Cycle Detection
You keep applying a function to a value: \(x_0, f(x_0), f(f(x_0)), \ldots\) At some point the sequence must repeat -- there are only finitely many values. Floyd's algorithm detects where the cycle starts using nothing but two pointers. No hash set. No visited array. Constant extra memory.
The Setup
Given a function \(f\) and a starting value \(x_0\), the sequence \(x_0, x_1 = f(x_0), x_2 = f(x_1), \ldots\) eventually enters a cycle. Define:
- \(\mu\) = the index where the cycle starts (the tail length).
- \(\lambda\) = the cycle length.
So \(x_\mu = x_{\mu + \lambda}\), and \(\mu\) is the smallest such index.
The rho shape from Lesson 1 -- just viewed as a sequence instead of a graph.
Floyd's Tortoise and Hare
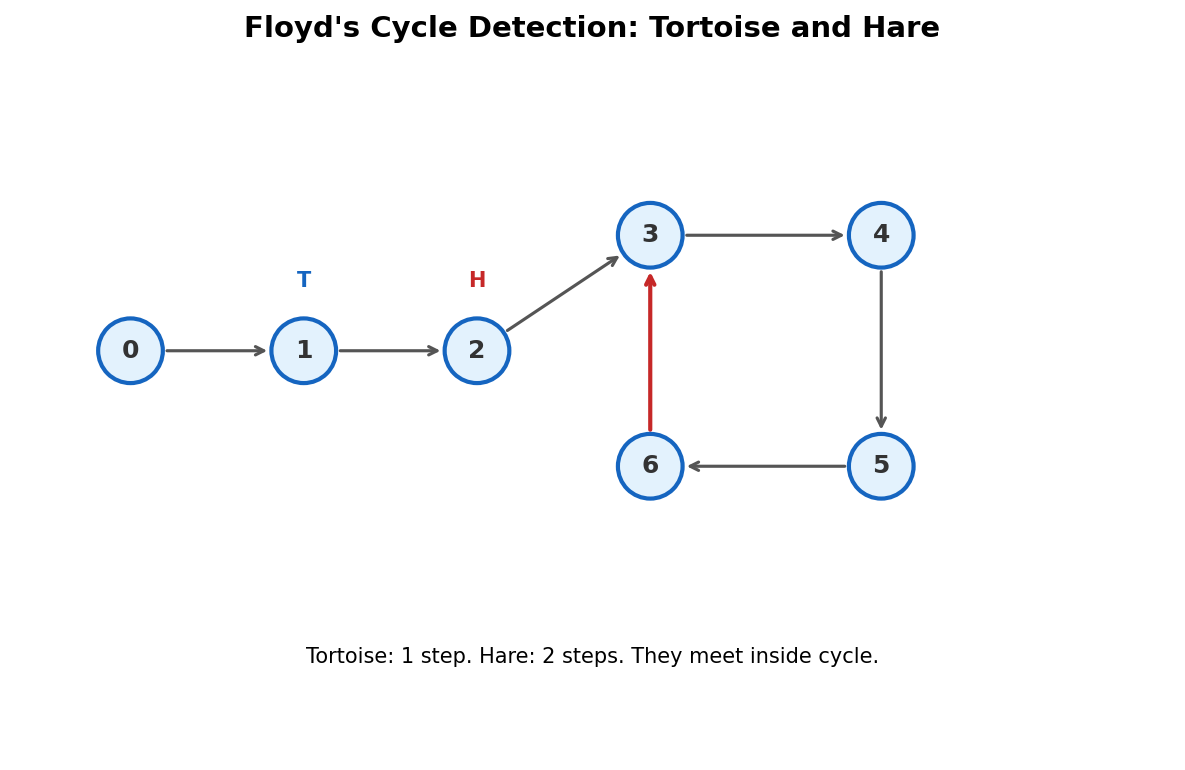
Phase 1: Find a meeting point inside the cycle.
Two pointers start at \(x_0\). The tortoise moves 1 step per iteration. The hare moves 2 steps. They must meet inside the cycle.
Why do they meet? Once both are inside the cycle, the hare gains 1 step per iteration on the tortoise. Since the cycle has length \(\lambda\), they meet after at most \(\lambda\) more iterations.
Phase 2: Find the cycle start.
Reset the tortoise to \(x_0\). Move both pointers 1 step at a time. They meet at \(x_\mu\), the cycle start.
Phase 3: Find the cycle length.
From the cycle start, advance one pointer until it returns.
Why Phase 2 Works
When the pointers first meet, the tortoise has taken \(t\) steps and the hare has taken \(2t\) steps. The difference \(t\) is a multiple of \(\lambda\) (they're at the same position in the cycle).
The tortoise is at position \(t\). It entered the cycle at position \(\mu\), so it's \(t - \mu\) steps into the cycle. Since \(t\) is a multiple of \(\lambda\), the tortoise is \(-\mu \pmod{\lambda}\) steps from the cycle start.
If we now move a pointer from \(x_0\) and another from the meeting point, both at speed 1, after \(\mu\) steps the first pointer reaches \(x_\mu\) (cycle start) and the second pointer has moved \(\mu\) steps forward in the cycle, landing at position \((-\mu + \mu) \pmod{\lambda} = 0\) -- also the cycle start.
Key insight. The math works out perfectly: after the meeting, both pointers are exactly \(\mu\) steps away from the cycle start, just measured from different starting points.
