Cache Failures
Cache Failures — Stampedes, Hot Keys, and Cold Starts
TL;DR
Caching introduces its own failure modes. A cache stampede hammers your database when a popular key expires. Hot keys overload a single cache node. Cold starts leave your cache empty after a deploy. Each has a specific, well-known solution.
Caching is the first tool most engineers reach for when reads are slow. And it works — until it doesn't. The moment your cache misbehaves, the full blast of traffic hits your database with zero warning.
The Stampede That Killed the Database
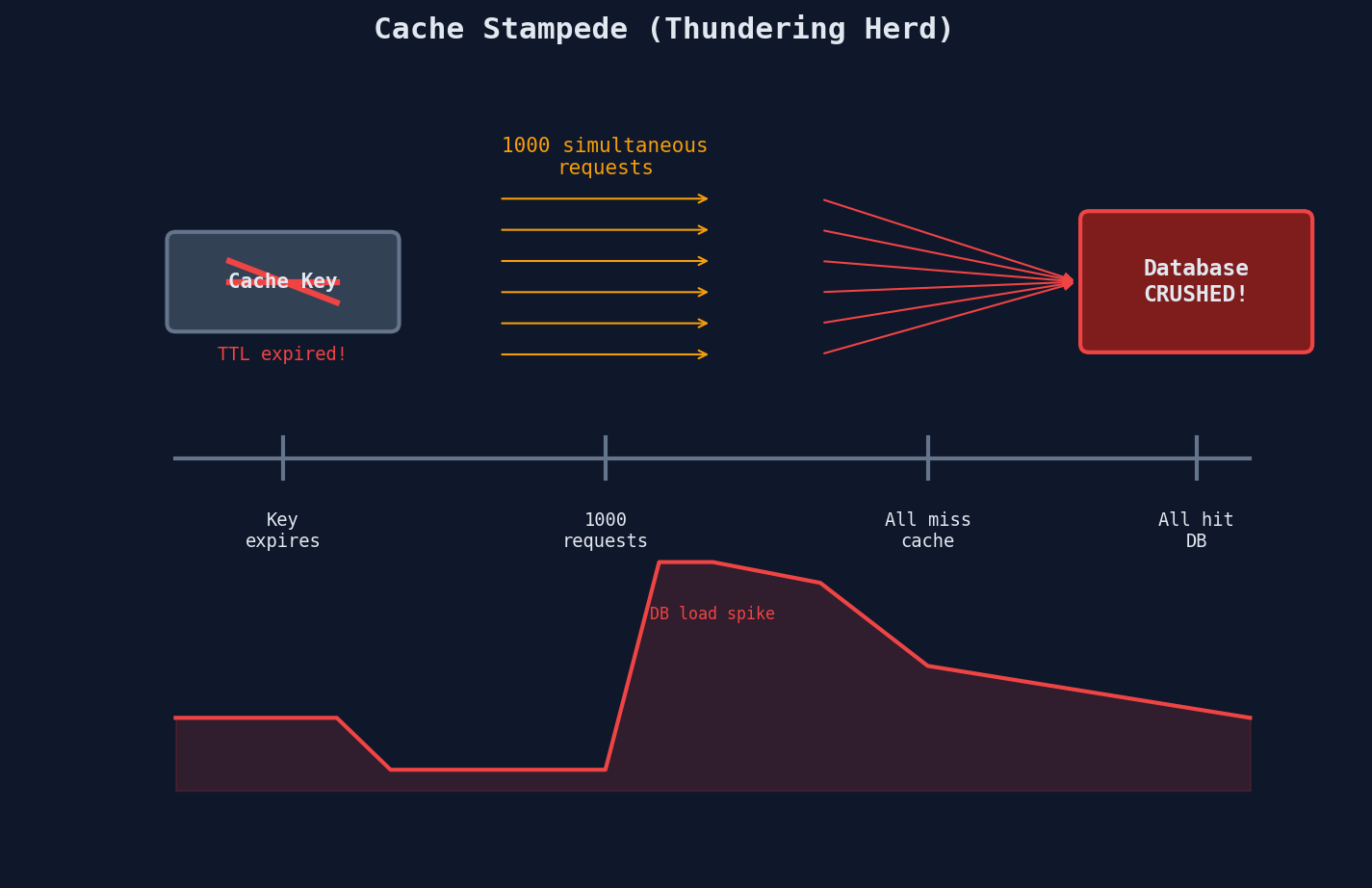
A cache stampede (thundering herd) happens when a popular cache key expires and thousands of concurrent requests all see a cache miss at the same instant.
