Fan-out
TL;DR
A user posts a message. How does it reach 100K channel members in under a second? That's the fan-out problem. Fan-out on write pushes to all subscribers immediately (fast reads, expensive writes). Fan-out on read fetches from sources at query time (cheap writes, slow reads). The winning strategy at scale is hybrid: fan-out on write for normal users, fan-out on read for high-follower entities, merged at query time. The pub/sub backbone decides your latency and durability tradeoffs.
The Core Problem
Someone hits "Send." Now what?
User A sends "hello" to #general
#general has 100,000 members
95,000 are currently connected via WebSocket
5,000 are offline (need push notification later)
This is fan-out: taking one event and delivering it to many recipients. The number of recipients is the fan-out factor, and it's the variable that determines whether your architecture works or melts.
Fan-Out on Write (Push Model)
The moment an event happens, you immediately push it to every subscriber's delivery mechanism — their WebSocket connection, their notification queue, their feed cache.
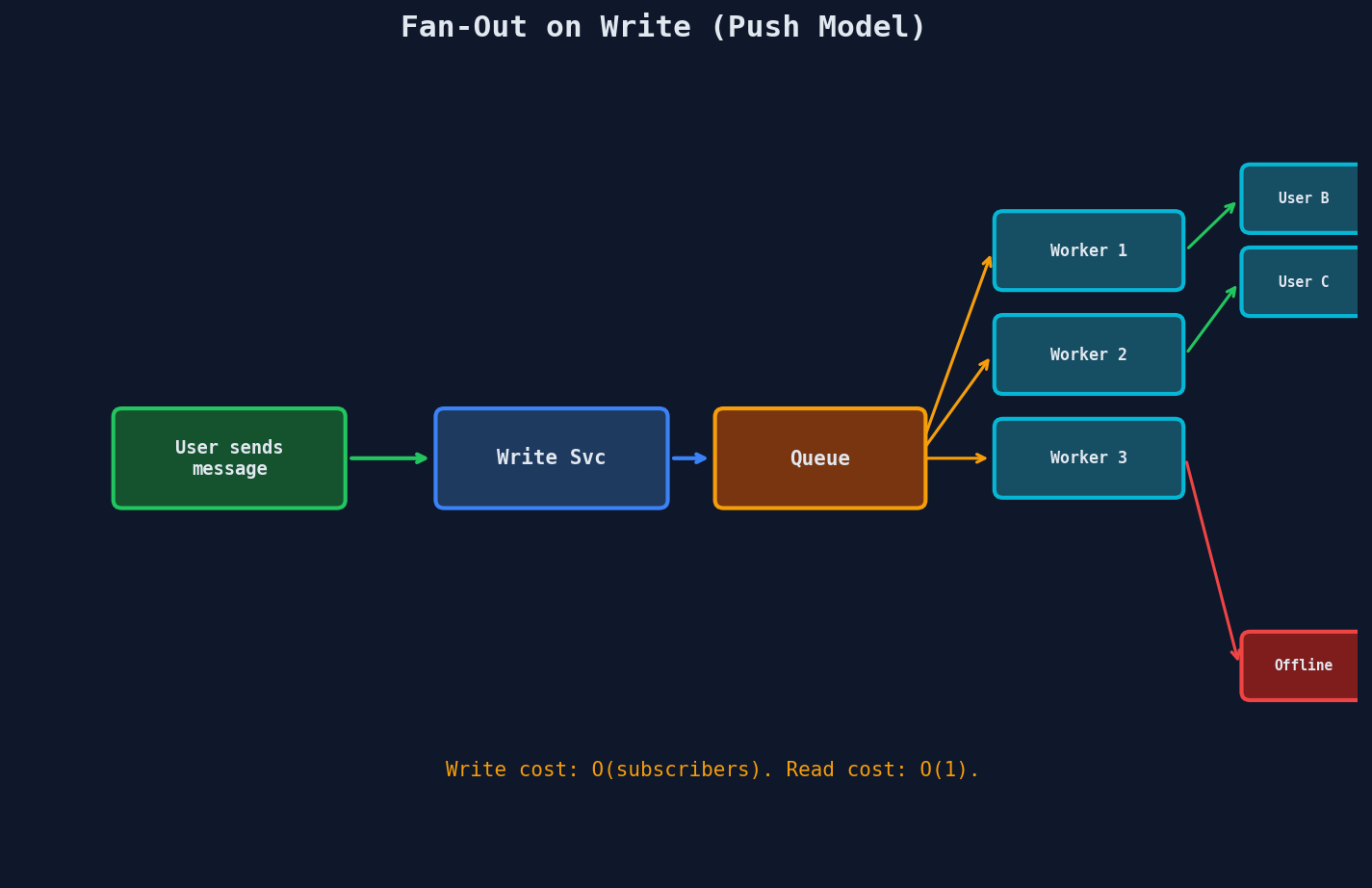
How It Works
- User A publishes a message
- Write service persists the message and enqueues a fan-out job
- Fan-out workers look up all subscribers of
#general - For each online subscriber: push to their WebSocket connection
