Specialized Models
TL;DR
Graph databases, search engines, and NewSQL databases solve problems that general-purpose databases can't. But they're additions to your architecture, not replacements. Start with a relational database, then add specialized stores when a specific access pattern demands it.
The Toolbox Analogy
A hammer is great, but sometimes you need a screwdriver. Relational databases are the hammer — they handle 90% of the job. But some access patterns are fundamentally different, and forcing them into a relational model creates more pain than it solves.
This lesson covers three categories of specialized databases and when they earn their place in your architecture.
Graph Databases — When Relationships Are the Data
How They Work
Graph databases store data as nodes (entities) and edges (relationships between them). Unlike relational databases where relationships are computed at query time via joins, graph databases store relationships as first-class citizens on disk.
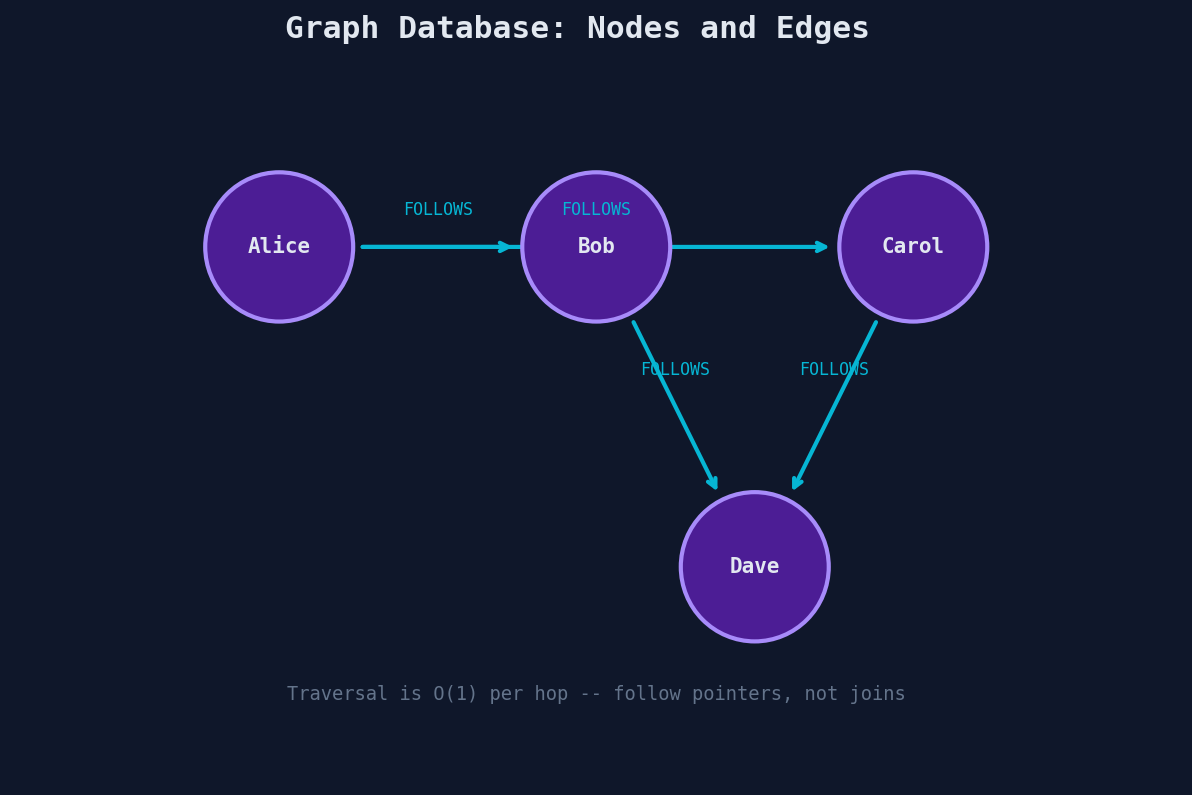
Traversing relationships is O(1) per hop — you follow a pointer, not a join. This makes multi-hop queries fast:
-- Neo4j: Find friends-of-friends Alice hasn't followed yet
MATCH (alice:User {name: 'Alice'})-[:FOLLOWS]->()-[:FOLLOWS]->(suggestion)
WHERE NOT (alice)-[:FOLLOWS]->(suggestion)
AND suggestion <> alice
RETURN suggestion.name
When Graphs Actually Help
| Use Case | Why Graph Wins |
|---|---|
| Fraud detection | Detect rings of accounts transferring money in circles |
| Recommendation engines | "Users who liked X also liked Y" — traverse preference edges |
| Knowledge graphs | Wikipedia-style "related concepts" with arbitrary depth |
| Network topology | "Which switches are between server A and server B?" |
| Access control | "Does user X have permission Y through any group membership chain?" |
When Graphs Don't Help (And This Is Important)
Here's the uncomfortable truth: even Facebook doesn't use a graph database for the social graph. Facebook TAO stores the social graph in sharded MySQL with a caching layer on top. The graph model at Facebook is a logical abstraction — the physical storage is relational.