The scenario: Your best-selling product page is cached with a 5-minute TTL. The key expires. 10,000 users are browsing that page. All of them get a cache miss. All of them query the database. Your database, sized for 200 concurrent queries, gets 10,000 at once. It collapses.
Solution 1: Locking (Mutex-Based Recomputation)
The idea is simple: only ONE request is allowed to recompute the cache entry. Everyone else waits.
First request acquires a distributed lock, fetches from DB, and populates the cache. Everyone else waits and retries the cache read.
import redis
import time
r = redis.Redis()
def get_product(product_id: int) -> dict:
cache_key = f"product:{product_id}"
lock_key = f"lock:{cache_key}"
# Try the cache first
cached = r.get(cache_key)
if cached:
return json.loads(cached)
# Cache miss — try to acquire the lock
# NX = only set if not exists, EX = expire after 5 seconds (safety net)
acquired = r.set(lock_key, "1", nx=True, ex=5)
if acquired:
# We hold the lock — fetch from DB and populate cache
try:
product = db.query("SELECT * FROM products WHERE id = %s", product_id)
r.setex(cache_key, 300, json.dumps(product)) # Cache for 5 min
return product
finally:
r.delete(lock_key) # Release the lock
else:
# Someone else is fetching — wait and retry
for _ in range(50): # Retry up to 50 times
time.sleep(0.1) # 100ms between retries
cached = r.get(cache_key)
if cached:
return json.loads(cached)
# Lock holder probably died — fall through to DB
return db.query("SELECT * FROM products WHERE id = %s", product_id)
The NX flag is critical: SET lock:product:42 1 NX EX 5 only succeeds if the key doesn't exist — an atomic lock acquire built into Redis. The EX 5 auto-expires the lock if the holder crashes, preventing deadlocks.
Always TTL your locks
Without the EX expiry, a crashed lock holder means the lock lives forever and every other request waits forever.
Solution 2: Probabilistic Early Expiration (XFetch)
XFetch refreshes the cache before it expires, with no coordination. Each request rolls the dice — the closer to expiry, the higher the probability of a proactive refresh. Statistically, exactly one request triggers it.
Formula: currentTime - (ttl * beta * log(random())) > expiryTime -- where beta (typically 1.0) controls how early the refresh window opens, and log(random()) is always negative, so probability of refresh increases as expiry approaches.
import math
import random
import time
def xfetch_get(cache_key: str, ttl: int, fetch_fn, beta: float = 1.0):
"""
Get from cache with probabilistic early expiration.
Avoids stampedes without locks or coordination.
"""
cached = r.get(cache_key)
expiry = r.ttl(cache_key)
if cached and expiry > 0:
# Key exists — should we proactively refresh?
now = time.time()
expiry_time = now + expiry
delta = ttl * beta * math.log(random.random()) # Negative value
if now - delta < expiry_time:
# Not time yet — serve from cache
return json.loads(cached)
# Either cache miss or probabilistic refresh triggered
value = fetch_fn()
r.setex(cache_key, ttl, json.dumps(value))
return value
No locks, no retries, no coordination. Each server independently rolls the dice, and the math guarantees that (on average) exactly one server refreshes before expiration.
Solution 3: Stale-While-Revalidate
Serve expired data immediately and trigger a background refresh. The next request gets fresh data.
def stale_while_revalidate(cache_key: str, ttl: int, stale_ttl: int, fetch_fn):
"""
Serve stale data instantly, refresh in the background.
stale_ttl: how long to keep stale data after TTL expires.