- For each offline subscriber: enqueue a push notification
async def fan_out_on_write(message, channel_id):
# 1. Persist
await db.messages.insert(message)
# 2. Get all subscribers
subscribers = await db.subscriptions.find(channel_id=channel_id)
# 3. Fan out
for batch in chunked(subscribers, size=1000):
tasks = []
for sub in batch:
if connection_manager.is_online(sub.user_id):
tasks.append(
connection_manager.send(sub.user_id, message)
)
else:
tasks.append(
notification_queue.enqueue(sub.user_id, message)
)
await asyncio.gather(*tasks, return_exceptions=True)
Tradeoffs
| Advantage | Disadvantage |
|---|---|
| Read is instant — data is already in recipient's feed/connection | Write is expensive — 1 post to 100K followers = 100K operations |
| Predictable read latency — no fan-out at query time | Write amplification — storage multiplied by subscriber count |
| Simple client logic — data arrives, render it | Wasted work — many recipients may never read the message |
| Delivery is eager — recipients get updates immediately | Celebrity problem — one post from a 10M-follower account = 10M writes |
Fan-Out on Read (Pull Model)
Don't push anything at write time. When a user opens their feed, fetch from all sources and merge.
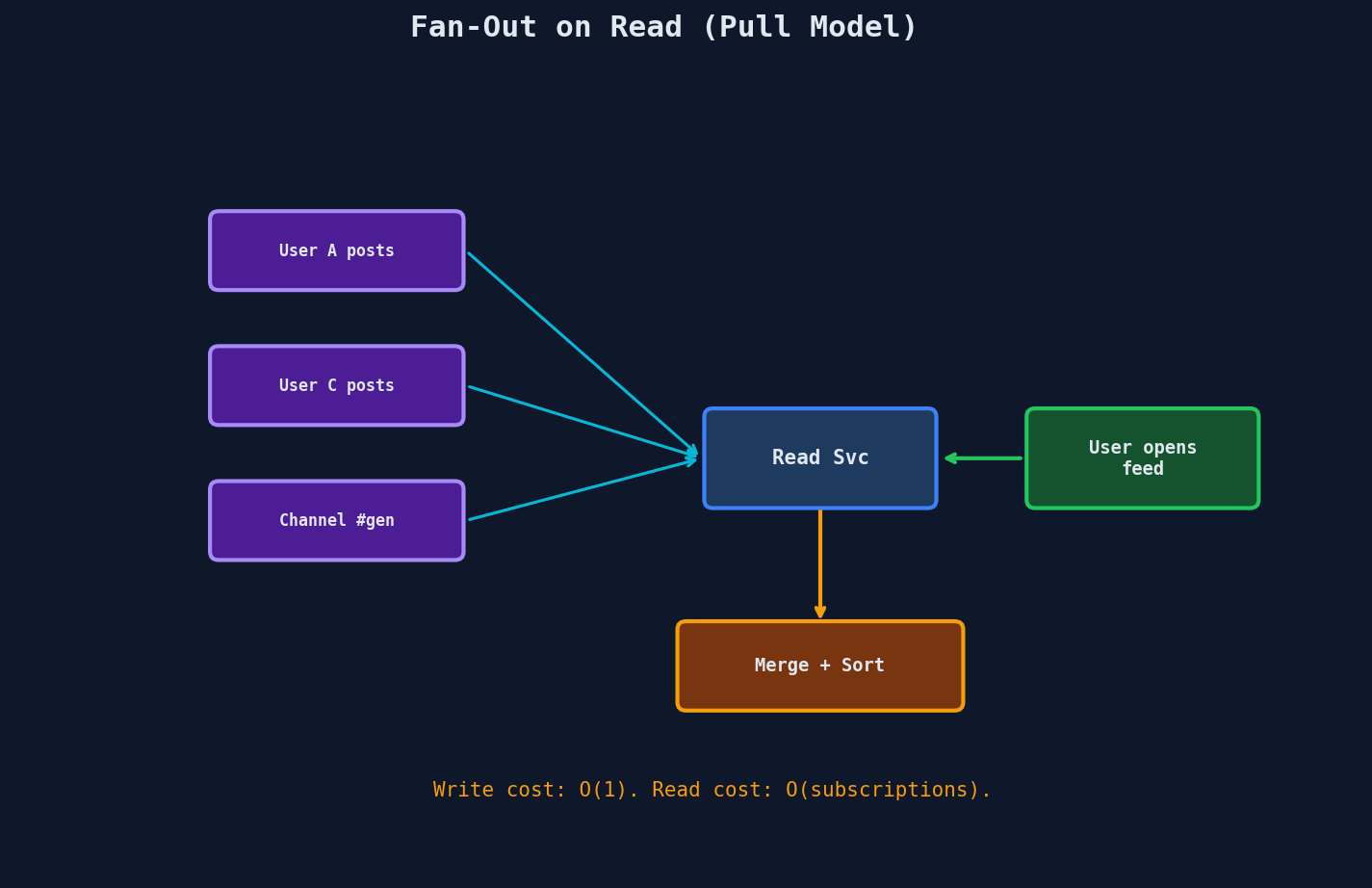
How It Works
- User B opens their feed
