LCA via Postorder
Don't Memorize It — Derive It
The Lowest Common Ancestor (LCA) of two nodes \(p\) and \(q\) is the deepest node that is an ancestor of both. It shows up constantly in interviews, and most people memorize the code without understanding why it works.
You don't need to memorize anything. LCA falls directly out of the postorder template. Once you see how, you won't forget it.
The Problem (LC 236)
Problem: Given a binary tree and two nodes \(p\) and \(q\) (guaranteed to exist in the tree), find their lowest common ancestor.
LCA of 6 and 4 is 5. Node 5 is the deepest node that has both 6 and 4 as descendants.
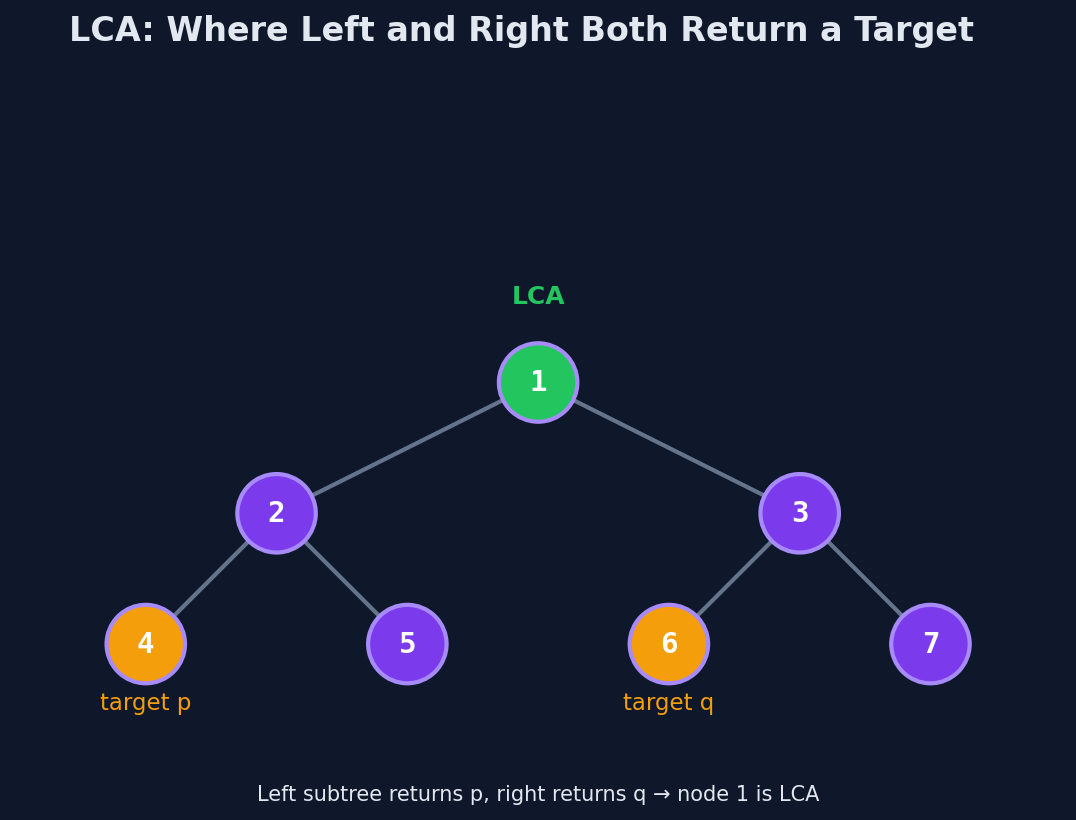
LCA of 5 and 1 is 3. The only node that is an ancestor of both 5 and 1 is the root.
LCA of 5 and 4 is 5. A node can be its own ancestor.
Deriving the Algorithm
Think about what you know at each node during a postorder traversal. You've already processed the left subtree and the right subtree. You have their results. What result should you propagate?
You're searching for \(p\) and \(q\). At each node, there are exactly four possibilities:
-
Left subtree found one target, right subtree found the other. This node is where the search splits. This node IS the LCA.
