Replication Models
TL;DR
Replication copies your data to multiple machines for fault tolerance and read scaling. Leader-follower is the default — one node accepts writes, followers serve reads. Multi-leader handles multi-region writes. Leaderless (Dynamo-style) lets any node accept writes using quorum math. Each model trades off between consistency, availability, and complexity.
Why Replication Matters
A single database server is a single point of failure. The hard drive dies, you lose everything. The server gets overloaded, every user waits. The datacenter goes offline, your app is down.
Replication solves this by keeping copies of your data on multiple machines. But how you replicate determines everything about your system's consistency, availability, and performance. Get it wrong, and you either serve stale data or can't serve at all.
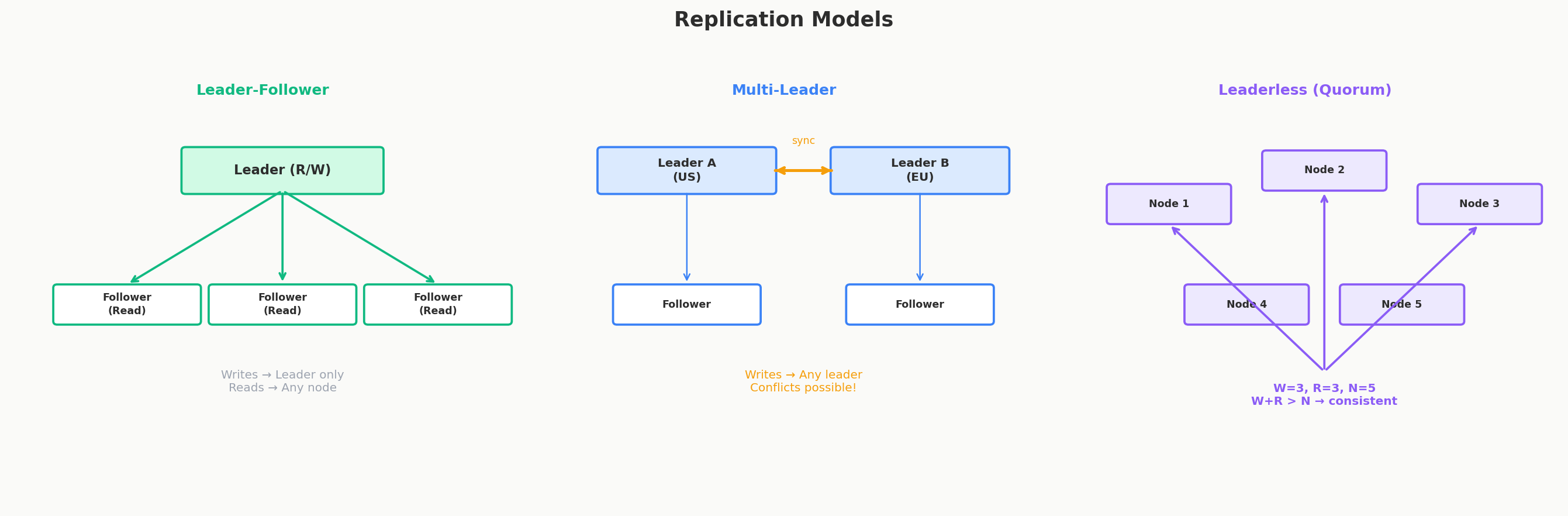
Leader-Follower Replication (The Default)
The most common replication model, used by PostgreSQL, MySQL, MongoDB, and Redis.
