Beyond Lines — Li Chao Tree
Where the Simple CHT Breaks
The Convex Hull Trick from lessons 1 and 2 is fast and elegant, but it comes with strings attached. Two big ones:
-
Slopes must be sorted. Lines must arrive in monotonic slope order (decreasing for min-envelope). If they don't, you can't just push to one end of the deque.
-
It only handles lines. Linear functions. If your candidates are parabolas or exponentials, the entire geometric argument falls apart.
Both limitations show up in real problems. This lesson covers what to do when you hit them.
The Sorting Problem
In many DP problems, the slopes aren't naturally sorted. Maybe a[j] depends on the input in some arbitrary order, and you can't control the sequence of slopes.
With unsorted slopes, the deque trick doesn't work. You can't just push to the back and pop from the back, because a new line with a steeper slope might need to be inserted in the MIDDLE of the envelope. The stack invariant — intersection x-coordinates strictly increasing — still needs to hold, but maintaining it with a deque requires the slopes to arrive in order.
One option: sort the lines by slope before inserting. But in a DP setting, you're computing dp[j] as you go, so you don't know the intercept until you've processed j. You can't sort them ahead of time.
You could use a balanced BST or a set of lines and maintain the envelope dynamically. That works but it's complex to implement and debug under time pressure.
There's a cleaner solution: abandon the deque entirely and use a different data structure. One that's built for arbitrary insertions.
The Li Chao Tree: Core Idea
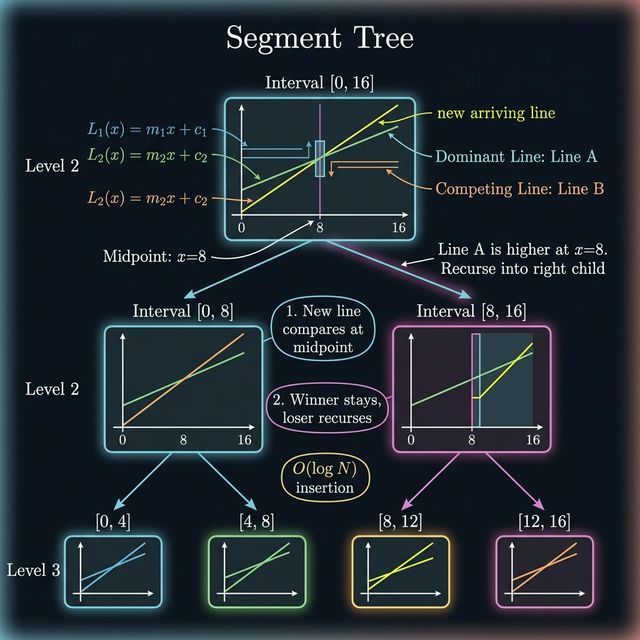
A Li Chao Tree is a segment tree over the x-axis. Instead of storing values at leaves, each node stores the line that's "dominant" (gives the minimum y) over that node's interval.
The query range is some integer interval, say [0, MAX_X]. The root covers the entire range. Left child covers the left half, right child covers the right half. Standard segment tree structure.
Each node stores one line. The invariant is: the stored line is the one that wins at the midpoint of the node's interval. But other lines might win in sub-intervals — those are pushed to children.
Insertion: The Winner-Stays Logic
Here's how you insert a new line into the tree. This is the part that makes the Li Chao Tree tick.
You're at a node covering interval [lo, hi] with midpoint mid. The node currently stores line old. You want to insert line nw.
-
Compare
oldandnwat the midpoint. The one with the smaller y at mid is the winner. It stays in this node. -
The loser at the midpoint might still win somewhere in [lo, hi]. Where? Well, since we're dealing with lines (which intersect at most once), the loser can only beat the winner on one side — either the left half or the right half.
-
To figure out which side: compare the two lines at
lo. If the loser wins atlobut loses atmid, it must beat the winner somewhere in the left half. If the loser loses atlotoo, then it can only win in the right half (if anywhere). -
Recurse into the relevant child with the loser.
Before we jump to C++, here's the pure logic in pseudocode. Get this right in your head first — the syntax is secondary.
