Sharding for Write Throughput
TL;DR
When one database can't handle your write volume, split the data across multiple servers (shards). Each shard handles a portion of the writes, giving you near-linear scaling. The challenge is choosing a good shard key and handling hot partitions when one shard gets disproportionately more traffic.
The Simple Math That Changes Everything
One database server can handle, say, 10,000 writes per second. You need 100,000. You have two options: buy a server that's 10x more powerful (expensive, and there's a ceiling), or spread the writes across 10 servers.
| Servers | Write Capacity | Cost Model |
|---|---|---|
| 1 | ~10K writes/sec | Vertical — exponentially more expensive |
| 4 | ~40K writes/sec | Horizontal — linear cost |
| 10 | ~100K writes/sec | Horizontal — linear cost |
| 100 | ~1M writes/sec | Horizontal — linear cost |
The "shards" may be part of a single logical database — your application thinks it's talking to one database, but under the hood, the data is spread across multiple physical servers. Some databases handle this automatically (DynamoDB, CockroachDB). Others require you to manage it yourself (PostgreSQL, MySQL).
But here's the thing: the math only works if writes are evenly distributed across shards. If 80% of your writes land on one shard, you've gained almost nothing. Choosing how to split the data is everything.
Hash-Based Sharding
Hash a key (e.g., user_id) and use modular arithmetic (hash(key) % N) to pick a shard. This gives excellent write distribution — even sequential IDs spread evenly — but resharding is painful (changing N moves most keys) and range queries require scatter-gather across all shards. For a detailed walkthrough of hash-based partitioning mechanics, see our Data Modelling course (Ch 6, L2).
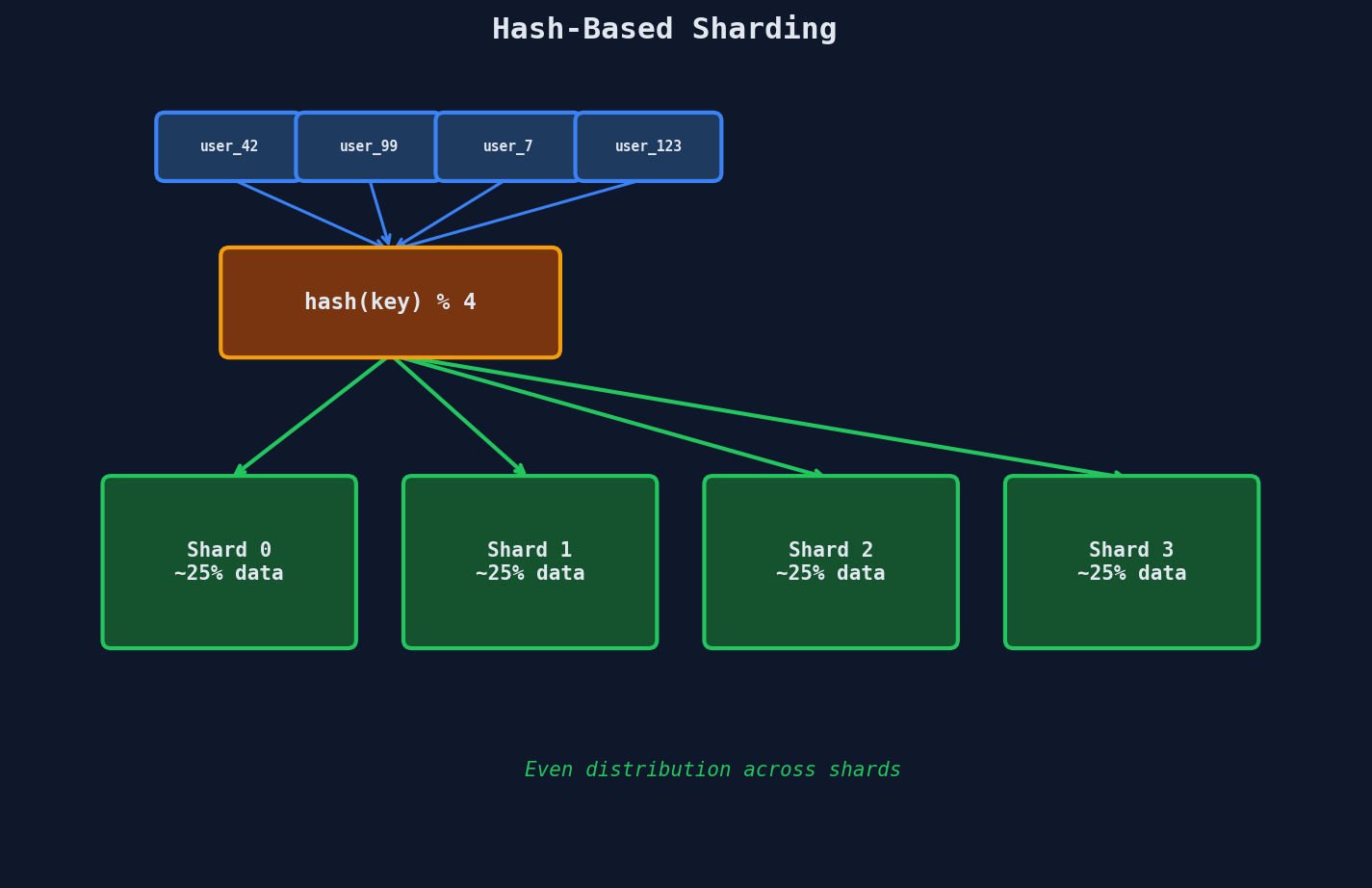
For write throughput, the key benefit is uniform distribution: no single shard becomes a bottleneck under normal conditions. The key risk is that resharding (adding/removing shards) requires migrating most of your data — a problem consistent hashing solves.
