Huffman Coding
The Problem
You are given \(N\) symbols, each with a frequency \(f_i\). Your task is to assign a binary prefix-free code to each symbol — meaning no codeword is a prefix of another — such that the total weighted path length is minimized:
where \(\text{depth}_i\) is the length (in bits) of the codeword assigned to symbol \(i\).
A prefix-free code corresponds to a binary tree: each symbol is a leaf, and its codeword is the root-to-leaf path (left = 0, right = 1). Minimizing the weighted path length means frequent symbols get short codes and rare symbols get long codes.
The Greedy Choice: Always merge the two symbols (or subtrees) with the smallest frequencies. The rarest symbols should live deepest in the tree, so they should be paired first.
Why Brute Force Fails
You might think: merge the two largest frequencies first, since they're the most "important." This is backwards. Merging two large nodes pushes them deeper in the tree, and depth multiplied by a large frequency is expensive. For frequencies \([2, 3, 10, 50]\), merging \(10 + 50 = 60\) first forces both into depth 2 or more, costing at least \(10 \times 2 + 50 \times 2 = 120\) for those two symbols alone. Merging \(2 + 3 = 5\) first puts the cheapest symbols deep, costing only \(2 \times 3 + 3 \times 3 = 15\). The naive "biggest first" strategy minimizes the wrong quantity.
Why Merge the Two Smallest?
Think about it from the tree's perspective. Every internal node represents a merge. When you merge two nodes with frequencies \(a\) and \(b\), you create a parent with frequency \(a + b\). That parent sits one level higher — meaning both \(a\) and \(b\) just got pushed one level deeper.
If you're going to push two things deeper, push the lightest ones. Pushing a heavy node deeper costs more because its frequency multiplies its depth. The two smallest frequencies contribute the least additional cost when placed at maximum depth.
Consider a concrete comparison. Suppose you have frequencies \([2, 3, 10, 50]\). If you merge \(2 + 3 = 5\) first, you push the two lightest nodes deeper. If instead you merged \(10 + 50 = 60\) first, you'd push the two heaviest nodes deeper — paying far more. The greedy insight is that depth is expensive, so cheap symbols should absorb it.
The algorithm:
- Insert all \(N\) frequencies into a min-heap.
- While the heap has more than one element: extract the two smallest, merge them (sum their frequencies), push the result back.
- The sum of all merge costs is the minimum weighted path length.
Full Trace: Frequencies [5, 9, 12, 13, 16, 45]
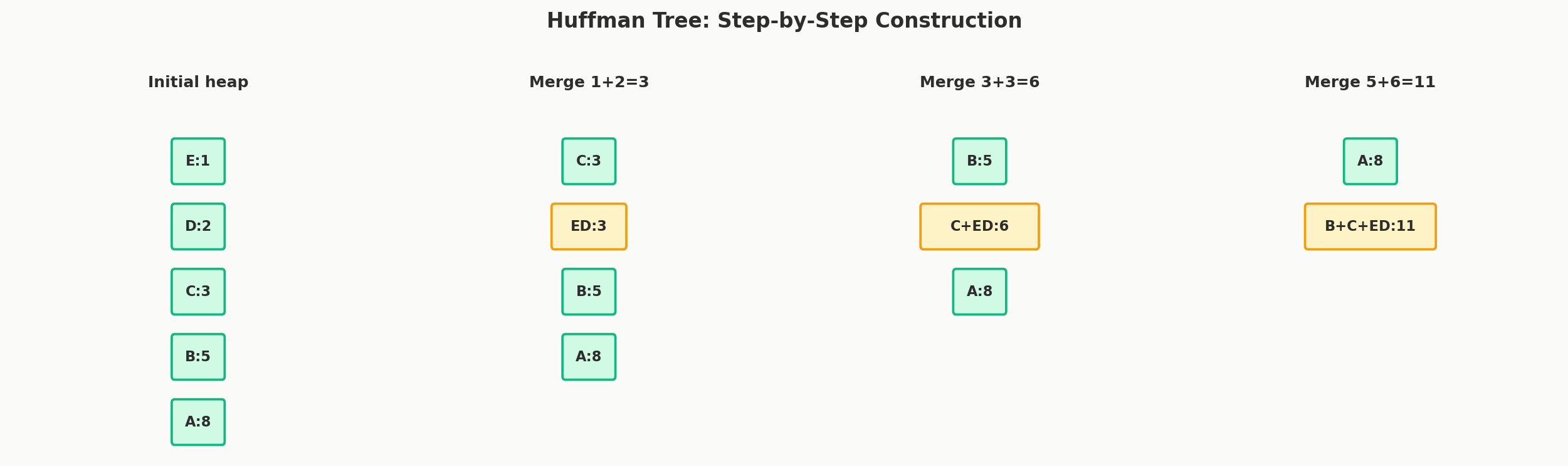
Let's build the Huffman tree step by step. At each step, we extract the two smallest elements from the min-heap, merge them, and push the result back.