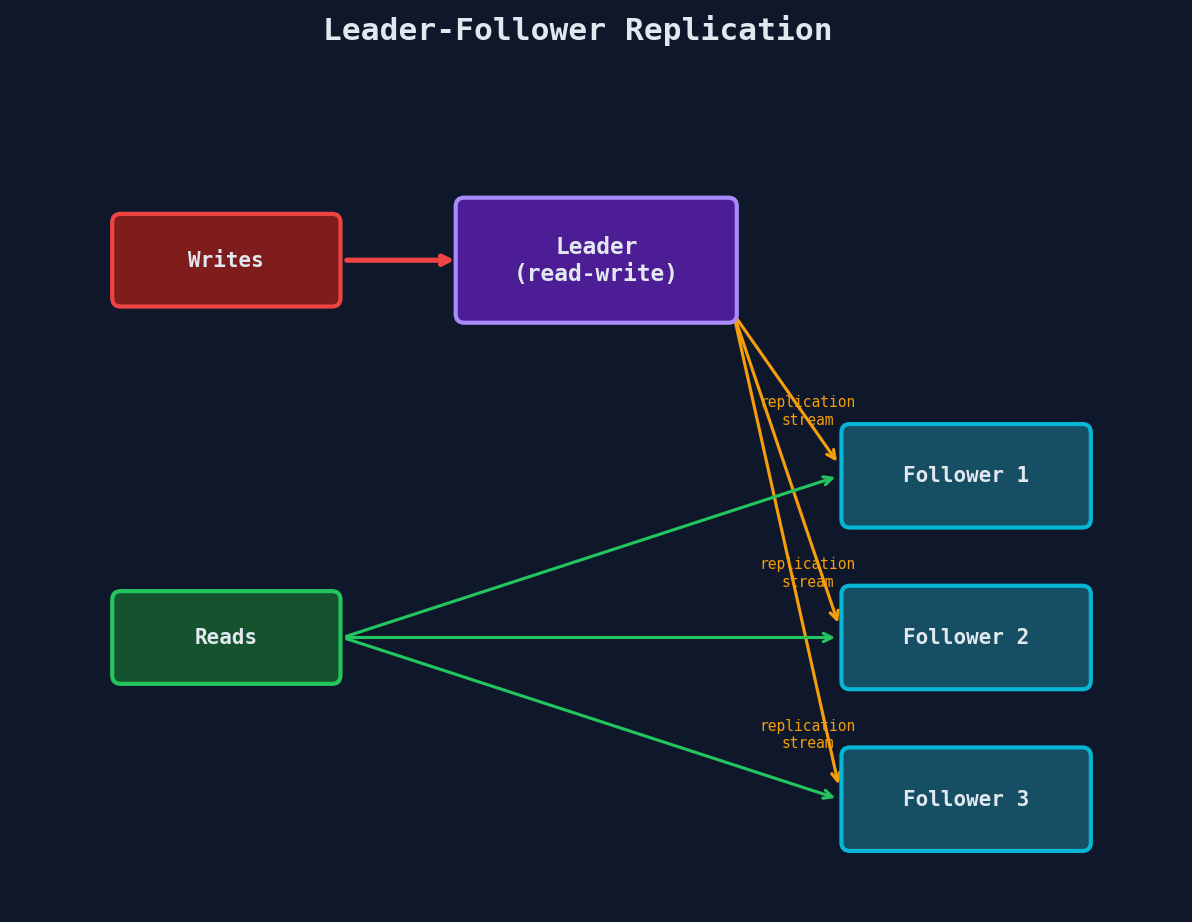
How it works: 1. One node is the leader (also called primary or master). All writes go through it. 2. The leader sends every write to all followers (replicas) via a replication log. 3. Clients can read from any follower (for read scaling) or from the leader (for consistency).
Synchronous vs asynchronous replication:
| Mode | Behavior | Trade-off |
|---|---|---|
| Synchronous | Leader waits for follower to confirm before acknowledging write | Follower always up-to-date, but one slow follower blocks all writes |
| Asynchronous | Leader acknowledges write immediately, follower catches up later | Fast writes, but follower may serve stale data |
| Semi-synchronous | One follower is sync, rest are async | Practical middle ground — most databases use this |
In practice, fully synchronous replication is too slow. Most systems use semi-synchronous (one sync follower for durability guarantee, rest async for speed).
Replication Lag
With async replication, followers lag behind the leader. A write that just committed on the leader might not be visible on a follower for milliseconds to seconds.
This creates three problems:
Read-after-write inconsistency: Alice updates her profile on the leader, then reads from a follower that hasn't caught up yet — she sees her old profile.
Fix: Route a user's reads to the leader for a few seconds after they write. Or track the user's latest write timestamp and only read from followers that are caught up past that point.
Monotonic read violations: Bob reads his feed from Follower A (sees 10 posts), then reads from Follower B (which is further behind — sees only 8 posts). Posts disappeared!
Fix: Pin each user's reads to the same follower (using a hash of user ID).
Causal ordering violations: Carol posts "Is anyone hiring?", Dave replies "Yes, we are!" — but a follower shows Dave's reply before Carol's post because the writes arrived out of order.
Fix: Use causal consistency mechanisms or ensure causally related writes go through the same replication path.
Failover
When the leader dies, a follower must be promoted. This is called failover.