INSERT(new_line, node, lo, hi):
mid = (lo + hi) / 2
stored = line currently in this node
winner_at_mid = whichever of (new_line, stored) gives smaller y at mid
loser_at_mid = the other one
put winner_at_mid in this node
if lo == hi: return // leaf, nowhere for the loser to go
// The loser lost at mid. Can it win anywhere else in [lo, hi]?
// Since lines cross at most once, it can only win on ONE side.
if loser wins at lo:
// loser beats winner on the left side → recurse left
INSERT(loser_at_mid, left_child, lo, mid)
else:
// loser might beat winner on the right side → recurse right
INSERT(loser_at_mid, right_child, mid+1, hi)
One insertion = one root-to-leaf walk = O(log MAX_X). No rotations, no rebalancing. Just compare, swap the winner in, push the loser down.
Now the C++ version — it's the same logic with types:
void addLine(Line nw, int v, int lo, int hi) {
int mid = (lo + hi) / 2;
bool leftBetter = nw.eval(lo) < tree[v].line.eval(lo);
bool midBetter = nw.eval(mid) < tree[v].line.eval(mid);
if (midBetter) swap(tree[v].line, nw);
// Now tree[v].line wins at mid. nw lost at mid.
if (lo == hi) return;
if (leftBetter != midBetter) {
// nw might win on the left half
addLine(nw, left_child, lo, mid);
} else {
// nw might win on the right half
addLine(nw, right_child, mid + 1, hi);
}
}
Each insertion walks from root to leaf: O(log MAX_X). No rotations, no rebalancing. Just comparisons and swaps.
Query: Walk and Collect
To query at a specific x value, walk from root to leaf (following the path that contains x). At each node, evaluate the stored line at x. The answer is the minimum across all nodes on the path.
long long query(int x, int v, int lo, int hi) {
if (v == -1) return INF;
long long best = tree[v].line.eval(x);
int mid = (lo + hi) / 2;
if (x <= mid)
best = min(best, query(x, left_child, lo, mid));
else
best = min(best, query(x, right_child, mid + 1, hi));
return best;
}
Also O(log MAX_X). Simple.
Why This Works
The key insight: two lines intersect at most once. So if line A beats line B at the midpoint, B can only beat A on one contiguous side. By always keeping the midpoint winner in the node and pushing the loser to a child, you guarantee that the correct answer is always on the root-to-leaf path.
This is sometimes called the "segment tree of dominant lines." Each node's stored line is the best at the midpoint. Lines that were pushed to children are the best in their respective sub-intervals.
The Real Power: Non-Linear Functions
Here's where the Li Chao Tree goes beyond CHT. What if your candidates aren't lines but parabolas?
Consider a DP where the transition cost is quadratic:
Expanding: dp[i] = min(dp[j] + j^2 - 2ij + i^2). The i^2 term factors out, so you're really minimizing dp[j] + j^2 - 2j * i over j. Wait — that's actually still linear in i. You can use regular CHT here (slope = -2j, intercept = dp[j] + j^2).
But sometimes you genuinely get non-linear functions. Maybe the cost involves sqrt(i - j) or some other curve. Or maybe you have a set of parabolas f_j(x) = a_j * x^2 + b_j * x + c_j and need the lower envelope.
The simple CHT breaks because two parabolas can intersect twice. A line either wins on a suffix or doesn't — that's what makes the deque work. A parabola might win on an interval, lose in the middle, then win again. The "push to one end, pop from the other" logic doesn't apply.
The Li Chao Tree handles this as long as any two functions intersect at most once in the query range. Why? Because the insertion logic depends on this: the loser at the midpoint can only win on ONE side. If functions could intersect twice, the loser might win on both sides, and the insertion would need to recurse into both children. That breaks the O(log N) guarantee.
For functions with at most one intersection (which includes all lines, and many practical cases like f(x) = ax + b*sqrt(x)), the Li Chao Tree works out of the box. Just replace the eval function.
When Functions Intersect Multiple Times
What if two candidates CAN intersect more than once? For example, piecewise functions or weird non-convex curves?
Then you need to store each function along with its active interval: a (Function, [Left Bound, Right Bound]) pair. A new function eclipses an old one only if it's lower over the old one's ENTIRE active interval. Partial eclipses require splitting the interval.
This gets complex fast. In practice, the Li Chao Tree still handles most of these cases if you're careful about the intersection count. For truly arbitrary functions, you might need a kinetic segment tree or offline divide-and-conquer.
