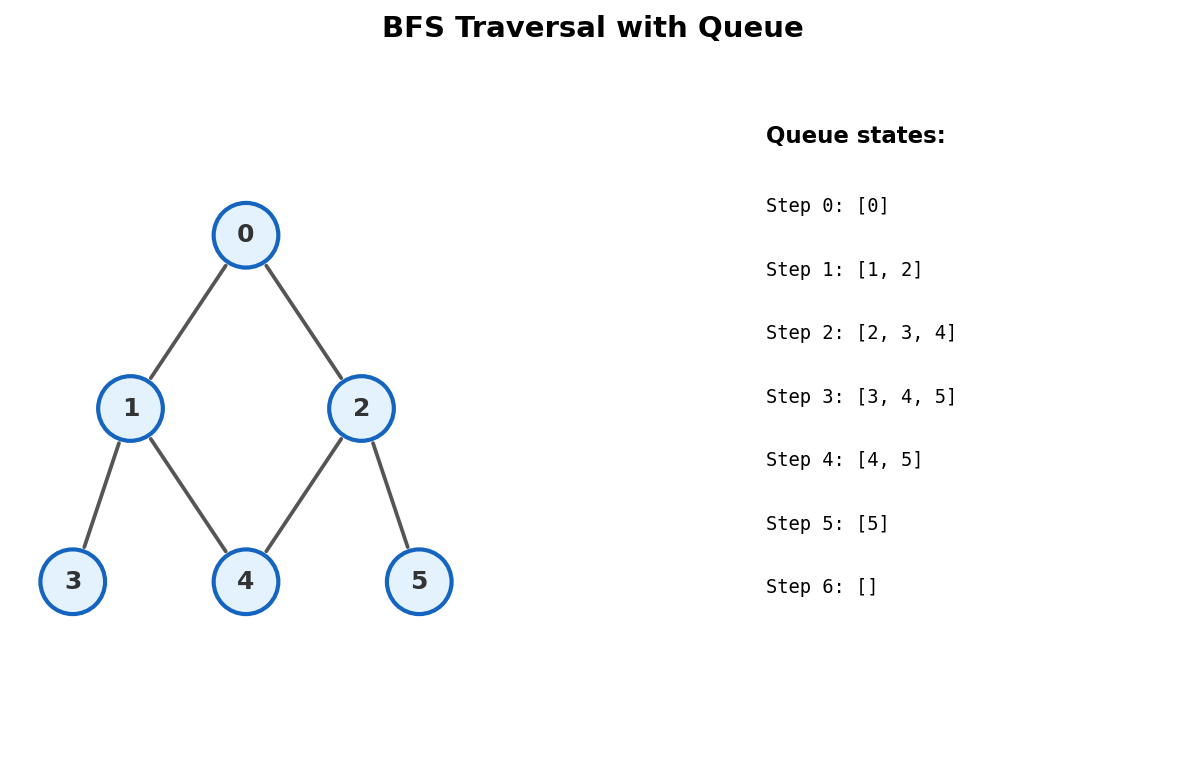
BFS Trace
Consider this undirected graph:
Adjacency list:
- 1: [2, 3]
- 2: [1, 4, 5]
- 3: [1, 4]
- 4: [2, 3, 6]
- 5: [2]
- 6: [4]
BFS from node 1:
| Step | Pop | Queue After Pop | Process Neighbors | Push | Queue After Push | dist[] update |
|---|---|---|---|---|---|---|
| 0 | -- | -- | Init | 1 | [1] | dist[1]=0 |
| 1 | 1 | [] | 2 (unvisited), 3 (unvisited) | 2, 3 | [2, 3] | dist[2]=1, dist[3]=1 |
| 2 | 2 | [3] | 1 (visited), 4 (unvisited), 5 (unvisited) | 4, 5 | [3, 4, 5] | dist[4]=2, dist[5]=2 |
| 3 | 3 | [4, 5] | 1 (visited), 4 (visited) | -- | [4, 5] | -- |
| 4 | 4 | [5] | 2 (visited), 3 (visited), 6 (unvisited) | 6 | [5, 6] | dist[6]=3 |
| 5 | 5 | [6] | 2 (visited) | -- | [6] | -- |
| 6 | 6 | [] | 4 (visited) | -- | [] | -- |
Final distances from node 1:
| Node | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| dist | 0 | 1 | 1 | 2 | 2 | 3 |
Notice the layered pattern: all distance-1 nodes (2, 3) are processed before any distance-2 node (4, 5). All distance-2 nodes are processed before the distance-3 node (6). This is the shortest-path guarantee in action.