Range-Based Sharding
Split data by key ranges — each shard owns a contiguous slice (e.g., A-F, G-M, etc.) or a time window (January, February, etc.). Range queries within a shard are fast and resharding is surgical (split one range in half), but skewed key distributions create hot spots. For the full mechanics and examples, see our Data Modelling course (Ch 6, L2).
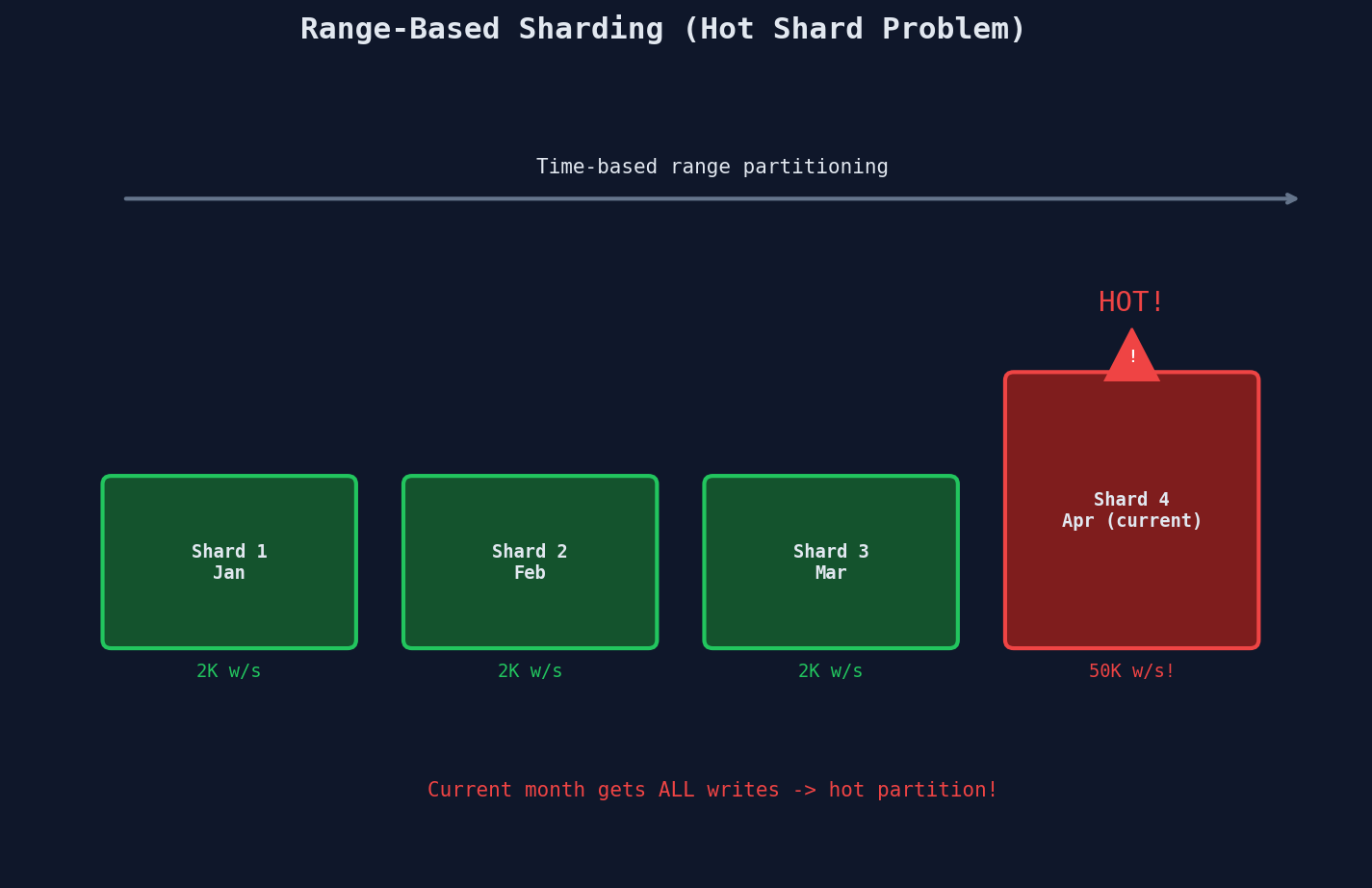
For write throughput, range-based sharding has a critical failure mode: time-based ranges concentrate ALL new writes onto the "current" shard while historical shards sit idle. If your goal is write scaling, you must combine time-based ranges with hash-based distribution within each range (compound shard key) to get both locality and distribution.
Consistent Hashing — Surviving Shard Changes
The fundamental problem with hash(key) % N is that when N changes, almost every key moves. Consistent hashing solves this by arranging shards on a hash ring — adding a node only moves ~1/N of the keys instead of nearly all of them. Virtual nodes (100-200 positions per physical node) ensure even distribution across the ring.