Why? Because most social media queries don't need deep graph traversals. "Show me Alice's friends" is a simple one-hop query that a relational database with a follows table handles perfectly. "Show me friends-of-friends-of-friends" (3+ hops) is where graph databases shine — and most products never need that.
Interview Tip
Don't mention graph databases in a system design interview unless the problem explicitly involves multi-hop relationship traversal (fraud detection, recommendation engines, access control). For social media apps, a relational follows table with proper indexes is the correct answer.
Technologies
- Neo4j: Most popular, Cypher query language, ACID transactions
- Amazon Neptune: Managed, supports both property graph (Gremlin) and RDF (SPARQL)
Search Engines — When You Need Full-Text and Fuzzy Matching
The Problem Relational Databases Can't Solve Well
LIKE '%term%' can't use a B-tree index (the leading % prevents it). It scans every row. And it can't handle typos ("wireles headphone"), synonyms ("earbuds"), or relevance ranking.
How Elasticsearch Works
Elasticsearch builds an inverted index — the same structure used by search engines like Google.
Normal index: document → words in that document Inverted index: word → documents containing that word
Inverted Index:
"wireless" → [doc_1, doc_5, doc_12]
"headphone" → [doc_1, doc_3, doc_5]
"bluetooth" → [doc_1, doc_5, doc_8]
Searching for "wireless headphone" → intersect the two posting lists → [doc_1, doc_5]. Fast, regardless of how many documents exist.
