Consistent Hashing & Resharding
TL;DR
Simple modulo hashing (hash % N) breaks when you add or remove shards — nearly all keys remap. Consistent hashing maps keys and shards onto a ring, so adding a shard only moves ~1/N of the keys. Virtual nodes smooth out the distribution. This is how Cassandra, DynamoDB, and most distributed systems handle resharding.
The Problem With Simple Hashing
In the previous lesson, we used shard = hash(key) % N to distribute data. It works beautifully — until you need more shards.
Imagine you have 4 shards and a key with hash value 14:
- 14 % 4 = 2 → goes to Shard 2
Now you add a 5th shard:
- 14 % 5 = 4 → goes to Shard 4
That key just moved. And it's not alone — roughly 75% of all keys remap when you go from 4 to 5 shards. That means moving 75% of your data across the network. During a resharding event, your system is effectively doing a massive, expensive data migration.
For a database with 10TB of data, moving 7.5TB across the network while serving live traffic is somewhere between "very painful" and "impossible."
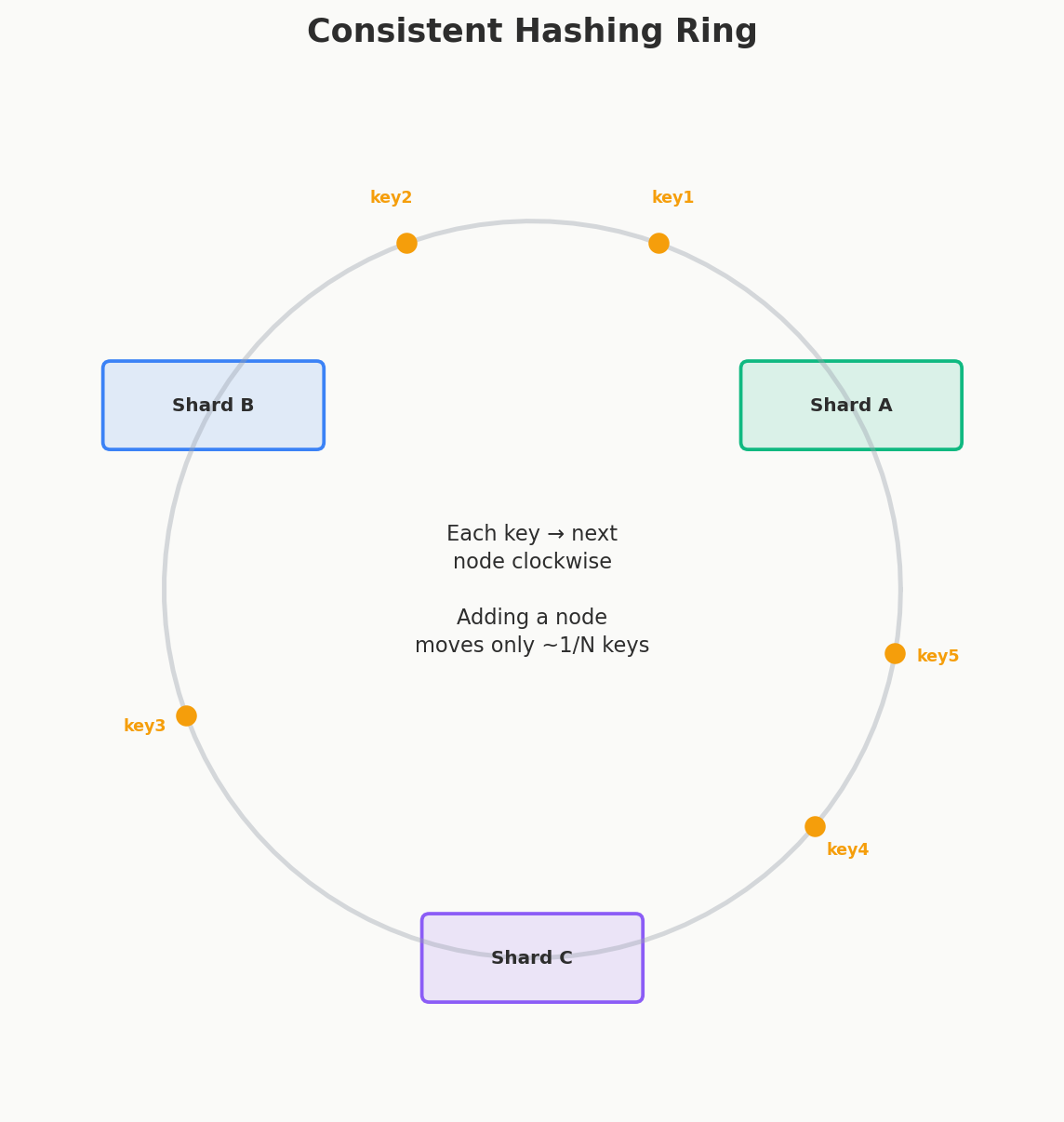
Consistent Hashing — The Ring
Consistent hashing solves this by putting both keys and shards on the same hash ring — a circular number line from 0 to some maximum value.