- Read service looks up all of B's subscriptions (users, channels, topics)
- Fetches recent posts from each source
- Merges and sorts by timestamp
- Returns the combined feed
async def fan_out_on_read(user_id, limit=50):
# 1. Get all sources this user follows
subscriptions = await db.subscriptions.find(user_id=user_id)
# 2. Fetch recent posts from each source
tasks = [
db.posts.find(
author_id=sub.source_id,
limit=limit,
order_by='created_at DESC'
)
for sub in subscriptions
]
results = await asyncio.gather(*tasks)
# 3. Merge and sort
all_posts = sorted(
chain.from_iterable(results),
key=lambda p: p.created_at,
reverse=True
)
return all_posts[:limit]
Tradeoffs
| Advantage | Disadvantage |
|---|---|
| Write is trivial — just persist the post, done | Read is expensive — N subscriptions = N queries at read time |
| No wasted work — only compute feeds for active users | Read latency is unpredictable — depends on subscription count |
| No celebrity problem — a 10M-follower post is still 1 write | Complex merge logic — sorting across N sources, pagination is hard |
| Fresh data guaranteed — always reading from source of truth | Cache invalidation nightmare — any source update invalidates the merged feed |
Hybrid Fan-Out — The Production Answer
The insight: most users have a manageable follower count. Only a tiny fraction have millions. Treat them differently.