Elasticsearch also handles: - Fuzzy matching: "wireles" still finds "wireless" - Tokenization: Breaking text into searchable terms - Relevance scoring: Results ranked by TF-IDF or BM25 - Autocomplete: Prefix matching with edge-ngrams
The Pattern: Search Alongside Primary Database
Elasticsearch is not a primary database — it doesn't provide ACID transactions or referential integrity. The standard pattern:
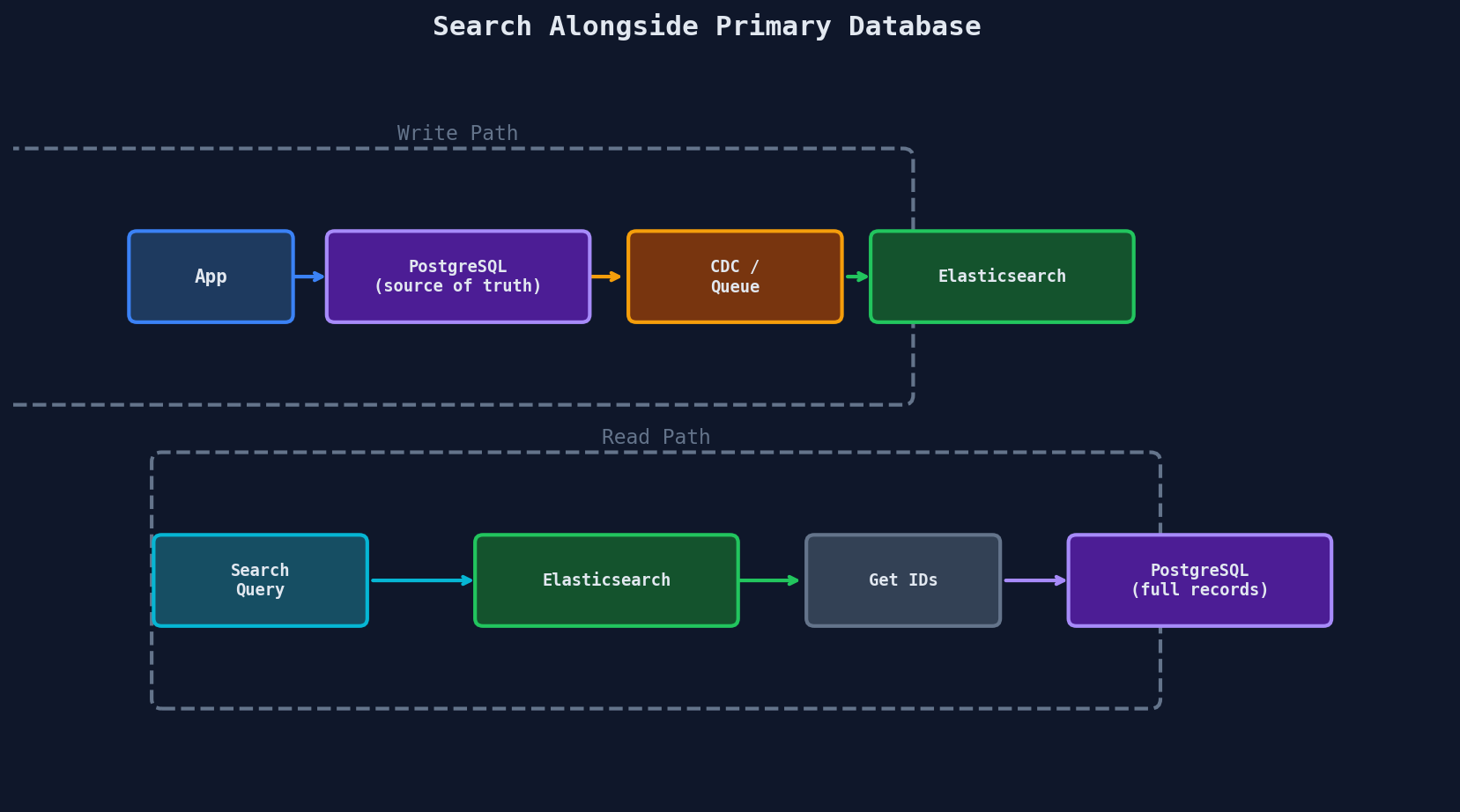
You write to your relational database first (source of truth), then asynchronously sync to Elasticsearch for search queries. This means search results may be slightly behind (eventual consistency), which is acceptable for most use cases.
When to Add Search
| Signal | Example |
|---|---|
| Full-text search across large text fields | Product descriptions, articles, reviews |
| Autocomplete / type-ahead | Search bars, address lookup |
| Fuzzy matching needed | Handling typos in user queries |
| Complex filtering + sorting + relevance | E-commerce product search with facets |
| Log analysis | Centralized logging (ELK stack) |
NewSQL — Distributed SQL That Actually Scales
The Gap NewSQL Fills
Traditional SQL: strong consistency + transactions, but scaling means manual sharding. NoSQL: horizontal scaling, but you give up joins, transactions, and SQL. NewSQL: horizontal scaling with full SQL, ACID transactions, and automatic sharding.
Google Spanner
The original NewSQL database, built by Google:
- TrueTime: Uses atomic clocks and GPS receivers in every data center to provide globally consistent timestamps. This enables external consistency — if transaction A commits before transaction B starts (in real time, anywhere in the world), every reader sees A before B.
