Architecture Patterns Cheat Sheet
TL;DR
Seven signals in requirements map to seven architecture patterns. Spot the signal, name the pattern, apply the techniques. This cheat sheet is the entire course compressed into decision tables, key numbers, and flowcharts you can internalize the night before your interview.
Signal → Pattern → Key Decision → Pitfall
Every system design question is broadcasting signals. The interviewer describes a system, and buried in the requirements are clues that point you to specific patterns. Your job is to hear the signal, name the pattern, and make the right trade-off.
| Signal in Requirements | Pattern | Key Decision | Pitfall |
|---|---|---|---|
| Read-heavy (100:1 ratio) | Caching + Read Replicas | Cache invalidation strategy | Stampede, stale reads |
| Write-heavy (1M writes/s) | Sharding + Batching + LSM DB | Partition key choice | Hot partitions |
| Concurrent access to same resource | Pessimistic or Optimistic locking | Contention level | Deadlocks, retry storms |
| Users need updates without refreshing | WebSocket or SSE | One-way vs bidirectional | Fan-out cost, connection limits |
| Operation takes >5 seconds | Async + Job Queue | Progress tracking | Dual-write problem |
| Multiple services must coordinate | Saga + Orchestration | Compensation logic | Pivot transaction, idempotency |
| Files >10MB | Presigned URLs + Chunking | Resume support | Orphan blobs |
This table is the skeleton key. Memorize it. When the interviewer says "users upload 4K videos," your brain should fire: large files → presigned URLs + chunking → need resume support → watch for orphan blobs.
The Numbers That Matter
You don't need to memorize every benchmark. But walking into an interview without rough numbers is like estimating construction costs without knowing the price of concrete.
Storage and Throughput
| Component | Reads | Writes | Latency | Notes |
|---|---|---|---|---|
| PostgreSQL | 5K–20K QPS | 5K–20K TPS | 5–50ms (indexed) | B-tree indexes, MVCC |
| Redis | 100K–200K ops/sec | 100K–200K ops/sec | 0.1–1ms | Single-threaded, in-memory |
| Kafka | N/A | 500K+ msg/sec per broker | 2–10ms | Append-only log, partitioned |
| DynamoDB | Unlimited (with $$) | Unlimited (with $$) | <10ms | Pay per RCU/WCU |
Network and Delivery
| Metric | Value | When It Matters |
|---|---|---|
| CDN edge latency | 1–5ms | Static content, media streaming |
| Replication lag (async) | 10ms–1s | Read-after-write consistency |
| Cross-region latency | 50–200ms | Multi-region architectures |
| WebSocket connections per server | 50K–100K | Chat, live updates, collaboration |
| S3 durability | 99.999999999% (11 nines) | File storage, backups |
Cache Performance
| Cache Hit Ratio | Assessment | Action |
|---|---|---|
| < 80% | Poor | Wrong key design or too small cache |
| 80–90% | Acceptable | Review TTLs and eviction policy |
| 90–99% | Good | Standard production target |
| > 99% | Excellent | Static or slowly-changing data |
Using Numbers in Interviews
Don't recite numbers unprompted. Use them when making trade-off arguments: "Redis handles 100K+ ops/sec at sub-millisecond latency, so a single instance covers our read load. We don't need to shard the cache — we need to shard the database."
The Baseline Architecture
This architecture handles 80% of system design interview questions. Start here, then modify based on the signals you spot.