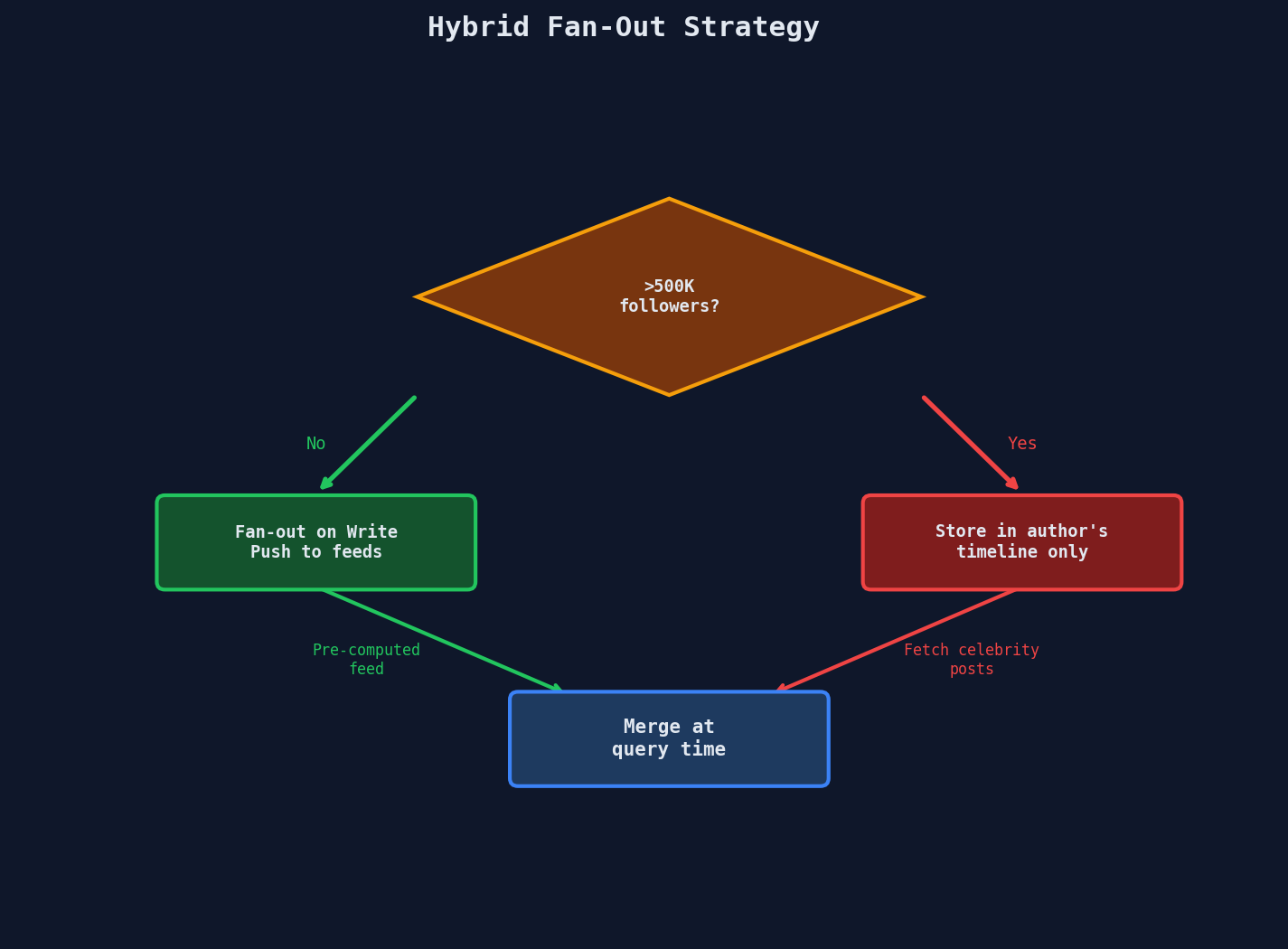
The Algorithm
CELEBRITY_THRESHOLD = 500_000 # follower count
async def publish_post(post, author):
await db.posts.insert(post)
if author.follower_count < CELEBRITY_THRESHOLD:
# Normal user: fan-out on write
followers = await db.followers.find(author_id=author.id)
for batch in chunked(followers, 1000):
await fan_out_to_feeds(post, batch)
else:
# Celebrity: just store it, fans pull at read time
await db.celebrity_posts.insert(post)
async def get_feed(user_id):
# 1. Get pre-computed feed (from fan-out on write)
feed = await cache.get_feed(user_id, limit=200)
# 2. Get celebrity posts (fan-out on read)
celeb_follows = await db.follows.find(
user_id=user_id, is_celebrity=True
)
celeb_posts = await fetch_recent_from(celeb_follows)
# 3. Merge and sort
combined = sorted(
feed + celeb_posts,
key=lambda p: p.created_at,
reverse=True
)
return combined[:50]
Twitter's (now X's) early feed architecture famously struggled with the "celebrity problem" — a single tweet from an account with millions of followers would generate millions of fan-out writes, causing feed delivery delays across the platform. The hybrid approach solved this by pulling celebrity tweets at read time and only fanning out tweets from accounts with manageable follower counts.