- Automatic sharding: Data is split into "splits" that automatically rebalance across nodes.
- SQL interface: Full SQL with joins, secondary indexes, and transactions.
The trade-off: higher write latency (cross-region consensus) for global consistency. Not available outside Google Cloud.
CockroachDB
The open-source Spanner-inspired database:
- Uses Raft consensus for replication (instead of Paxos)
- Automatic range splits: As data grows, ranges split and rebalance across nodes — no manual shard key management
- Full PostgreSQL-compatible SQL
- Geo-partitioning: Pin data to specific regions for compliance (GDPR)
-- CockroachDB: Geo-partition user data by region
ALTER TABLE users PARTITION BY LIST (region) (
PARTITION eu VALUES IN ('eu-west', 'eu-central'),
PARTITION us VALUES IN ('us-east', 'us-west')
);
TiDB
MySQL-compatible NewSQL from PingCAP. Uses Raft consensus and a separate TiKV storage engine. Common in organizations with large MySQL deployments that need horizontal scaling without rewriting applications.
When NewSQL Makes Sense
| Signal | Why NewSQL |
|---|---|
| Need horizontal scaling WITH ACID transactions | The original SQL vs NoSQL compromise disappears |
| Global distribution with consistency | Spanner/CockroachDB handle cross-region consistency |
| Existing SQL application that's outgrowing one server | Drop-in replacement (CockroachDB ≈ PostgreSQL, TiDB ≈ MySQL) |
| Regulatory requirements for data locality | Geo-partitioning keeps data in specific regions |
Geospatial Indexes — When Location Is the Query
If your system design involves "find nearby restaurants" or "drivers within 5km," you need geospatial indexing. Relational databases handle this with extensions:
Under the hood, these use R-trees (PostGIS), Quadtrees (subdivide 2D space recursively), or Geohashes (encode lat/lng into a sortable string for range queries). You don't need to implement them — but name-dropping "I'd use a Geohash index" or "PostGIS with ST_DWithin" in an interview shows you know the data layer for location-based systems.
Polyglot Persistence — Using Multiple Databases Together
Most real-world systems use more than one database. This is called polyglot persistence — choosing the right database for each specific workload.
Netflix's Stack
| Database | Use Case |
|---|---|
| Cassandra | User activity, viewing history (write-heavy, time-ordered) |
| MySQL | Billing, account management (ACID transactions) |
| Elasticsearch | Content search, recommendations |
| Redis | Session storage, caching |
| S3 | Video storage |
The Decision Framework
1. Start with PostgreSQL (or MySQL) as your primary database
2. For each access pattern that struggles, ask:
a. Can I solve it with an index or query optimization? → Do that
b. Can I solve it with a cache (Redis)? → Add a cache
c. Do I need full-text search? → Add Elasticsearch
d. Do I need massive write throughput for time-series? → Add Cassandra or TimescaleDB
e. Do I need multi-hop graph traversals? → Add Neo4j
f. Do I need horizontal SQL scaling? → Consider CockroachDB/Spanner
3. Every additional database adds operational complexity — justify it
Interview Tip
In an interview, don't jump to multiple databases. Start with one (relational). Only add a second when a specific access pattern can't be served by the primary database. "I'll use PostgreSQL as the primary store, and add Elasticsearch for product search because LIKE queries can't handle fuzzy matching or relevance ranking at scale." That's a justified decision.
Quick Recap
| Database Type | When to Use | When NOT to Use |
|---|---|---|
| Graph (Neo4j) | Multi-hop traversals, fraud, recommendations | Social media (a follows table works fine) |
| Search (Elasticsearch) | Full-text search, autocomplete, fuzzy matching | As a primary database (no ACID) |
| NewSQL (CockroachDB) | Need SQL + horizontal scaling + ACID | Small datasets that fit on one server |
| Polyglot | Different access patterns need different databases | Early-stage products (start with one DB) |