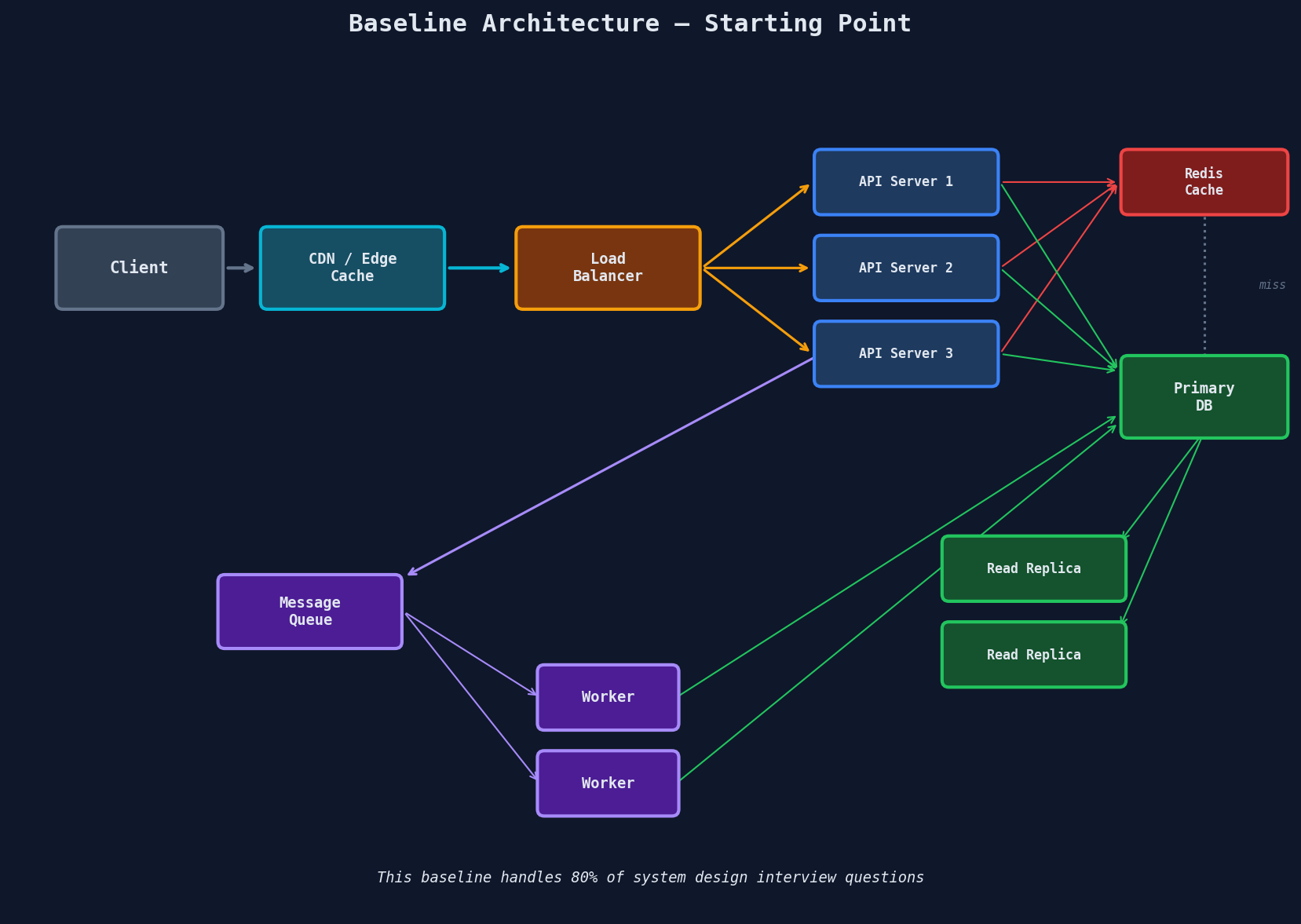
When to add to this baseline:
| Requirement | Add This |
|---|---|
| Global users | Multi-region + CDN for static assets |
| Real-time updates | WebSocket gateway between LB and clients |
| Large file uploads | Object storage (S3) + presigned URL flow |
| High write volume | Sharded database, partition by tenant/user |
| Multi-step transactions | Saga orchestrator between API and services |
| Search | Elasticsearch/OpenSearch alongside primary DB |
Don't add components you can't justify. Every box on the diagram is a question the interviewer can ask. If you draw Kafka, you'd better be able to explain why a simple Redis queue won't work.