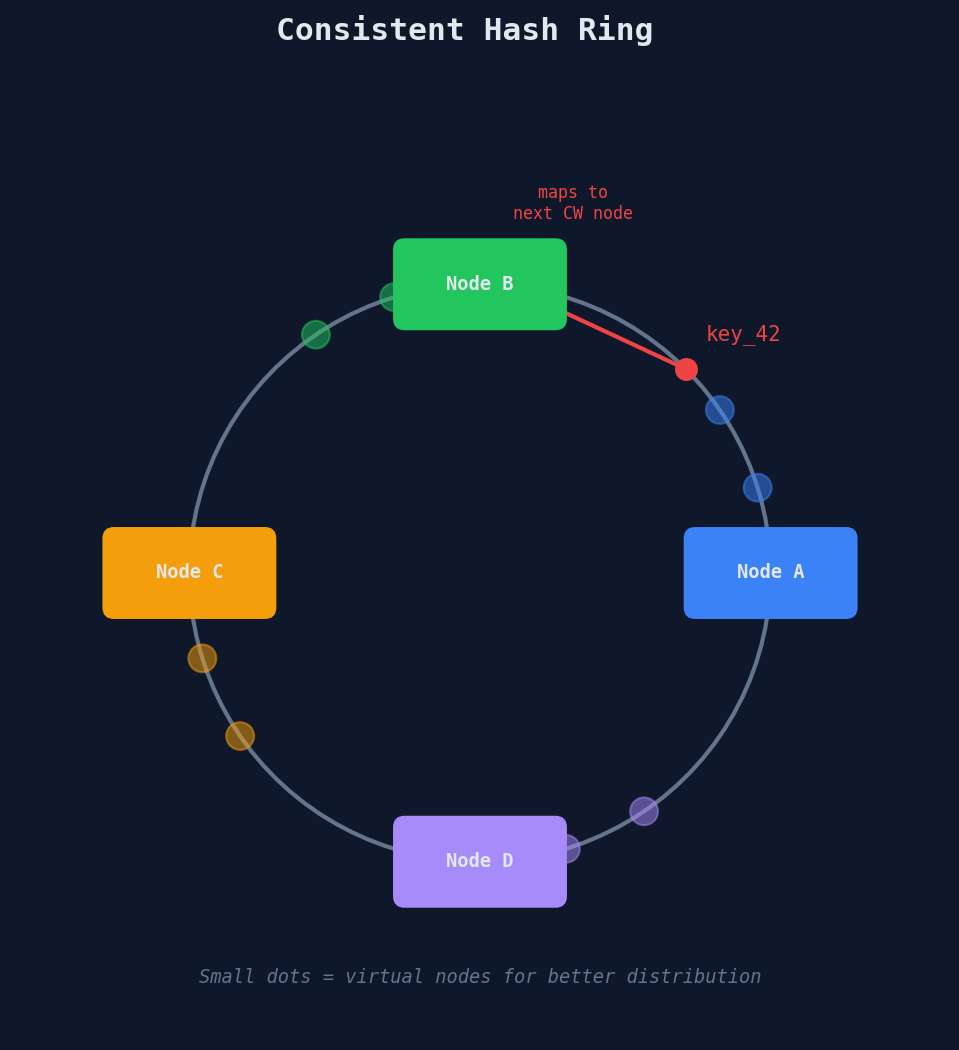
For a deep dive into how consistent hashing works — including the full algorithm, replication factor placement, and how DynamoDB uses it for partition assignment — see our Data Modelling course (Ch 6, L3).
For write throughput, the key takeaway is operational: consistent hashing lets you add shards without migrating the world. DynamoDB, Cassandra, and Riak all use it for automatic data distribution. When you add capacity to a DynamoDB table, it splits partitions and redistributes data using consistent hashing — you don't manage any of this yourself.
The Hot Partition Problem
You've sharded your database across 10 nodes. Writes are evenly distributed. Life is good.
Then a celebrity tweets. Or a product goes viral. Or a Discord server hits 100K members.
Suddenly, one shard key is receiving 1,000x the normal write volume. That key maps to exactly one shard. That shard is on fire while the other nine are bored.