Interview Tip
Always mention the hybrid approach. It shows you understand that the best architecture isn't one-size-fits-all. State the threshold (~500K is a good number to cite) and explain why it exists: below the threshold, the write cost is manageable and reads are instant; above it, the write cost dominates and the fan-out on read merge adds only a few extra queries.
Server-Side Pub/Sub — The Fan-Out Backbone
Fan-out workers need a messaging layer. Two dominant choices:
Redis Pub/Sub
# Publisher
redis.publish('channel:general', json.dumps(message))
# Subscriber (on each WebSocket gateway server)
pubsub = redis.pubsub()
pubsub.subscribe('channel:general')
for msg in pubsub.listen():
# Deliver to all WebSocket connections on this server
# that are subscribed to #general
for ws in local_connections['channel:general']:
await ws.send(msg['data'])
Kafka (Persistent Pub/Sub)
# Publisher
producer.send(
topic='messages',
key=channel_id.encode(), # partition by channel
value=json.dumps(message).encode()
)
# Consumer (on each gateway server)
consumer = KafkaConsumer(
'messages',
group_id='gateway-server-1',
auto_offset_reset='latest'
)
for record in consumer:
message = json.loads(record.value)
channel = record.key.decode()
for ws in local_connections[channel]:
await ws.send(record.value)
Redis vs Kafka Decision Table
| Criteria | Redis Pub/Sub | Kafka |
|---|---|---|
| Latency | ~0.1ms | ~5-50ms |
| Persistence | None (fire-and-forget) | Yes (configurable retention) |
| Ordering | No guarantees | Per-partition ordering |
| Missed messages | Lost if subscriber is down | Replay from any offset |
| Throughput | ~1M msg/s (single node) | ~1M msg/s (per partition, scales horizontally) |
| Memory | Only current subscribers' state | Stores all messages for retention period |
| Use case | Real-time ephemeral delivery | Event sourcing, audit trails, replay needed |
Redis Pub/Sub Is Not a Queue
If a subscriber is disconnected when a message is published, that message is gone forever. Redis Pub/Sub has no replay, no acknowledgment, no persistence. If you need guaranteed delivery, use Redis Streams or Kafka. Pub/Sub is for "best effort, real-time" delivery to currently-connected servers.