- Detect that the leader has failed (usually via timeout)
- Elect a new leader (typically the most up-to-date follower)
- Reconfigure clients to send writes to the new leader
Dangers: - The new leader may not have all the old leader's latest writes (data loss) - If the old leader comes back, it thinks it's still the leader (split brain — two nodes accepting writes simultaneously) - Misconfigured timeouts can trigger unnecessary failovers under load
Interview Tip
When you mention read replicas in an interview, always acknowledge replication lag: "Reads go to replicas for scaling, but there's replication lag. For the user's own writes, I'd route their reads to the primary for a few seconds to ensure read-after-write consistency."
Multi-Leader Replication
Each datacenter has its own leader. Used when you need writes in multiple geographic regions.
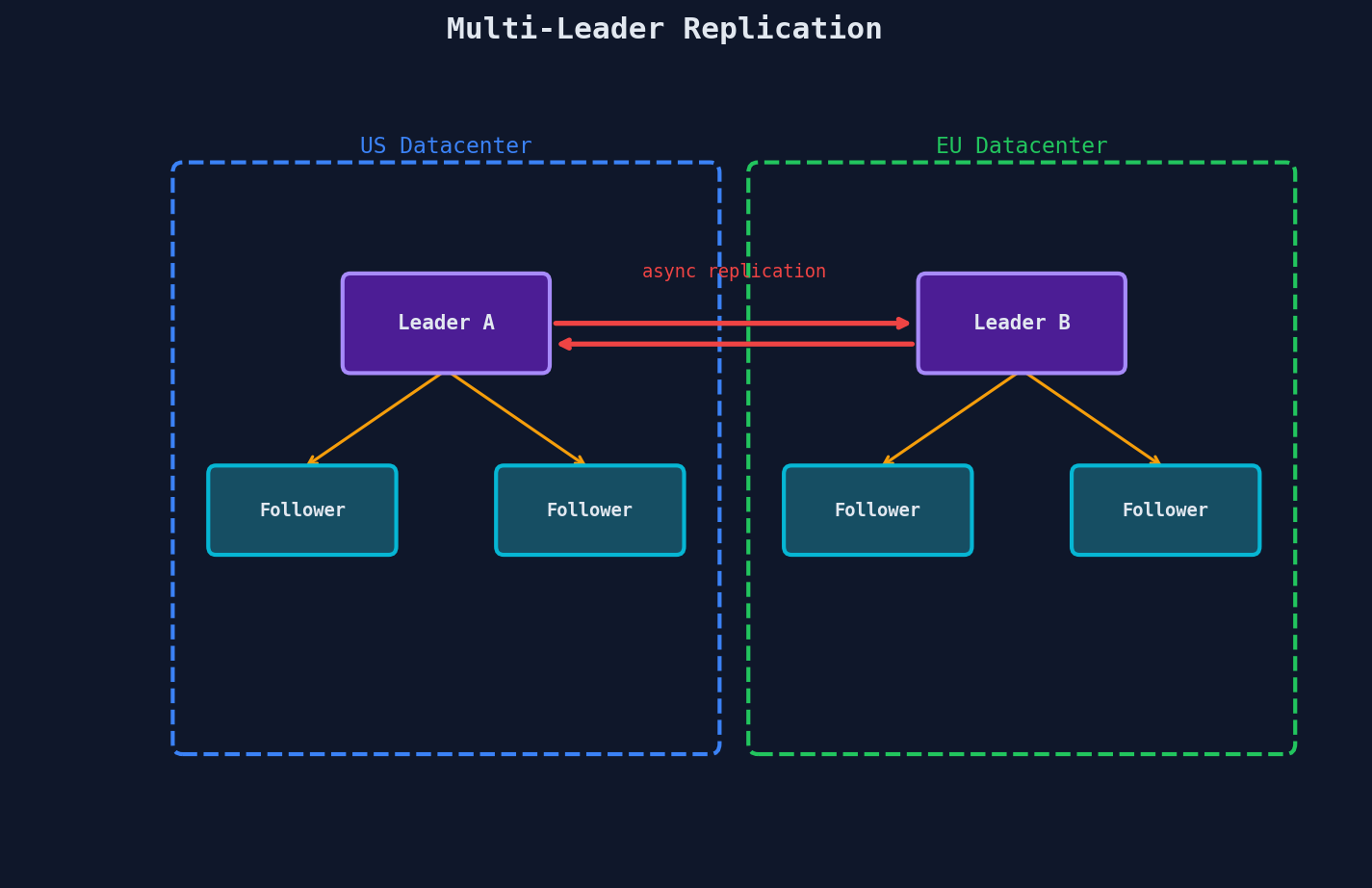
When it makes sense: - Multi-region deployments where users need low-latency writes from their local region - Offline-first apps (each device acts as a leader, syncs when reconnected) - Collaborative editing (Google Docs — each user's local state is a "leader")
The problem: write conflicts. If User A in the US edits a document and User B in the EU edits the same document simultaneously, both leaders accept the write. Now the two leaders have conflicting versions.