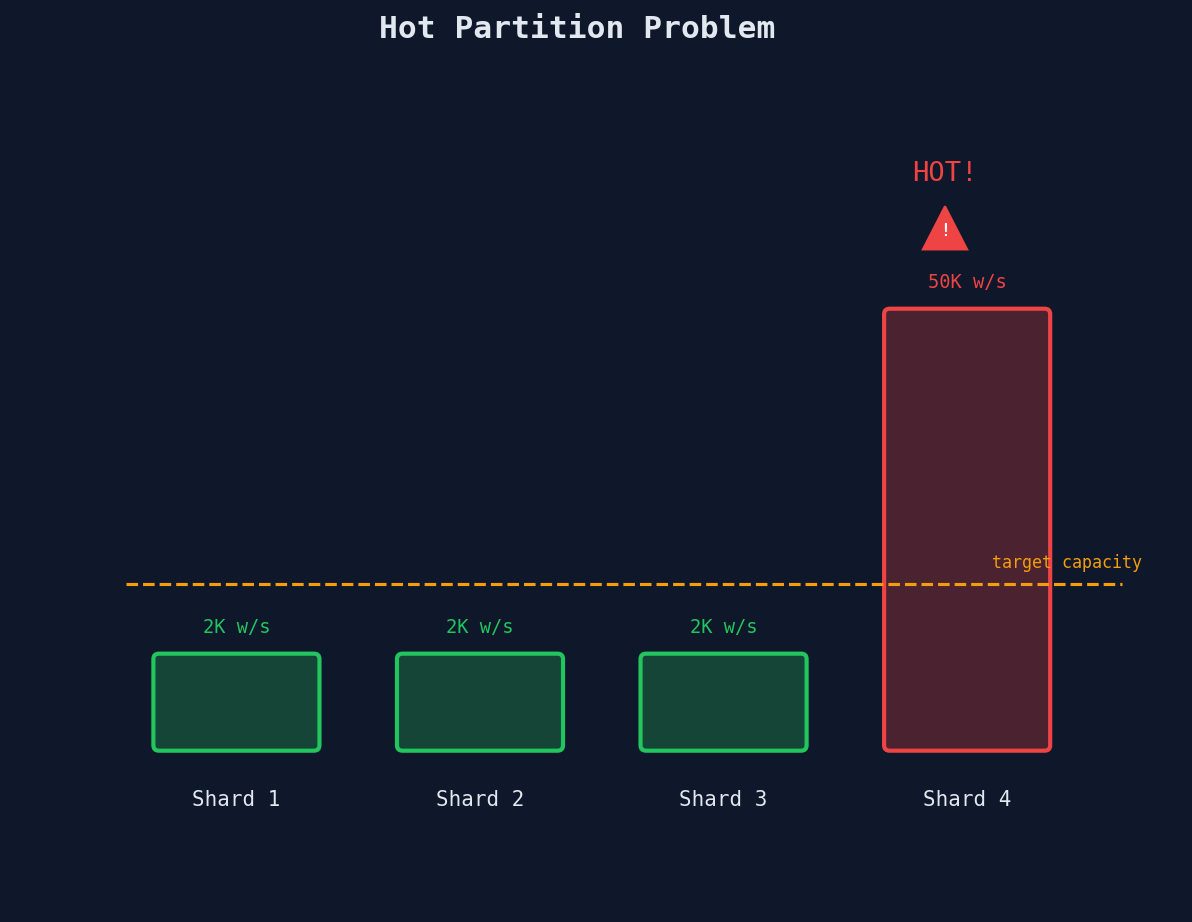
This is the hot partition problem, and it's the single most common failure mode in sharded systems.
Solution 1: Salt the Key
The idea is simple: append a random suffix to the shard key so writes for the same logical key spread across multiple shards.
import random
NUM_SALT_BUCKETS = 10
def write_like(post_id: str):
"""Distribute writes for a hot post across 10 shards."""
salt = random.randint(0, NUM_SALT_BUCKETS - 1)
shard_key = f"post:{post_id}:{salt}"
# This write could land on any of 10 different shards
db.increment(shard_key, "likes", 1)
def read_likes(post_id: str) -> int:
"""Read requires querying ALL salted keys and aggregating."""
total = 0
for salt in range(NUM_SALT_BUCKETS):
shard_key = f"post:{post_id}:{salt}"
total += db.get(shard_key, "likes", default=0)
return total
The trade-off is explicit: writes become easy (any salt, any shard), but reads become harder (query all salted keys, aggregate results).