For competitive programming, you'll almost never need to go beyond the Li Chao Tree. The problems are designed so that the "at most one intersection" property holds.
The Decision Table
Here's when to use what. This is worth committing to memory.
| Condition | Technique | Time |
|---|---|---|
| Sorted slopes + sorted queries | Deque CHT (pointer) | O(N) |
| Sorted slopes + unsorted queries | Deque CHT + binary search | O(N log N) |
| Unsorted slopes | Li Chao Tree | O(N log MAX_X) |
| Non-linear (1 intersection) | Li Chao Tree | O(N log MAX_X) |
| Non-linear (multiple intersections) | Advanced / case-by-case | Varies |
The deque CHT is the fastest when it applies. The Li Chao Tree is the most general practical option. Know both.
A common gotcha: the Li Chao Tree's complexity depends on MAX_X, the range of query values. If x can be up to 10^9, that's a tree of depth 30 — still fast. But if x can be up to 10^18, you'll want to use dynamic node creation (allocate children only when needed) to avoid allocating a ridiculous number of nodes.
Deque CHT with Binary Search
There's a middle ground we should mention. If slopes are sorted but queries aren't, you can still build the envelope with the deque (same O(N) build step from lesson 1). Then for each query, binary search the envelope to find which segment the query x falls in.
The envelope is a sequence of lines with increasing intersection points. You're looking for the last line whose intersection with the next line is <= your query x. Standard binary search.
// After building the hull (deque of lines):
long long query(deque<Line>& hull, long long x) {
int lo = 0, hi = hull.size() - 1;
while (lo < hi) {
int mid = (lo + hi) / 2;
if (hull[mid].eval(x) <= hull[mid + 1].eval(x))
hi = mid;
else
lo = mid + 1;
}
return hull[lo].eval(x);
}
Build: O(N). Each query: O(log N). Total: O(N + Q log N). This is often faster than the Li Chao Tree when the number of lines is moderate and the x-range is huge.
Reflecting on the Journey
Take a step back. Look at how far the monotonic stack idea has traveled:
- Chapter 1: A stack of indices maintaining a decreasing value chain. Pop when disturbed.
- Chapter 2: A deque of indices with expiration. Sliding window. DP optimization.
- Chapter 3: Histogram bars, bounded by stack neighbors. Area and contribution.
- Chapter 4: Greedy construction with a pop budget. Lexicographic optimization.
- Chapter 5: The Cartesian Tree — the stack's one-pass build produces a tree encoding the array's structure.
- Chapter 6: The Convex Hull Trick — the stack now holds lines, and the pop condition is geometric.
The common thread: a sequence of candidates, processed in order, where old candidates get eliminated by new arrivals. The data structure maintains the "active" set. Pop when something is eclipsed. Push when something joins.
Whether the candidates are array elements, deque entries, histogram bars, or linear functions — the pattern is the same. The stack is the skeleton. The application changes the flesh.
Try It
The starter code has a Li Chao Tree skeleton. The addLine method is left blank — implement it using the winner-stays logic described above. The query method is already implemented.
Input format: Line 1: N Q (number of lines, number of queries) Next N lines: m_i c_i (slope and intercept — NOT necessarily sorted) Next Q lines: x_i (query points — NOT necessarily sorted)
Output: For each query, print the minimum y value across all lines at that x.
Example:
Lines: y = x + 8, y = 5x + 1, y = 3x + 4. (Note: slopes are NOT sorted.)
At x = 0: min(8, 1, 4) = 1. At x = 1: min(9, 6, 7) = 6. At x = 2: min(10, 11, 10) = 10. At x = 4: min(12, 21, 16) = 12. At x = 6: min(14, 31, 22) = 14.
Expected output:
After you get this working, try adding the lines in sorted order and verify you get the same answers. The Li Chao Tree doesn't care about insertion order — that's the whole point.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| CF 319C — Kalila and Dimna | codeforces.com/problemset/problem/319/C | Hard |
| CF 1083E — The Fair Nut and Rectangles | codeforces.com/problemset/problem/1083/E | Hard |
| CF 932F — Escape Through Leaf | codeforces.com/problemset/problem/932/F | Hard |