Trace
Function: \(f(x) = (x^2 + 1) \bmod 16\). Start: \(x_0 = 2\).
Sequence: 2, 5, 10, 5, 10, 5, 10, ... Tail: [2]. Cycle: [5, 10]. So \(\mu = 1\), \(\lambda = 2\).
Phase 1:
| Step | Tortoise (slow) | Hare (fast) | Meet? |
|---|---|---|---|
| Init | \(f(2) = 5\) | \(f(f(2)) = f(5) = 10\) | No |
| 1 | \(f(5) = 10\) | \(f(f(10)) = f(5) = 10\) | Yes |
Meeting point: 10.
Phase 2:
| Step | Tortoise (from \(x_0\)) | Hare (from meeting) | Meet? |
|---|---|---|---|
| Init | 2 | 10 | No |
| 1 | \(f(2) = 5\) | \(f(10) = 5\) | Yes |
Cycle start: 5. Correct (\(\mu = 1\)).
Phase 3: From 5: \(f(5) = 10\), \(f(10) = 5\). Length = 2.
Brent's Algorithm
Brent's is often faster in practice. The idea: move only the fast pointer, in rounds of powers of 2. After each round, teleport the slow pointer to the fast pointer's position.
int slow = x0, fast = f(x0);
int power = 1, len = 1;
while (slow != fast) {
if (power == len) {
slow = fast;
power *= 2;
len = 0;
}
fast = f(fast);
len++;
}
// len is now the cycle length
After finding \(\lambda\), find the cycle start: advance one pointer \(\lambda\) steps ahead, then move both until they meet.
slow = fast = x0;
for (int i = 0; i < len; i++) fast = f(fast);
while (slow != fast) {
slow = f(slow);
fast = f(fast);
}
int cycleStart = slow;
Key insight. Brent's calls \(f\) fewer times than Floyd's in practice. Floyd's evaluates \(f\) about \(3(\mu + \lambda)\) times. Brent's evaluates about \(2(\mu + \lambda)\) times. When \(f\) is expensive (hashing, modular arithmetic), this matters.
LC 287: Find the Duplicate Number
Problem. An array of \(n + 1\) integers where each is in \([1, n]\). Exactly one value repeats. Find it in \(O(n)\) time and \(O(1)\) space.
The array defines a functional graph: \(f(i) = \text{nums}[i]\). Starting from index 0, the sequence must enter a cycle. The cycle start corresponds to the duplicate value.
Why? Index 0 is the only index not pointed to by any value (values are in \([1, n]\)). The tail starts at index 0. The first repeated value is where the cycle begins.
int findDuplicate(vector<int>& nums) {
// Phase 1: find meeting point
int slow = nums[0], fast = nums[nums[0]];
while (slow != fast) {
slow = nums[slow];
fast = nums[nums[fast]];
}
// Phase 2: find cycle start
slow = 0;
while (slow != fast) {
slow = nums[slow];
fast = nums[fast];
}
return slow;
}
Gotcha. The starting point must be index 0, not index 1. Index 0 is guaranteed to be on the tail (no value maps to 0 since values are in \([1, n]\)). Starting inside the cycle would skip Phase 2's logic.
CSES Planets Queries II Revisited
In Lesson 2 we discussed this problem. Cycle detection helps when computing distances between two nodes in a functional graph.
If \(a\) and \(b\) are on the same cycle, the distance from \(a\) to \(b\) is the number of steps forward around the cycle. Use the cycle length from Floyd's/Brent's, combined with binary lifting for tail distances.
abc296_e: Transition Game
Problem. A functional graph on \(N\) nodes. Takahashi picks a starting node, then Aoki picks a target. Takahashi makes exactly \(K\) moves. He wins if he lands on the target. For how many starting nodes does Takahashi have a winning strategy?
Takahashi wins from node \(x\) if \(f^{(K)}(x)\) is predictable -- meaning \(x\) eventually reaches a cycle, and after \(K\) steps the position is determined. Since this is a functional graph, \(f^{(K)}(x)\) is always determined. The real question: for which \(x\) does there exist a target \(t\) such that \(f^{(K)}(x) = t\) regardless of Aoki's choice?
Actually, re-reading: Takahashi wins if the node after \(K\) steps is on a cycle (so its position is forced). If \(K\) is large enough that \(x\) has entered its cycle, the position is uniquely determined by \(K\) and the cycle structure.
A node \(x\) is winning if \(K \ge \mu_x\) (tail length). Binary lifting computes \(f^{(K)}(x)\). Cycle detection gives \(\mu_x\).
Floyd vs Brent Summary
| Floyd's | Brent's | |
|---|---|---|
| Extra space | \(O(1)\) | \(O(1)\) |
| Function calls | ~\(3(\mu + \lambda)\) | ~\(2(\mu + \lambda)\) |
| Finds \(\lambda\) directly? | No (needs Phase 3) | Yes |
| Implementation complexity | Simple | Slightly more |
Both run in \(O(\mu + \lambda)\) time. For competitive programming, Floyd's is more commonly seen because it's easier to remember. Brent's is better when function evaluations are expensive.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| CSES Planets Queries II | cses.fi/problemset/task/1160 | Hard |
| abc296_e Transition Game | atcoder.jp/contests/abc296/tasks/abc296_e | Medium |
| LC 287 Find the Duplicate Number | leetcode.com/problems/find-the-duplicate-number | Medium |