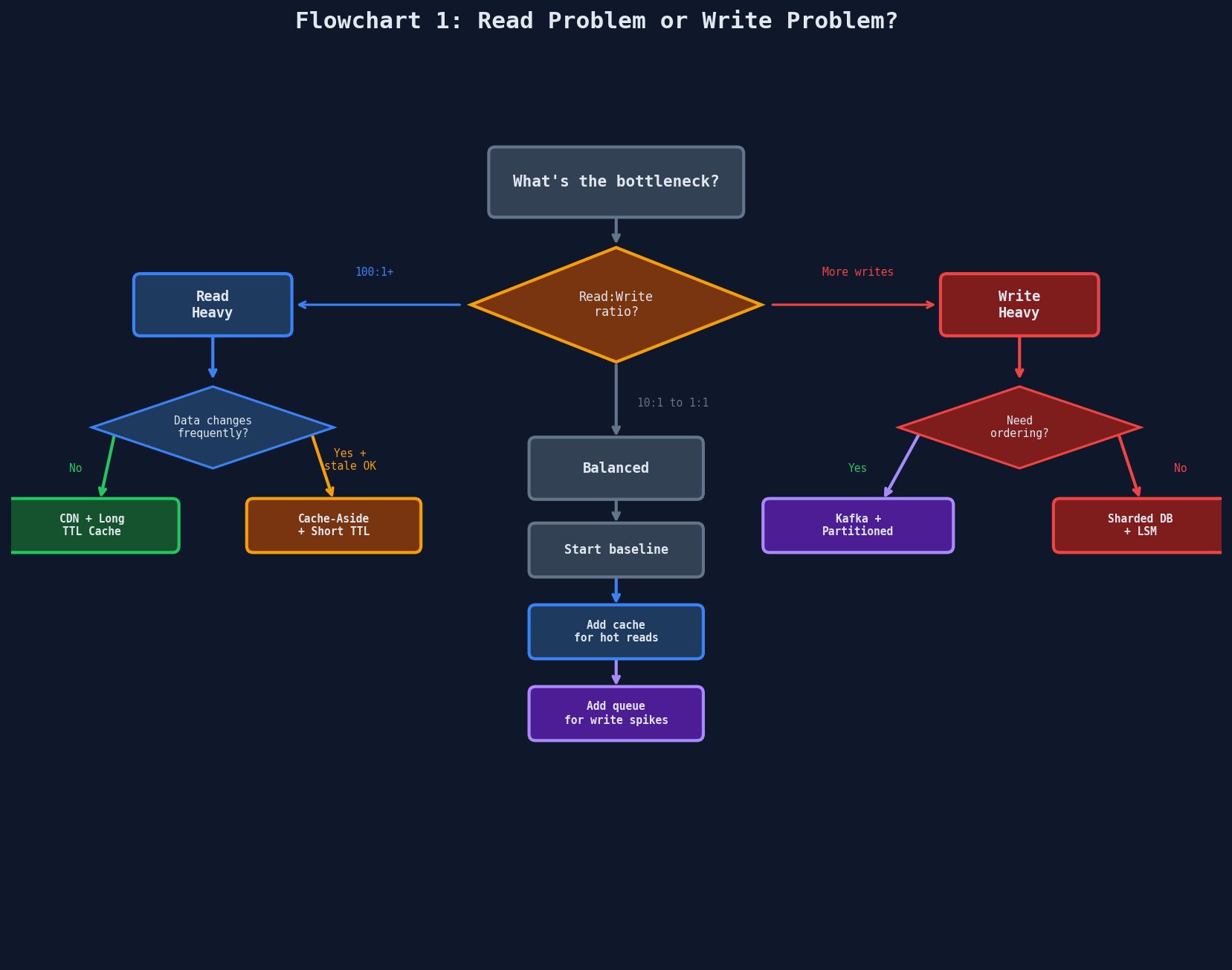
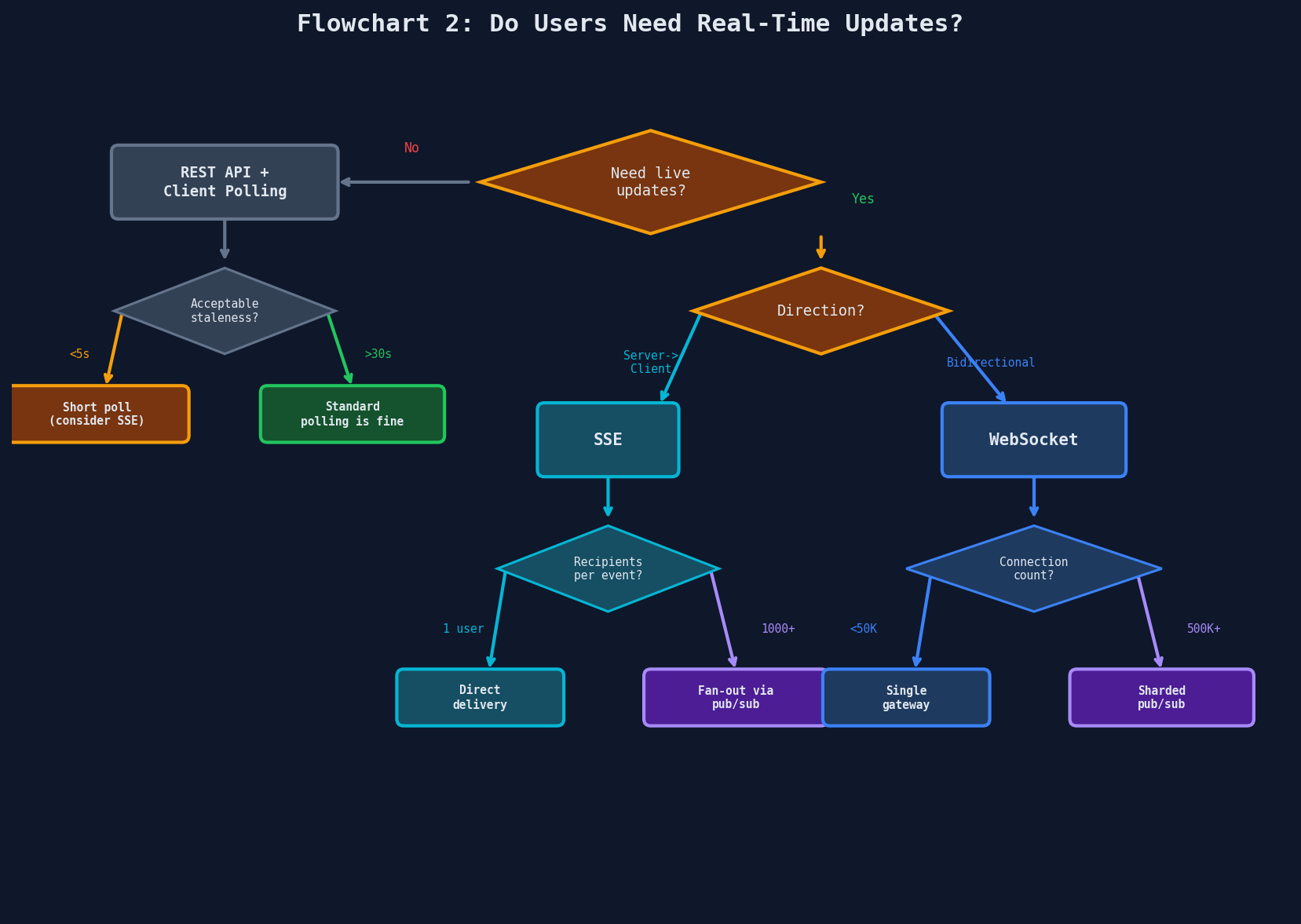