| Step | Heap Before Merge | Smallest | Second Smallest | Merged | Heap After Merge |
|---|---|---|---|---|---|
| 1 | [5, 9, 12, 13, 16, 45] | 5 | 9 | 14 | [12, 13, 14, 16, 45] |
| 2 | [12, 13, 14, 16, 45] | 12 | 13 | 25 | [14, 16, 25, 45] |
| 3 | [14, 16, 25, 45] | 14 | 16 | 30 | [25, 30, 45] |
| 4 | [25, 30, 45] | 25 | 30 | 55 | [45, 55] |
| 5 | [45, 55] | 45 | 55 | 100 | [100] |
The total merge cost is \(14 + 25 + 30 + 55 + 100 = 224\).
The Resulting Tree
Leaves are shown in parentheses. Internal nodes are in brackets. Reading off the depths:
| Symbol | Frequency \(f_i\) | Depth | Code (one possible assignment) |
|---|---|---|---|
| 45 | 45 | 1 | 1 |
| 12 | 12 | 3 | 010 |
| 13 | 13 | 3 | 011 |
| 16 | 16 | 3 | 001 |
| 5 | 5 | 4 | 0000 |
| 9 | 9 | 4 | 0001 |
Verification
Compute the weighted path length directly from the table:
This matches the total merge cost of \(224\). That's not a coincidence — it always holds.
Why the merge cost equals the weighted path length: Each time you merge two nodes with frequencies \(a\) and \(b\), you add \(a + b\) to the running cost. But merging also increases the depth of every leaf under \(a\) and \(b\) by exactly 1. So the merge cost \(a + b\) accounts for exactly the additional \(\sum f_i \times 1\) contributed by pushing those leaves one level deeper. Summing over all merges gives \(\sum f_i \times \text{depth}_i\).
This equivalence is why Huffman problems in competitive programming never ask you to actually build the tree. You just need the total merge cost — which is the single number the min-heap loop computes.
Proof by Exchange Argument
Claim: In an optimal prefix-free code, the two symbols with the smallest frequencies must be siblings at maximum depth.
Proof: Suppose for contradiction that an optimal tree \(T^*\) has two smallest-frequency symbols \(x\) and \(y\) that are not siblings at maximum depth. Let \(a\) and \(b\) be two siblings at maximum depth \(d\) in \(T^*\).
Since \(x\) and \(y\) have the smallest frequencies, \(f_x \leq f_a\) and \(f_y \leq f_b\). Now swap \(x\) with \(a\) (so \(x\) moves to depth \(d\) and \(a\) moves to \(x\)'s original depth \(d_x\)). The change in cost is:
Since \(f_x \leq f_a\) and \(d \geq d_x\) (because \(d\) is the maximum depth), we have \(\Delta \leq 0\). The cost doesn't increase. Similarly, swapping \(y\) with \(b\) doesn't increase cost.
After both swaps, \(x\) and \(y\) are siblings at maximum depth, and the cost is at most the original. Since \(T^*\) was optimal, this new tree is also optimal — and it has \(x, y\) as siblings at maximum depth.
Therefore, the greedy choice of merging the two smallest is safe. By induction on the number of symbols (after merging, we have \(N-1\) symbols and the subproblem is identical), the entire Huffman algorithm produces an optimal tree.
Connection to CSES Stick Divisions
The CSES problem Stick Divisions asks: given a stick of length \(L\) that must be divided into pieces of specified lengths, find the minimum total cost, where each cut costs the length of the stick being cut.
This is Huffman coding in reverse. Instead of merging small pieces into larger ones, you're splitting a large piece into smaller ones. But the cost structure is identical — every merge (or split) costs the sum of the two parts.
