Regionalization & Latency
TL;DR
No matter how fast your code is, you can't beat physics. Data traveling halfway around the world takes time — and that delay adds up. The solution? Put copies of your data closer to your users. CDNs cache static content at the edge; regional partitioning puts entire databases near the users who need them.
The One Thing You Can't Optimize Away
You can write faster code. You can upgrade your servers. You can tune your database queries until they scream. But there's one bottleneck that no amount of engineering can fix: the speed of light.
Light through fiber optic cables travels at about 200,000 km/s. A round trip from New York to London (roughly 5,600 km) has a minimum latency of about 56 milliseconds — and that's just physics. No processing, no queuing, no routing. Just photons traveling through glass.
Here's where it gets painful. If a single page load needs 5 back-to-back API calls, that's 5 × 56ms = 280 milliseconds of pure waiting. Your code could run in nanoseconds and you'd still feel that delay. Users notice, and they don't like it.
The Golden Rule: Keep Data Close to the People Using It
This principle shows up everywhere in computing, not just networking: performance is best when data is close to the thing that needs it. CPU caches, database indexes, in-memory caches — they all exist because accessing nearby data is faster than fetching it from far away.
For global services, "nearby" means geographically close. Two strategies make this happen: CDNs and regional partitioning.
CDNs — Like Local Branches of a Library
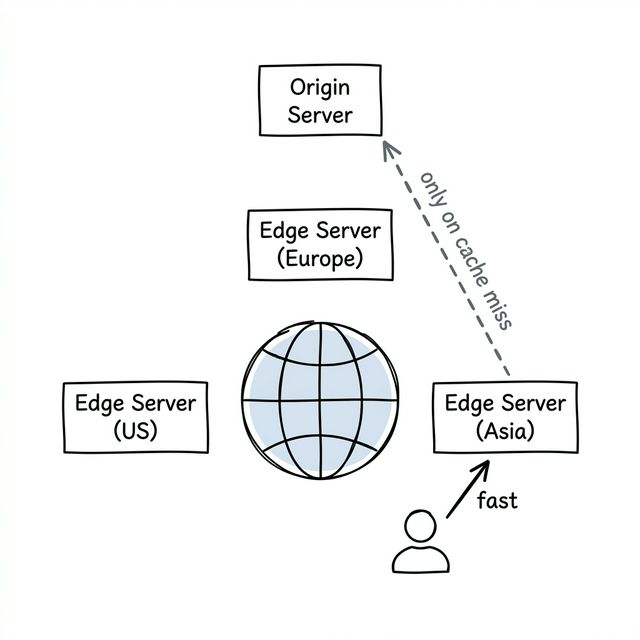
A CDN (Content Delivery Network) is a network of servers spread across the globe — often in hundreds of cities. These servers are called edge locations, and their job is to store copies of your data close to users. By reducing the physical distance, a ~~CDN~~ dramatically cuts ~~latency~~ for users around the world.
Think of it like a library system. The main library (your origin server) has every book. But instead of making everyone drive across town, the system puts popular books in small branch libraries throughout the city. When you want a book, you check the branch near your house first. If they have it — great, you're done. If not, they order it from the main library, give it to you, and keep a copy for the next person who asks.
That's exactly how CDNs work:
- User requests a resource
- CDN checks the nearest edge location: "Do I have this cached?"
- Yes? Serve it instantly — the data is practically down the street
- No? Fetch from the origin server, serve it to the user, and cache it at the edge
What CDNs Are Great For
CDNs shine with data that's read often and doesn't change frequently:
- Static assets — Images, CSS, JavaScript files, videos
- Cacheable API responses — Search results, product catalogs, public data
- Any content where a slightly stale copy is acceptable — If your blog post was cached 2 minutes ago and you just fixed a typo, the CDN might still show the old version. That's usually fine.
The Double Win
CDNs give you two benefits at once: lower latency and reduced load on your servers. Users get faster responses because data is nearby. Your backend handles fewer requests because the CDN absorbs the popular ones. This is why CDNs are almost always worth mentioning in design interviews for any read-heavy, globally-accessed system.
The Hidden Cost: Cache Invalidation
There's a famous saying in computer science: "There are only two hard things: cache invalidation and naming things." CDNs make this problem very real.
When you update a product price on your origin server, every edge location around the world might still be serving the old price until their cache expires. You have a few options:
- Short TTLs — Set cache duration to 30 seconds instead of 5 minutes. You get fresher data but more requests hit your origin server, reducing the CDN's benefit.
- Cache purging — Explicitly tell the CDN "forget this resource." Works, but purging across hundreds of edge locations takes time and isn't instant.
- Versioned URLs — Instead of
/styles.css, serve/styles.v42.css. When you update, change the URL. Old caches don't matter because nobody requests the old URL anymore. This is why you see hashed filenames in production builds.
For static assets (JS, CSS, images), versioned URLs are the gold standard. For dynamic API responses, you're stuck balancing TTLs against freshness. There's no perfect answer — and interviewers know that. Acknowledging the trade-off is more impressive than pretending CDNs are magic.
Regional Partitioning — When CDN Caching Isn't Enough
CDNs work for cached, read-heavy data. But what about data that's inherently tied to a specific place?
Think about Uber. When you open the app in Miami, you want drivers in Miami. You'll never book a ride with someone in Tokyo. The data itself has natural geographic boundaries — Miami riders only care about Miami drivers.
This is the insight behind regional partitioning: if the data is naturally local, keep it local.
How It Works
You split your infrastructure by geography:
- Group nearby cities into regions — "Southeast US" (server in Miami), "Northeast US" (server in New York), "Western Europe" (server in Frankfurt)
- Each region gets its own database — Containing only data for that region
- Servers live next to their data — Your compute and database sit in the same data center
- Users get routed to their nearest region — Via DNS or a global load balancer
Now when a Miami user wants nearby drivers, the request hits a Southeast US server, queries a local database, and returns. Everything stays within one building. Lightning fast.
Where It Fits
Regional partitioning works when data has natural geographic boundaries:
- Ride-sharing — Riders and drivers in the same city
- Food delivery — Restaurants and customers in the same area
- Local marketplaces — Buyers and sellers in the same region
It doesn't work when data is global. If a user in Tokyo needs to read something written by someone in London (like a global social feed), regional partitioning creates more headaches than it solves.
The Hidden Cost: Data Consistency Across Regions
Here's the headache nobody warns you about: what happens when data crosses regional boundaries?
Consider Uber again. A driver is registered in Miami. They drive to Atlanta for the weekend. Now the Southeast database has their registration, but the Atlanta region doesn't know they exist. You need some way to handle cross-region data:
- Sync on demand — When the driver opens the app in Atlanta, query the Miami region for their profile and cache it locally. Adds latency on first access but keeps things simple.
- Background replication — Continuously replicate driver profiles across all regions. You always have fresh data, but now you're maintaining multi-region database replication — one of the hardest problems in distributed systems.
- Central fallback — Keep a global database for data that might cross regions. Fast local reads for most cases, slower global reads for edge cases.
Each approach trades off latency, complexity, and consistency. In an interview, the strongest move is to acknowledge the problem upfront: "Regional partitioning works great for inherently local data, but we need a strategy for the 5% of data that crosses regions. Here's how I'd handle that..."
Interview Tip
CDNs are almost always the right first move for reducing global latency — they're simple and effective. Only reach for regional partitioning if the data is naturally geographic (ride-sharing, food delivery). A strong answer mentions both options and explains when each one applies: "For static content and cacheable API responses, I'd put a CDN in front. For the driver location data, since it's inherently regional, I'd partition by geography."