Path Reconstruction
BFS gives you shortest distances, but many problems ask for the actual path. The parent[] array handles this.
During BFS, when you discover node v from node u, set parent[v] = u. After BFS finishes, backtrack from the target to the source using parent[]:
vector<int> reconstructPath(int start, int target) {
if (dist[target] == -1) return {}; // unreachable
vector<int> path;
for (int v = target; v != -1; v = parent[v]) {
path.push_back(v);
}
reverse(path.begin(), path.end());
return path;
}
Path Reconstruction Trace
From the BFS above, find the path from 1 to 6.
Parent array after BFS:
| Node | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| parent | -1 | 1 | 1 | 2 | 2 | 4 |
Backtrack from 6:
| Step | Current | parent[current] | Path So Far |
|---|---|---|---|
| 1 | 6 | 4 | [6] |
| 2 | 4 | 2 | [6, 4] |
| 3 | 2 | 1 | [6, 4, 2] |
| 4 | 1 | -1 (stop) | [6, 4, 2, 1] |
After reversing: 1 -> 2 -> 4 -> 6 (length 3, matching dist[6] = 3).
BFS vs DFS: When to Use Which
This decision comes up on nearly every graph problem. Here's the rule:
| Situation | Use | Why |
|---|---|---|
| Shortest path (unweighted) | BFS | BFS explores by distance; first arrival = shortest |
| Cycle detection | DFS | Back edges in DFS tree = cycles |
| Connected components | Either | Both explore full components; DFS is simpler to code |
| Topological sort | DFS | Post-order gives reverse topo order (Chapter 3) |
| Path existence (any path) | Either | Both find a path if one exists |
| Level/layer structure | BFS | BFS naturally gives level boundaries |
| Reachability from one source | Either | Same time complexity |
| Shortest path (weighted) | Neither | Use Dijkstra or Bellman-Ford (Chapter 5) |
💡 Key insight. The default choice for "can I reach X from Y" is DFS (simpler code, less memory). The moment the problem says "shortest," "minimum edges," or "fewest steps," switch to BFS.
Complexity
For a graph with \(n\) nodes and \(m\) edges:
- Time: \(O(n + m)\). Each node is pushed and popped exactly once (\(O(n)\)). Each edge is examined exactly twice in an undirected graph (\(O(m)\)).
- Space: \(O(n)\) for the queue, visited array, dist array, and parent array.
This is the same complexity as DFS. The difference is not speed -- it's what each algorithm computes. DFS computes traversal order and discovers structure (cycles, components). BFS computes distances.
Try It
The starter code has a BFS skeleton with TODOs for three things: marking visited and setting distance/parent inside the loop, and path reconstruction at the end. Fill them in.
Test case 1 -- path exists:
Note: the shortest path from 1 to 5 has length 2 (either 1-4-5 or 1-2-3... wait, 1-2-3-5 is length 3). So BFS finds 1-4-5.
Test case 2 -- no path:
Predict before running: In test case 1, which node does BFS discover first -- node 3 or node 4? Both are distance 1 from node 1... wrong. Node 2 is distance 1, node 4 is distance 1. Node 3 is distance 2. So nodes 2 and 4 are discovered first (both at distance 1), then nodes 3 and 5 (both at distance 2).
Challenge: What if you want ALL shortest paths from 1 to n, not just one? How would you modify the parent array? (Hint: instead of one parent per node, store a list of parents -- all nodes u where dist[u] + 1 == dist[v].)
Challenge 2: Can BFS detect cycles? Yes, but it's unusual. If during BFS you encounter a visited neighbor that isn't the parent, there's a cycle. Why is DFS preferred for cycle detection despite this? (Hint: BFS finds the cycle exists but reconstructing the actual cycle path is harder than with DFS.)
Problems
| Problem | Link | Difficulty |
|---|---|---|
| CSES Message Route | cses.fi/problemset/task/1667 | Easy |
| LC 1091 — Shortest Path in Binary Matrix | leetcode.com/problems/shortest-path-in-binary-matrix | Medium |
| LC 127 — Word Ladder | leetcode.com/problems/word-ladder | Hard |