-
Only the left subtree found something. The target(s) are all on the left. Propagate the left result upward.
-
Only the right subtree found something. Propagate the right result upward.
-
Neither subtree found anything. This subtree doesn't contain \(p\) or \(q\). Return
nullptr.
There's one more case: this node itself is \(p\) or \(q\). Return it immediately — the other target is either in your subtree (and you're the LCA) or somewhere else (and your ancestor will combine the results).
LCA is the first node where the search splits. Postorder naturally finds this because it processes children before the parent — by the time you reach a node, you already know which side each target is on.
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (!root || root == p || root == q) return root;
TreeNode* leftResult = lowestCommonAncestor(root->left, p, q);
TreeNode* rightResult = lowestCommonAncestor(root->right, p, q);
if (leftResult && rightResult) return root;
return leftResult ? leftResult : rightResult;
}
That's the entire algorithm. Six lines. No auxiliary data structures. \(O(n)\) time, \(O(h)\) space.
Trace 1: LCA of Two Leaf Nodes
Find LCA of \(p = 6\) and \(q = 4\).
| Call | Node | Is p or q? | leftResult | rightResult | Both non-null? | Returns |
|---|---|---|---|---|---|---|
| lca(7) | 7 | No | nullptr | nullptr | No | nullptr |
| lca(4) | 4 | Yes (q) | — | — | — | 4 |
| lca(2) | 2 | No | nullptr (from 7) | 4 (from 4) | No | 4 |
| lca(6) | 6 | Yes (p) | — | — | — | 6 |
| lca(5) | 5 | No | 6 (from 6) | 4 (from 2) | Yes | 5 |
| lca(0) | 0 | No | nullptr | nullptr | No | nullptr |
| lca(8) | 8 | No | nullptr | nullptr | No | nullptr |
| lca(1) | 1 | No | nullptr (from 0) | nullptr (from 8) | No | nullptr |
| lca(3) | 3 | No | 5 (from 5) | nullptr (from 1) | No | 5 |
Node 5 is the first node where both sides return non-null. It returns itself. Every ancestor above it just propagates 5 upward. The answer is 5.
Walk through it: node 6 is found on the left side of node 5. Node 4 is found on the right side of node 5 (through node 2). Node 5 is where the search splits. That's the LCA.
Trace 2: One Node is an Ancestor of the Other
Find LCA of \(p = 5\) and \(q = 4\).
| Call | Node | Is p or q? | leftResult | rightResult | Both non-null? | Returns |
|---|---|---|---|---|---|---|
| lca(7) | 7 | No | nullptr | nullptr | No | nullptr |
| lca(4) | 4 | Yes (q) | — | — | — | 4 |
| lca(2) | 2 | No | nullptr | 4 | No | 4 |
| lca(6) | 6 | No | nullptr | nullptr | No | nullptr |
| lca(5) | 5 | Yes (p) | — | — | — | 5 |
Node 5 matches \(p\), so it returns itself immediately — before even checking whether 4 is in its subtree. This works because \(p = 5\) is guaranteed to exist, and \(q = 4\) is in \(p\)'s subtree, making \(p\) the LCA.
The key: when root == p, we return root without recursing further. The ancestor that called us will see a non-null result from this side and nullptr from the other, so it propagates our result up. The LCA is correctly identified as 5.
Edge Case: p or q is the Root
Find LCA of \(p = 3\) and \(q = 4\).
The very first call hits root == p, so it returns 3 immediately. No recursion at all. The LCA is the root itself.
This is correct: the root is an ancestor of every node, so LCA(root, anything) = root.
LCA II: Nodes May Be Missing (LC 1644)
The standard LCA assumes both \(p\) and \(q\) exist in the tree. LC 1644 removes that guarantee: one or both might be missing. If either is missing, return nullptr.
The problem with the standard algorithm: when root == p, we return immediately. But what if \(q\) doesn't exist? We'd still return \(p\), incorrectly reporting it as the LCA.
The fix: don't short-circuit when you find \(p\) or \(q\). Always recurse into both subtrees. Count how many of \(p\) and \(q\) you actually found. Only return the LCA if you found both.