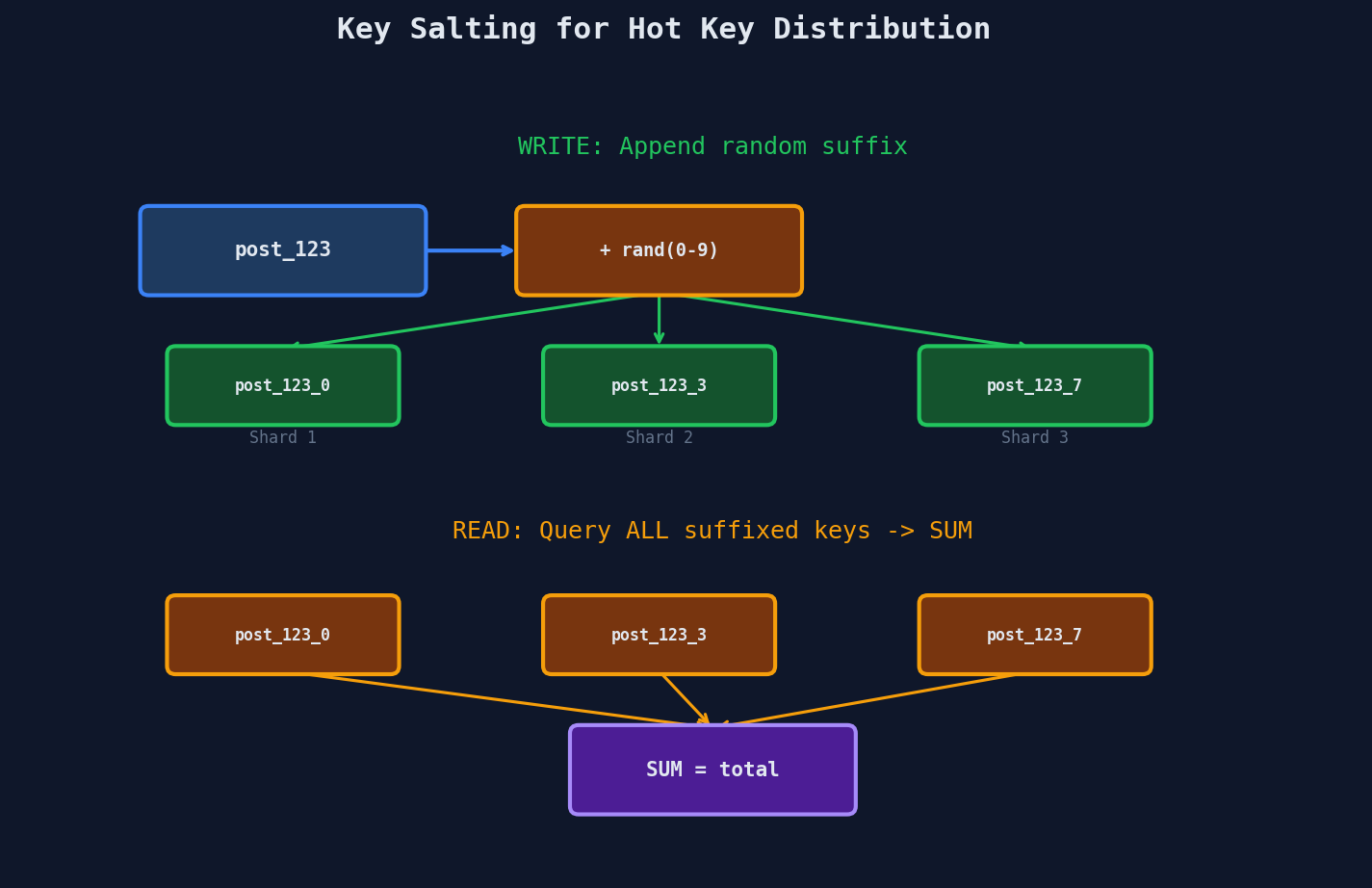
This works well when writes vastly outnumber reads on the hot key (like counters). It's a bad fit when reads are frequent and latency-sensitive.
Solution 2: Write Sharding with Distributed Counters
Instead of salting at the application level, use a dedicated distributed counter pattern where multiple shards maintain independent counts that get periodically reconciled. We'll cover this in depth in Lesson 5 (Distributed Counters and Conflict-Free Writes).
Solution 3: Adaptive Sharding
Some databases detect hot partitions automatically and split them on the fly.
- DynamoDB Adaptive Capacity monitors partition-level throughput and redistributes capacity to hot partitions — or splits them entirely if they stay hot.
- Bigtable automatically splits hot tablets when it detects sustained traffic imbalance.