"""
cached = r.get(cache_key)
real_ttl = r.ttl(cache_key)
if cached and real_ttl > stale_ttl:
# Fresh data — serve it
return json.loads(cached)
if cached:
# Stale but available — serve it, refresh async
threading.Thread(target=_refresh, args=(cache_key, ttl, stale_ttl, fetch_fn)).start()
return json.loads(cached)
# Nothing cached at all — blocking fetch
return _refresh(cache_key, ttl, stale_ttl, fetch_fn)
def _refresh(cache_key, ttl, stale_ttl, fetch_fn):
value = fetch_fn()
# Set TTL to ttl + stale_ttl so stale data is available during revalidation
r.setex(cache_key, ttl + stale_ttl, json.dumps(value))
return value
Picking the Right Stampede Solution
| Approach | Coordination | Latency | Staleness | Best For |
|---|---|---|---|---|
| Locking | Distributed lock | Some waiters blocked | None | Correctness-critical data (prices, inventory) |
| XFetch | None | Uniform | None (refresh before expiry) | High-throughput systems, stateless services |
| Stale-while-revalidate | None | Always fast | Brief window | Latency-sensitive UIs, content pages |
Most production systems combine these. Prices and inventory get locking. Product descriptions get stale-while-revalidate. High-traffic metadata gets XFetch.
The Hot Key That Melted a Cache Node
A hot key receives so much traffic that it saturates the single cache node that owns it.
The scenario: A celebrity posts a photo. Their profile key gets 50,000 requests/second. A single Redis node handles ~100K-200K ops/sec total. One key is consuming half the node's capacity. Other keys on the same node start timing out. Users see errors for completely unrelated data.
Solution A: Local In-Process Cache (L1)
Each application server caches hot keys in its own memory. The request never leaves the server — no network hop to Redis at all.
from time import time
class L1Cache:
"""In-process cache with TTL. One per app server."""
def __init__(self, max_size=1000, ttl=5):
self._store = {} # key -> (value, expires_at)
self._max_size = max_size
self._ttl = ttl
def get(self, key: str):
if key in self._store:
value, expires_at = self._store[key]
if time() < expires_at:
return value
del self._store[key]
return None
def set(self, key: str, value):
self._store[key] = (value, time() + self._ttl)
The trade-off: 20 app servers means 20 independent copies, each expiring independently. Some servers might serve old data for a few seconds after a write. Fine for a celebrity profile — not for a bank balance.
Solution B: Key Replication with Random Suffixes
Spread the hot key across multiple cache entries so no single node bears all the load.
import random
REPLICA_COUNT = 10
def get_hot_key(base_key: str):
"""Read from a random replica to spread load across nodes."""
suffix = random.randint(0, REPLICA_COUNT - 1)
return r.get(f"{base_key}:{suffix}")
def set_hot_key(base_key: str, value: str, ttl: int):
"""Write to ALL replicas so any read hits fresh data."""
pipe = r.pipeline()
for i in range(REPLICA_COUNT):
pipe.setex(f"{base_key}:{i}", ttl, value)
pipe.execute()
With 10 replicas across different Redis nodes (via consistent hashing), load drops to 5,000 req/sec per node — well within capacity.
Solution C: Redis Read Replicas
Route reads to Redis read replicas, writes to the primary. Simplest operationally — no code changes — but adds replication lag (typically milliseconds).