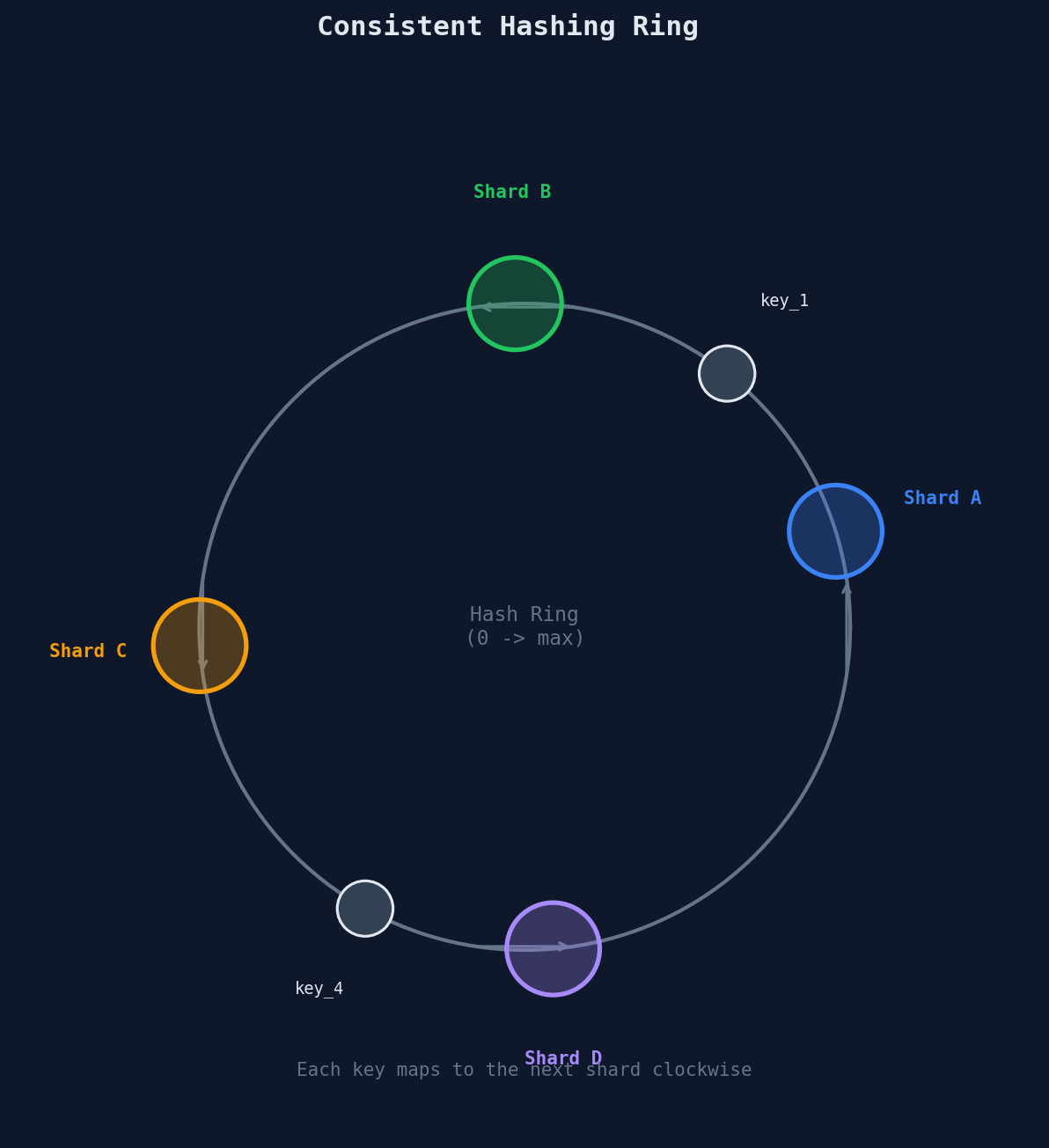
How it works: 1. Hash each shard's identifier to a position on the ring 2. Hash each key to a position on the ring 3. Each key is assigned to the next shard clockwise on the ring
Adding a shard: When Shard E is added between Shard B and Shard C, only the keys between B and E need to move to E. All other keys stay where they are.
With N shards, adding one shard moves only ~1/N of the keys. Going from 4 to 5 shards moves ~20% of keys instead of ~75%. That's the entire value proposition.