Conflict resolution strategies: - Last write wins (LWW): Use timestamps, higher timestamp wins. Simple but loses data. - Merge values: Keep both versions and let the application merge them (like Git merge) - Custom resolution: Application-specific logic (e.g., shopping cart merges by union of items)
Multi-leader replication is complex and error-prone. As DDIA author Martin Kleppmann writes: "Multi-leader replication is considered dangerous territory and should be avoided if possible."
Leaderless Replication (Dynamo-Style)
No designated leader. Any node can accept reads and writes. Used by DynamoDB, Cassandra, Riak, and Voldemort.
async def quorum_read(key, nodes, R=2):
"""Read from R nodes, return the newest version."""
responses = await asyncio.gather(*[node.get(key) for node in nodes])
successful = [r for r in responses if r is not None]
if len(successful) < R:
raise Exception("Not enough nodes responded")
return max(successful, key=lambda r: r.version) # newest wins
async def quorum_write(key, value, nodes, W=2):
"""Write to W nodes before acknowledging."""
acks = await asyncio.gather(*[node.put(key, value) for node in nodes])
if sum(acks) < W:
raise Exception("Write quorum not met")
Quorum Reads and Writes
The client writes to W nodes and reads from R nodes out of a total of N replicas. As long as:
...at least one node in the read set will have the latest write, guaranteeing the client sees up-to-date data.
Example with N=3:
| W | R | Guarantee | Trade-off |
|---|---|---|---|
| 2 | 2 | W+R=4 > 3 — consistent reads | Balanced |
| 3 | 1 | W+R=4 > 3 — consistent reads | Writes slow (wait for all), reads fast |
| 1 | 3 | W+R=4 > 3 — consistent reads | Writes fast, reads slow |
| 1 | 1 | W+R=2 < 3 — may read stale | Fast but no consistency guarantee |
Common configuration: W=2, R=2, N=3. This tolerates one node failure for both reads and writes.
Sloppy Quorums and Hinted Handoff
Strict quorums require W nodes from the designated set. But what if one of those nodes is temporarily down?
A sloppy quorum allows writes to go to any W available nodes, even if they're not the designated replicas. The write is temporarily stored on a substitute node, and when the original node recovers, the data is handed off back to it. This is called hinted handoff.
DynamoDB and Riak use sloppy quorums to improve write availability — you can always write as long as some W nodes are reachable, even if they're not the "right" ones.
Anti-Entropy and Read Repair
Leaderless systems use two mechanisms to keep replicas in sync:
Read repair: When a client reads from R nodes and notices one returned stale data, it writes the newer value back to the stale node.
Anti-entropy process: A background process continuously compares replicas and copies missing data. Unlike leader-based replication, this doesn't guarantee any particular order.
Comparison
| Model | Writes | Reads | Consistency | Complexity | Used By |
|---|---|---|---|---|---|
| Leader-follower | Leader only | Any node | Strong (from leader), eventual (from followers) | Low | PostgreSQL, MySQL, MongoDB, Redis |
| Multi-leader | Any leader | Any node | Eventual (conflict resolution needed) | High | CockroachDB (internally), Google Docs |
| Leaderless | Any node (quorum) | Any node (quorum) | Tunable (W+R>N for strong) | Medium | DynamoDB, Cassandra, Riak |
Quick Recap
| Concept | What It Solves | Watch Out For |
|---|---|---|
| Leader-follower | Read scaling, fault tolerance | Replication lag, failover complexity |
| Replication lag | N/A (it's a problem) | Read-after-write, monotonic reads, causal ordering |
| Multi-leader | Multi-region low-latency writes | Write conflicts are hard to resolve |
| Leaderless / quorum | High write availability, no SPOF | Stale reads if W+R≤N, sloppy quorums weaken guarantees |
| Hinted handoff | Write availability during node failures | Data temporarily on wrong nodes |
Interview Tip
When designing a system with multiple datacenters, say: "I'd use leader-follower replication within each datacenter. For cross-datacenter sync, I'd use async replication to avoid cross-region latency on writes, accepting eventual consistency between regions. If the system needs multi-region writes, I'd consider a leaderless model with quorum reads and writes."