Putting It All Together
Here's the full fan-out pipeline for a chat system:
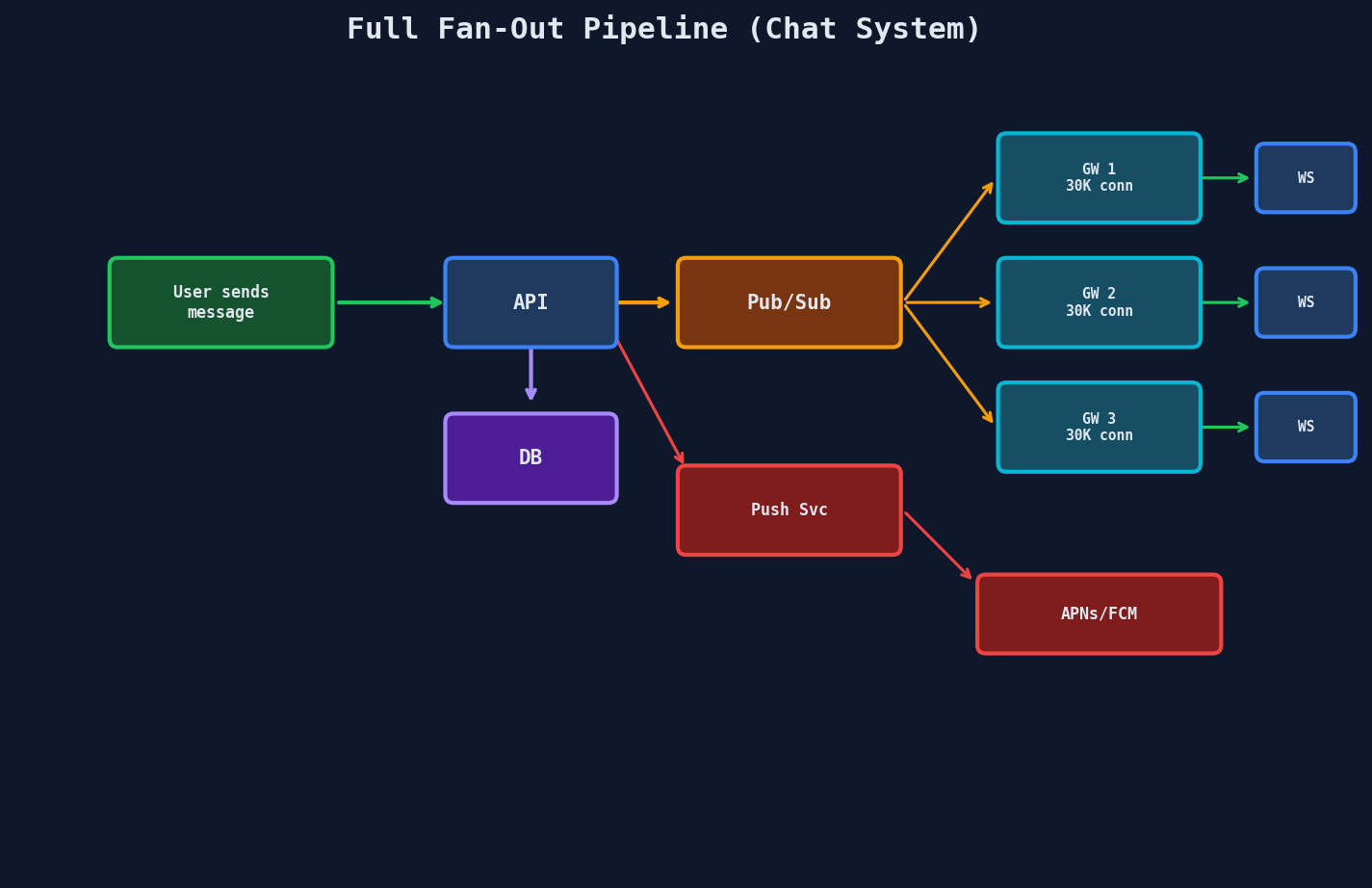
- API server receives the message, persists it, publishes to pub/sub
- Every gateway server subscribed to that channel's topic receives the message
- Each gateway delivers to its local WebSocket connections for that channel
- Offline users get a push notification through a separate pipeline
Discord handles over 10 million messages per second across its guild system using this pattern, with each gateway server managing up to 100K WebSocket connections and a pub/sub layer coordinating delivery across the fleet.
Key Takeaways
| Strategy | Write Cost | Read Cost | Best For |
|---|---|---|---|
| Fan-out on write | O(subscribers) | O(1) | Small-medium follower counts, latency-sensitive |
| Fan-out on read | O(1) | O(subscriptions) | Celebrity accounts, infrequently-read feeds |
| Hybrid | Varies | O(celebrity_follows) | Production social/feed systems at scale |
| Pub/Sub | Choose When |
|---|---|
| Redis Pub/Sub | Real-time delivery, no replay needed, sub-millisecond latency |
| Kafka | Need persistence, replay, ordering, audit trail |
| Redis Streams | Middle ground — persistence + low latency, simpler than Kafka |