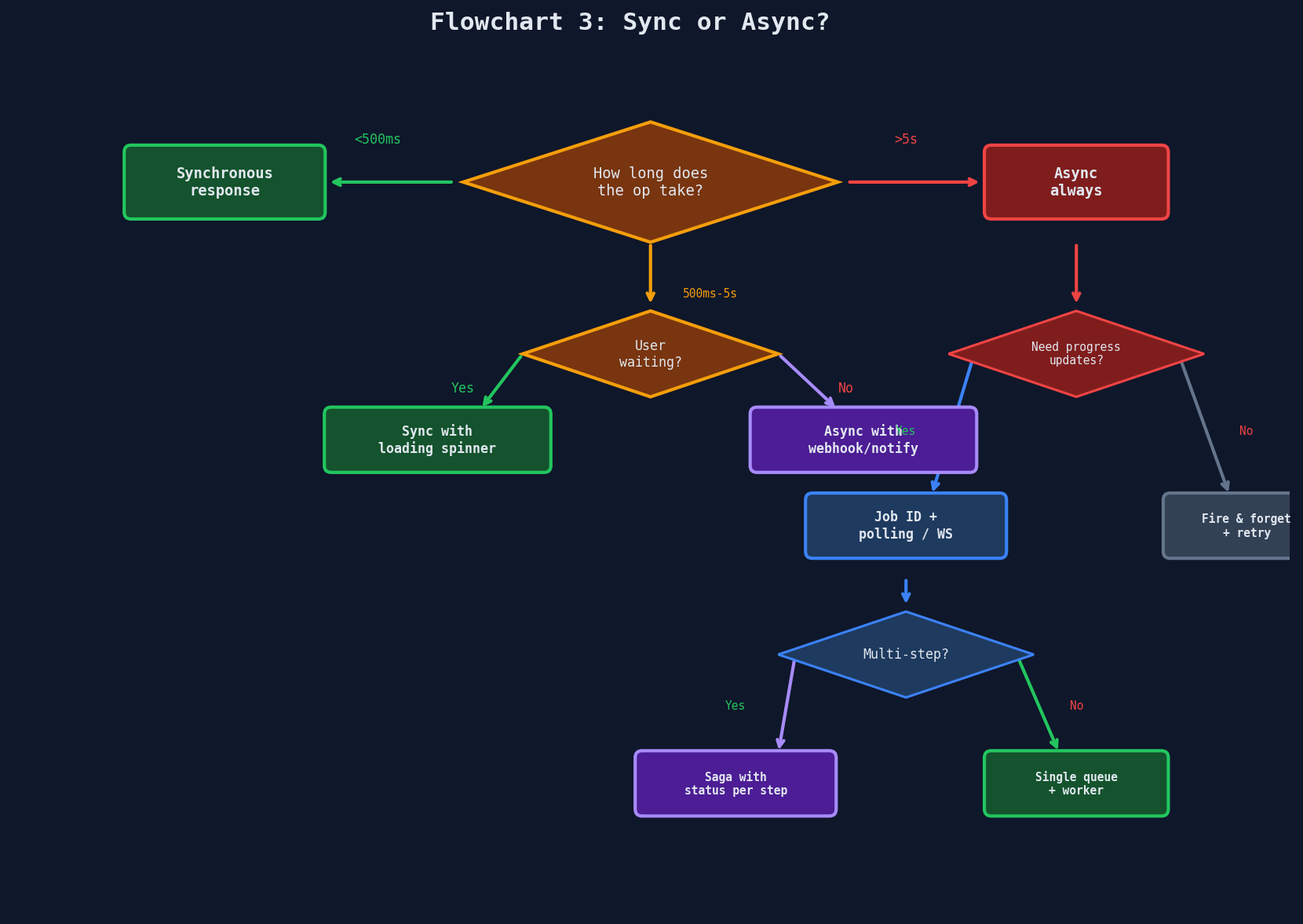
Decision Flowcharts
When you're mid-interview and the requirements are piling up, these three flowcharts cut through the noise.