So the solution is the same: build a Huffman tree from the piece lengths. The total merge cost equals the minimum total cutting cost. If you think about it, each cut undoes a merge. The order of cuts in Huffman (reversed) gives the optimal splitting strategy.
Example: A stick of length \(10\) must be split into pieces \([2, 3, 5]\). The Huffman merges are \(2 + 3 = 5\) (cost 5), then \(5 + 5 = 10\) (cost 10). Total merge cost = \(15\). Reading cuts in reverse: first cut the stick of \(10\) into \(5\) and \(5\) (cost \(10\)), then cut one of the \(5\)-pieces into \(2\) and \(3\) (cost \(5\)). Total cutting cost = \(15\). Same answer.
Key insight for contests: Whenever you see a problem about splitting or merging with a cost equal to the size of the piece, think Huffman. The min-heap pattern applies directly.
Code
#include <bits/stdc++.h>
using namespace std;
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
int numSymbols;
cin >> numSymbols;
auto comparator = [](long long a, long long b) {
return a > b;
};
priority_queue<long long, vector<long long>, decltype(comparator)> symbolHeap(comparator);
for (int i = 0; i < numSymbols; i++) {
long long freq;
cin >> freq;
symbolHeap.push(freq);
}
long long totalEncodingCost = 0;
while (symbolHeap.size() > 1) {
long long smallest = symbolHeap.top();
symbolHeap.pop();
long long secondSmallest = symbolHeap.top();
symbolHeap.pop();
long long merged = smallest + secondSmallest;
totalEncodingCost += merged;
symbolHeap.push(merged);
}
cout << totalEncodingCost << "\n";
return 0;
}
Time complexity: \(O(N \log N)\). Each of the \(N - 1\) merges requires two pops and one push, each \(O(\log N)\).
Space complexity: \(O(N)\) for the heap.
Edge case: When \(N = 1\), there is only one symbol. No merges happen, and the cost is \(0\). The single symbol gets a 1-bit code by convention (some problems define it differently — read carefully).
Why long long? If you have up to \(10^5\) symbols each with frequency up to \(10^9\), the merged values can reach \(\sim 10^{14}\). Always use long long for the heap and the accumulator.
Try It
Use the starter code and fill in the while loop body. The snippet shows the merge pattern.
Test case 1 — the traced example:
Test case 2 — equal frequencies:
Trace this one by hand: merge \(10 + 10 = 20\), merge \(10 + 10 = 20\), merge \(20 + 20 = 40\). Total = \(20 + 20 + 40 = 80\). When all frequencies are equal, Huffman produces a balanced tree — every leaf at depth \(\lceil \log_2 N \rceil\) or \(\lfloor \log_2 N \rfloor\).
Test case 3 — two symbols:
Only one merge: \(7 + 3 = 10\). Both symbols get 1-bit codes.
Predict before running: For frequencies [1, 2, 3, 4, 5], what is the total cost? Trace the merges: \(1+2=3\), \(3+3=6\), \(4+5=9\), \(6+9=15\). Total = \(3 + 6 + 9 + 15 = 33\).
Challenge: What happens with frequencies [1, 1, 1, 1, 1, 1, 1, 1] (eight equal symbols)? Work through the merges. You should find that the tree is perfectly balanced with every leaf at depth \(3 = \log_2 8\). The total cost is \(8 \times 1 \times 3 = 24\). Verify by computing the merge costs.
Think about it: Can Huffman ever produce a code where all symbols have the same depth? Yes — exactly when \(N\) is a power of 2 and all frequencies are equal. In every other case, the tree is unbalanced and some symbols have longer codes than others.
Problems
Start with Stick Divisions — it is the direct application of Huffman merging. The others require recognizing the Huffman pattern in disguise.
| Problem | Link | Difficulty |
|---|---|---|
| CSES — Stick Divisions | cses.fi/problemset/task/1161 | Easy |
| SPOJ — HUFFMAN | spoj.com/problems/HUFFMAN | Medium |
| CF1041E — Tree Reconstruction | codeforces.com/problemset/problem/1041/E | 1800 |
| CF1481C — Fence Painting | codeforces.com/problemset/problem/1481/C | 1800 |
The Huffman merge pattern appears frequently in competitive programming. Once you recognize the structure — repeatedly combining the two smallest elements with a cost equal to their sum — the min-heap solution writes itself.