- CockroachDB splits ranges automatically when they exceed a size or traffic threshold.
The advantage is obvious: you don't have to predict hot keys in advance. The disadvantage: you're trusting the database to detect and react fast enough, which may not be sufficient for sudden spikes.
Interview framing
When the interviewer asks about hot partitions, mention all three approaches. Start with key salting (shows you understand the mechanics), then mention write sharding for counters, then adaptive sharding (shows you know production systems). This demonstrates breadth.
Cross-Shard Queries — The Hidden Cost
Here's the question nobody asks during the "let's shard it!" meeting: what happens when a query needs data from multiple shards?
The answer is a scatter-gather operation:
- The application (or a routing layer) sends the query to every shard.
- Each shard executes the query against its local data and returns a partial result.
- The application merges all partial results into a final answer.
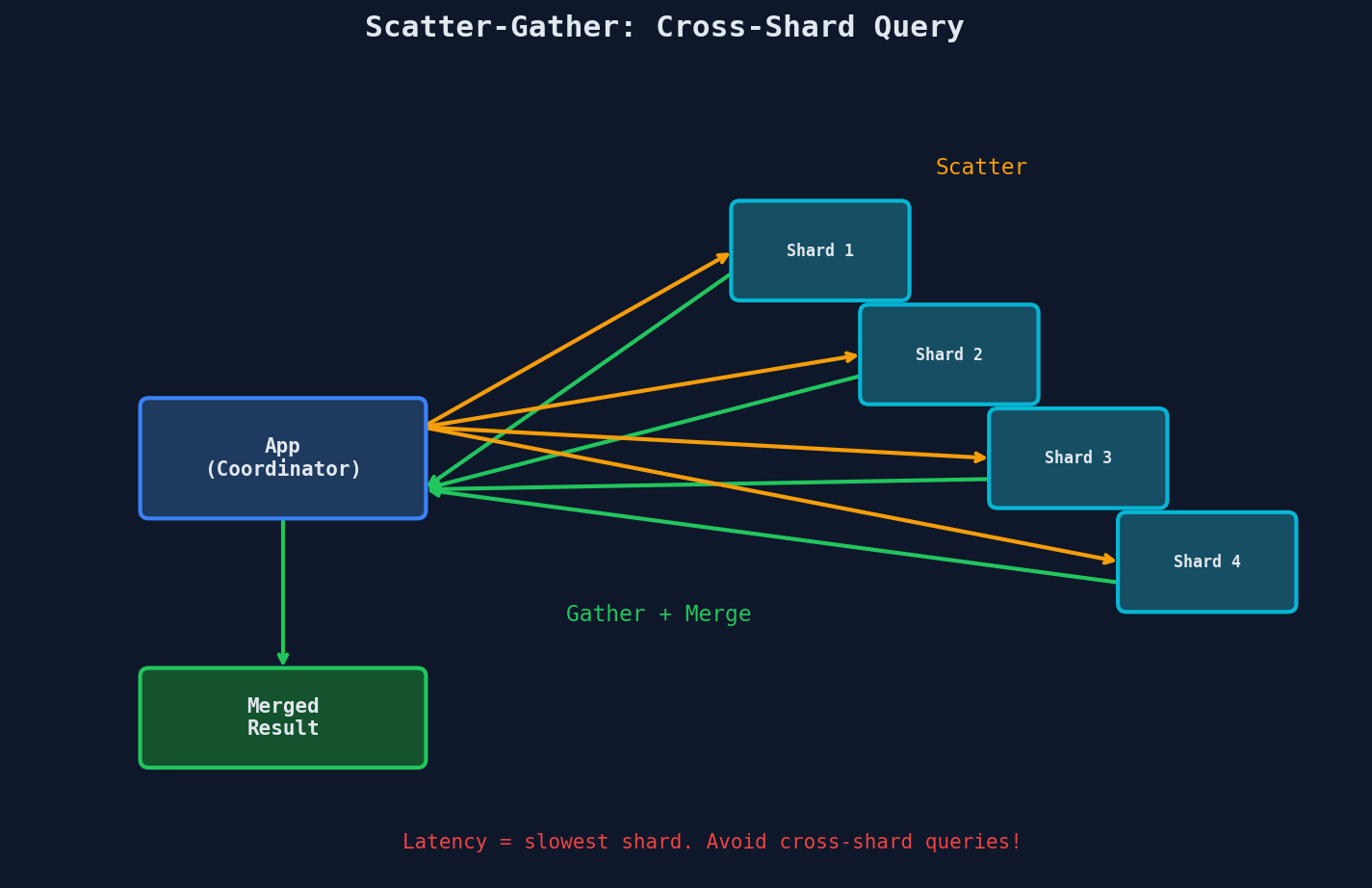
This is slow (latency = slowest shard) and expensive (4x the compute). And it gets worse with sorting, pagination, or JOINs across shards.