Flowchart 1: Read Problem or Write Problem?
Flowchart 2: Do Users Need Real-Time Updates?
Flowchart 3: Sync or Async?
Pattern Selection by Interview Question Type
Not sure which pattern the question is testing? Here's a shortcut based on the type of system.
| System Type | Examples | Primary Patterns |
|---|---|---|
| Social / Feed | Instagram, Twitter, News Feed | Scaling Reads + Fan-out + CDN |
| Messaging / Chat | WhatsApp, Slack, Discord | Push Architecture + Presence + Message Queue |
| E-commerce / Booking | Ticketmaster, Uber, Hotel Booking | Concurrency Control + Async + Saga |
| Media / Storage | YouTube, Dropbox, Google Drive | Large Files + Async Processing + CDN |
| Analytics / Monitoring | Metrics Dashboard, Ad Clicks, Top K | Scaling Writes + Aggregation + Batch |
| Payments / Financial | Payment System, Stock Trading | Distributed Workflows + Idempotency + Locking |
The Five-Minute Framework
When you sit down in the interview, spend the first five minutes on this:
Minute 1–2: Gather requirements and spot signals.
- What's the read/write ratio?
- Do users need real-time updates?
- What's the data size per object?
- How many concurrent users?
- What consistency guarantees matter?
Minute 3: Name your patterns.
"This is a read-heavy system with real-time notifications, so I'll focus on caching with read replicas for the catalog, and WebSocket for live updates."
Minute 4–5: Draw the baseline architecture, modified for your signals.
Start with the baseline diagram above. Add or remove components based on what you identified. Every component you add should map to a signal you spotted.
The Biggest Interview Mistake
Drawing a complex architecture and then being unable to explain why each component exists. Start simple. Add complexity only when requirements demand it. The interviewer would rather see you thoughtfully add a message queue when you identify an async processing need than see you draw Kafka, Redis, Elasticsearch, and a service mesh in your opening diagram.
Quick-Reference: Cache Invalidation Strategies
Because this comes up in nearly every interview.
| Strategy | How It Works | Consistency | Use When |
|---|---|---|---|
| Cache-Aside | App checks cache, fills on miss | Eventual (stale window) | Most read-heavy workloads |
| Read-Through | Cache fetches from DB on miss | Eventual | Same as cache-aside, cleaner code |
| Write-Through | Write to cache and DB together | Strong | Can't tolerate stale reads |
| Write-Behind | Write to cache, async flush to DB | Eventual (risk of loss) | Write-heavy, can tolerate loss |
| TTL-Based | Expire after fixed time | Eventual (bounded staleness) | Simple, predictable invalidation |
Quick-Reference: Database Selection
| Requirement | Choose | Avoid |
|---|---|---|
| Transactions + joins | PostgreSQL / MySQL | DynamoDB, Cassandra |
| Key-value at scale | DynamoDB / Redis | PostgreSQL at >100K QPS |
| Time-series data | InfluxDB / TimescaleDB | Generic RDBMS |
| Full-text search | Elasticsearch / OpenSearch | LIKE queries on RDBMS |
| Graph relationships | Neo4j / Neptune | Recursive SQL joins |
| Document storage | MongoDB / DynamoDB | When you need joins |
Quick-Reference: Queue Selection
| Requirement | Choose | Why |
|---|---|---|
| Simple task queue | Redis (list/stream) or SQS | Low overhead, easy setup |
| Ordering guarantees | Kafka (partitioned) | Per-partition ordering |
| Exactly-once semantics | Kafka + idempotent consumers | Dedup with idempotency keys |
| Fan-out to many consumers | Kafka or SNS+SQS | Consumer groups, topic subscriptions |
| Delayed/scheduled jobs | SQS (delay queues) or custom | Built-in delay support |
Everything on this page came from the seven chapters before it. If any row in any table feels unfamiliar, go back to that chapter. The cheat sheet is for recall, not for learning.