Multi-Layer Caching Architecture
Production systems stack multiple cache layers:
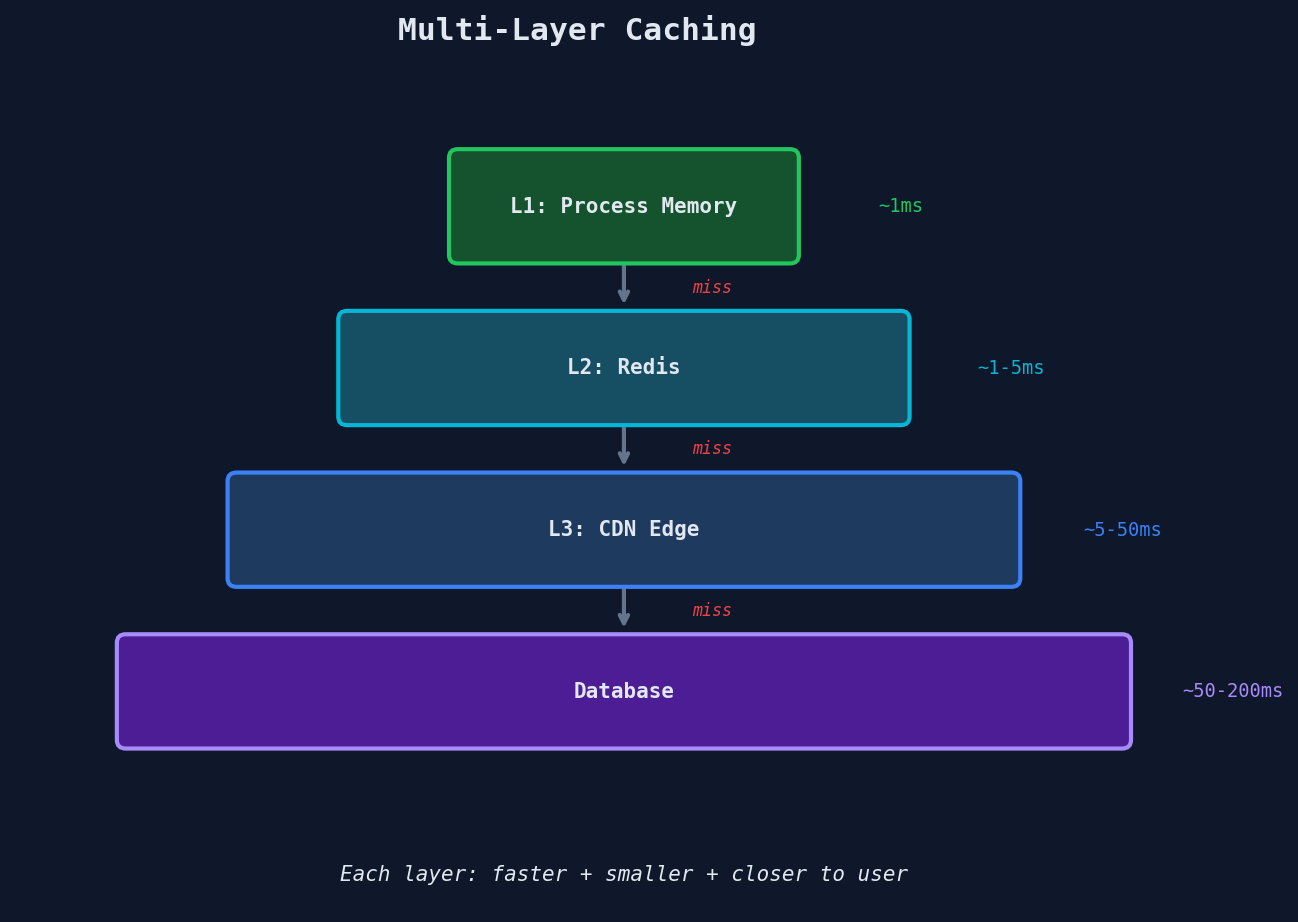
Each layer absorbs traffic. L1 catches 60-80% of hot key reads. L2 catches 90-95% of what's left. The database only sees a trickle.
Proof Point: Slack's Flannel
Slack's Flannel service maintains a per-connection cache of channel and user data at the edge, ensuring each WebSocket connection has instant access to the data it needs without hitting central caches. This is an extreme form of L1 caching — the cache is scoped to a single user connection, so it contains exactly the data that connection will request.
Interview Pattern
If the interviewer mentions a viral event, a celebrity, or a flash sale -- the hot key pattern is what they're fishing for. Walk through L1 caching and key replication to stand out.
Request Coalescing — Deduplicate at the Server
If 500 concurrent requests on the same server want the same key, why send 500 identical queries? Request coalescing (a.k.a. "single-flight") ensures only ONE outgoing request per unique key per server.
import threading
class RequestCoalescer:
"""First caller fetches. Others wait for the same result."""
def __init__(self):
self._in_flight = {} # key -> (Event, result_dict)
self._lock = threading.Lock()
def get(self, key: str, fetch_fn):
with self._lock:
if key in self._in_flight:
event, result = self._in_flight[key]
else:
event, result = threading.Event(), {}
self._in_flight[key] = (event, result)
threading.Thread(
target=self._fetch, args=(key, fetch_fn, event, result)
).start()
event.wait(timeout=5) # All callers block here
return result.get("value")
def _fetch(self, key, fetch_fn, event, result):
try:
result["value"] = fetch_fn()
finally:
with self._lock:
del self._in_flight[key]
event.set() # Wake up all waiters
The math: 20 app servers, 500 concurrent requests per server = 10,000 DB queries without coalescing. With coalescing: 20 queries. A 500x reduction.