Here's the entire mechanism in 15 lines of Python:
import bisect, hashlib
class ConsistentHash:
def __init__(self):
self.ring = [] # sorted list of (hash_position, shard_name)
self.nodes = {}
def add_shard(self, name, vnodes=150):
for i in range(vnodes):
h = int(hashlib.md5(f"{name}:{i}".encode()).hexdigest(), 16)
bisect.insort(self.ring, (h, name))
def get_shard(self, key):
h = int(hashlib.md5(key.encode()).hexdigest(), 16)
idx = bisect.bisect_right(self.ring, (h,))
if idx == len(self.ring):
idx = 0 # wrap around the ring
return self.ring[idx][1]
bisect_right finds the next clockwise position on the ring. That's all consistent hashing is — a sorted list and a binary search.
Virtual Nodes — Evening Things Out
Basic consistent hashing has a problem: with only a few physical nodes, the ring can be unevenly divided. One shard might own 40% of the ring while another owns 10%.
Virtual nodes (vnodes) fix this by giving each physical shard multiple positions on the ring:
Physical Shard A → virtual positions at 0°, 90°, 180°, 270°
Physical Shard B → virtual positions at 45°, 135°, 225°, 315°
With hundreds of virtual nodes per physical shard, the distribution becomes statistically even. When a physical shard is added or removed, its virtual nodes are scattered around the ring, so the data movement is evenly distributed across all other shards.
Cassandra uses 256 virtual nodes per physical node by default. DynamoDB uses a similar approach internally.
The Math
| Approach | Keys moved on resize | Distribution evenness |
|---|---|---|
| Modulo hashing | ~(N-1)/N (nearly all) | Perfect |
| Consistent hashing (basic) | ~1/N | Uneven with few nodes |
| Consistent hashing + vnodes | ~1/N | Even |
Resharding in Production
Theory is clean. Production is messy. Here's how real systems handle resharding:
Vitess (YouTube, Slack, GitHub)
Vitess adds a sharding layer on top of MySQL:
- VSchema: Defines how tables are sharded and which columns are shard keys
- Vindexes: Pluggable sharding functions (hash, lookup, etc.)
- Resharding workflow: Split or merge shards online with zero downtime — Vitess handles the data copying, cutover, and cleanup
Slack runs Vitess at 2.3M QPS. During COVID, they stress-tested by resharding live to handle surge traffic.
CockroachDB and Spanner
These NewSQL databases make resharding invisible:
- Data is organized into ranges (CockroachDB) or splits (Spanner)
- When a range gets too large, it automatically splits into two ranges
- When a range gets too small, it merges with a neighbor
- The database handles rebalancing across nodes continuously
No shard keys, no manual resharding, no operational headaches. The trade-off: you trust the database's automatic decisions, which may not always match your access patterns perfectly.
Stripe's Live Migration Approach
Stripe migrates databases with a disciplined 6-step process:
- Double-write: Write to both old and new shards simultaneously
- Backfill: Copy historical data from old to new
- Verify: Compare old and new to ensure completeness
- Shadow read: Read from both and compare results
- Cutover: Switch reads to new shards
- Cleanup: Remove old shards
At 5M QPS, they achieve less than 2-second traffic switches with 99.999% uptime. The key: every step is reversible.
Composite Sharding
Sometimes a single shard key isn't enough. Composite sharding combines multiple factors.
Discord's Approach
Discord shards messages by (channel_id, bucket):
- channel_id: All messages for one channel on the same shard (query locality)
- bucket: Time-based bucket within the channel (prevents unbounded partition growth)
This means "get messages in channel X from the last hour" hits one shard and one bucket — optimal for their primary access pattern.
Common Composite Patterns
| Pattern | Primary Key | Secondary | Use Case |
|---|---|---|---|
| user + time | hash(user_id) |
time_bucket |
Per-user activity with time bounds |
| tenant + entity | hash(tenant_id) |
entity_id |
Multi-tenant SaaS |
| region + user | region |
hash(user_id) |
Geo-distributed with data locality |
Interview Tip
If an interviewer asks "how would you handle resharding?" — mention consistent hashing with virtual nodes for the theory, and Vitess or CockroachDB for the practice. Then say "Stripe uses a double-write → backfill → verify → cutover approach for zero-downtime migrations." That covers theory, tools, and real-world practice.
Quick Recap
| Concept | What It Solves | How |
|---|---|---|
| Consistent hashing | Massive data movement on resize | Ring-based assignment, ~1/N keys move |
| Virtual nodes | Uneven distribution with few nodes | Multiple ring positions per physical node |
| Vitess | MySQL sharding without rewriting app | Proxy layer with online resharding |
| Auto-splitting (CockroachDB) | Manual shard management | Ranges automatically split and merge |
| Double-write migration | Zero-downtime resharding | Write to both, verify, cutover |