TreeNode* findLCA(TreeNode* root, TreeNode* p, TreeNode* q, int& foundCount) {
if (!root) return nullptr;
TreeNode* leftResult = findLCA(root->left, p, q, foundCount);
TreeNode* rightResult = findLCA(root->right, p, q, foundCount);
if (root == p || root == q) {
foundCount++;
return root;
}
if (leftResult && rightResult) return root;
return leftResult ? leftResult : rightResult;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
int foundCount = 0;
TreeNode* candidate = findLCA(root, p, q, foundCount);
return foundCount == 2 ? candidate : nullptr;
}
Notice the order: we recurse FIRST, then check if the current node is \(p\) or \(q\). This ensures we search the entire tree even when one target is an ancestor of the other.
Why does this matter? In the standard version, when we hit \(p = 5\), we return immediately without searching for \(q\) in 5's subtree. That's fine when both are guaranteed to exist. But if \(q\) might not exist, we need to actually find it (or confirm it's missing) before reporting an answer.
Complexity: \(O(n)\) time, \(O(h)\) space — same as standard LCA.
Why Postorder is the Natural Fit
You could solve LCA with other approaches: store paths from root to \(p\) and root to \(q\), then find the last common node. That's \(O(n)\) time and \(O(n)\) space for the paths.
The postorder solution uses only \(O(h)\) space (the recursion stack). And it's conceptually cleaner: you're not building paths and comparing them. You're asking each node a simple question: "Are my targets on different sides?" The first node to answer yes is the LCA.
Postorder gives you complete information about both subtrees before you process the current node. That's exactly what LCA needs: you must know where both targets are before you can decide if this node is the meeting point.
This is the same principle behind every postorder problem. Diameter: you need both heights before computing the path through this node. Max path sum: you need both gains before computing the arch. LCA: you need both search results before deciding if this is the split point.
Try It
The starter code has lowestCommonAncestor with a TODO. Implement it for the case where both nodes are guaranteed to exist.
Predict before running: What does the function return when \(p\) and \(q\) are the same node? Trace through: root == p, return root. The caller sees one non-null result. It propagates up. The answer is the node itself, which is correct — a node is its own ancestor.
Challenge: Modify the algorithm for a BST (Binary Search Tree). In a BST, you can determine which subtree to search based on the values of \(p\) and \(q\). If both are less than the current node, go left. If both are greater, go right. If they split, this node is the LCA. No postorder needed — this is a top-down algorithm. Why does BST structure allow this shortcut?
Challenge 2: Solve LC 1644 (LCA II). The key change: don't return early when you find a target. Recurse fully, count findings, and only report the LCA if both targets were found.
Edge Cases to Watch For
- Nodes may not exist (LC 1644): The standard algorithm short-circuits on
root == p, which means it never verifies that \(q\) actually exists. For LC 1644, you MUST remove the early return, recurse fully, and count how many targets were found. Return the LCA only iffoundCount == 2.
Problems
| Problem | Link | Difficulty |
|---|---|---|
| LC 236 — Lowest Common Ancestor of a Binary Tree | leetcode.com/problems/lowest-common-ancestor-of-a-binary-tree | Medium |
| LC 1644 — Lowest Common Ancestor of a Binary Tree II | leetcode.com/problems/lowest-common-ancestor-of-a-binary-tree-ii | Medium |
| LC 235 — Lowest Common Ancestor of a BST | leetcode.com/problems/lowest-common-ancestor-of-a-binary-search-tree | Medium |
| LC 250 — Count Univalue Subtrees | leetcode.com/problems/count-univalue-subtrees | Medium |
| LC 366 — Find Leaves of Binary Tree | leetcode.com/problems/find-leaves-of-binary-tree | Medium |
| LC 572 — Subtree of Another Tree | leetcode.com/problems/subtree-of-another-tree | Easy |
What's Next?
Bottom-up handles everything below you. But some problems need information flowing downward — the accumulated path from root, coordinate positions, distance from a target. Chapter 4 teaches top-down thinking.