Go's singleflight package provides this out of the box. In Python, use asyncio equivalents in production.
Cold Start — The Empty Cache Problem
A cold start happens when your cache has no data — every request is a miss and your database gets the full, unshielded blast of production traffic.
When it happens: new cache cluster deployment, Redis crash/restart, provider migration, or adding new nodes (consistent hashing redistributes keys, new nodes are empty).
The scenario: You restart Redis at 2 AM. Traffic is "only" 5,000 req/sec. Cache is empty. All 5,000 hit the database, which is provisioned for 500 req/sec (the cache normally absorbs 90%). Database buckles. Latencies spike. Your "low-risk maintenance" becomes an incident.
Solution A: Cache Warming
Before you route any production traffic to the new cache, pre-populate it with the most frequently accessed keys.
def warm_cache(db, redis_client, top_n=10000):
"""Pre-populate cache with the most accessed keys. Run BEFORE routing traffic."""
hot_keys = db.query("""
SELECT product_id FROM access_logs
WHERE timestamp > NOW() - INTERVAL '1 hour'
GROUP BY product_id ORDER BY COUNT(*) DESC LIMIT %s
""", top_n)
for row in hot_keys:
product = db.query("SELECT * FROM products WHERE id = %s", row["product_id"])
redis_client.setex(f"product:{row['product_id']}", 300, json.dumps(product))
This covers 80-90% of traffic — access patterns follow a Zipf distribution where a small number of keys account for most requests.
Solution B: Gradual Traffic Rollout
Treat the new cache like a canary deployment. Route 1% of traffic to it, monitor DB load and hit rate, then ramp to 5%, 10%, 25%, 50%, 100%. Each increment lets the cache organically fill with hot keys.
def get_with_gradual_rollout(key: str, new_cache, old_cache, rollout_pct: int):
"""Route a percentage of traffic to the new cache cluster."""
if hash(key) % 100 < rollout_pct:
# New cache path
value = new_cache.get(key)
if value is None:
value = db.query(key)
new_cache.set(key, value)
return value
else:
# Old cache path (or DB with rate limiting)
return old_cache.get(key) or db.query(key)
Solution C: Dual-Read Fallback
On a miss in the new cache, check the old cache before falling back to the database. The new cache warms organically without extra DB load.
def dual_read(key: str, new_cache, old_cache):
"""New cache → old cache → DB. Populates new cache on every path."""
value = new_cache.get(key)
if value:
return value
value = old_cache.get(key) or db.query(key)
new_cache.set(key, value, ttl=300)
return value
Never hard-cut traffic to a cold cache cluster
The initial miss storm can take down your database within seconds. Always warm, gradually roll out, or dual-read.
Failure Modes Summary
| Failure | Trigger | Impact | Primary Fix |
|---|---|---|---|
| Stampede | Popular key expires | All requests hit DB simultaneously | Locking or XFetch |
| Hot key | One key gets disproportionate traffic | Single cache node saturated | L1 cache + key replication |
| Cold start | Cache restart or migration | 100% miss rate, DB overloaded | Cache warming + gradual rollout |
| Request pile-up | Many concurrent requests for same key | Redundant DB queries | Request coalescing |
How the Giants Handle It
Facebook's Memcached layer handles 10B+ requests/day with a 99.9% hit rate. Their thundering herd mitigation uses lease tokens — the cache issues a lease to exactly one client on a miss; everyone else gets a "wait" response.
Netflix's EVCache processes 30M+ ops/sec. They combine L1 caches, zone-aware replication, and gradual warming during deployments. When a node dies, traffic redistributes with warm-up throttling to prevent cascading failures.
Interview Tip
Interviewers love asking "what happens when your cache goes down?" Have a ready answer: cache warming to pre-populate hot keys, gradual rollout to avoid a miss storm, and graceful degradation (serve from the database at reduced capacity with aggressive rate limiting). Saying "we'd just restart the cache" is the answer that gets you passed over. Explaining the cold start problem and its solutions is the answer that gets you hired.