The takeaway: choose your shard key to minimize cross-shard queries.
| Shard Key | "Get user's orders" | "Get all users in NYC" |
|---|---|---|
user_id |
Fast — single shard | Slow — all shards |
city |
Slow — all shards | Fast — single shard |
order_id |
Slow — all shards | Slow — all shards |
Interview Tip
"Choose a shard key that groups data accessed together. If you shard by user_id, getting all of one user's data is fast (single shard). Getting all users in a city is slow (scatter-gather across all shards). There is no shard key that makes every query fast — you're choosing which queries to optimize."
Choosing Your Strategy
| Strategy | Distribution | Resharding Cost | Range Queries | Best For |
|---|---|---|---|---|
| Hash-based | Excellent — uniform | Terrible — most keys move | Expensive — all shards | Key-value lookups, user data |
| Range-based | Risk of hot spots | Low — split one range | Efficient within a range | Time-series, logs, sequential data |
| Consistent hashing | Good (with vnodes) | Minimal — ~1/N keys move | Expensive — all shards | Dynamic clusters, auto-scaling |
Most production systems don't pick one in isolation. DynamoDB uses consistent hashing for partition placement but range-based ordering within each partition. Cassandra uses consistent hashing across nodes with sorted data within partitions. The strategies compose.
A common pattern for write-heavy applications: use consistent hashing to distribute partitions across nodes (so you can add/remove nodes without chaos), and within each partition, store data in sorted order by a clustering key (so range queries within a partition are efficient). This gives you the best of both worlds — horizontal scalability for writes and ordered access for reads.
The decision also depends on whether your workload is predictable. If you know which keys will be hot ahead of time, range-based or hash-based sharding with pre-split partitions works well. If traffic patterns are unpredictable, consistent hashing with adaptive splitting is safer.
The Discord Migration Story
Discord originally stored messages in Cassandra, sharded by (channel_id, bucket). This worked well for most channels. But mega-servers with 100,000+ members had channels where a single partition held millions of messages.
When Cassandra runs compaction (merging SSTables on disk), it has to read and rewrite these massive partitions. The compaction storms spiked tail latency for read operations — some queries that normally took 5ms would suddenly take 5 seconds during compaction.
Discord's fix wasn't just "shard differently." They migrated from Cassandra to ScyllaDB (a C++ rewrite of Cassandra) and re-engineered their data model to use smaller, more numerous partitions. The lesson: your shard key design doesn't just affect write distribution — it affects every maintenance operation the database performs internally.
Sharding Is a One-Way Door
Once you shard, you can't easily un-shard. Merging data back onto a single server means migrating everything, rewriting application code, and handling the transition period where data lives in both places. Make sure you've exhausted vertical optimization (Lesson 2) before you commit to sharding. The best shard is the one you never needed.
Interview Tip
In system design interviews, don't jump to sharding immediately. Show the interviewer you understand the progression: optimize the single database first (indexes, query tuning, connection pooling), then read replicas for read scaling, then caching, and only then sharding when write throughput is the bottleneck. This shows maturity — junior candidates shard everything on slide one.