Cross-Shard Queries & Hot Spots
TL;DR
Sharding solves scale problems but creates new ones — cross-shard queries are expensive, hot spots overload individual shards, and operational complexity increases dramatically. Before sharding, exhaust simpler alternatives: indexes, read replicas, partitioning, and caching.
The Cost Nobody Mentions Upfront
Sharding tutorials focus on the upside: horizontal scale, distributed writes, theoretically unlimited storage. But they rarely talk about what breaks:
- Queries that used to be a single-table scan now fan out to every shard
- That convenient JOIN between users and orders? Impossible if they're on different shards
- One viral user's data melts a single shard while others sit idle
- Every migration, backup, and monitoring task now happens N times
Sharding is a permanent architectural commitment with permanent trade-offs. Let's understand them so you can make informed decisions.
Cross-Shard Queries
The Problem
With data sharded by user_id, the query "get all posts by user 42" is fast — it hits one shard. But "get the top 100 most-liked posts across all users" must:
- Send the query to every shard
- Wait for the slowest shard to respond (tail latency)
- Merge and re-sort results from all shards
This is called scatter-gather, and it gets worse with more shards. 10 shards = 10 parallel queries. 100 shards = 100 parallel queries. The P99 latency is bounded by the slowest shard.
Cross-Shard Joins
Joins across shards are even harder. If users is sharded by user_id and orders is sharded by order_id, joining them requires fetching data from multiple shards on both tables, then joining in the application layer.
Most sharded systems don't support cross-shard joins at all. You work around them.
Strategies to Avoid Cross-Shard Queries
1. Co-locate related data:
Shard users and orders by the same key (user_id). All of a user's orders live on the same shard as the user. Joins within a user's data stay on one shard.
2. Reference table replication: Small, rarely-changing tables (countries, currencies, product categories) can be replicated to every shard. Joins against reference tables stay local.
3. Denormalization:
Instead of joining orders with products, store product_name and product_price directly on the order row. Eliminates the join entirely. Instagram stores author usernames on posts for this reason.
4. Application-level joins: Fetch data from multiple shards, then join in application code. Less efficient than database joins, but sometimes the only option.
5. Search index for global queries: Sync data to Elasticsearch for queries that need to span all shards. "Top 100 most-liked posts" becomes an Elasticsearch query, not a scatter-gather across shards.
Hot Spots
The Celebrity Problem
Even with a perfect hash function and even distribution, some shards get disproportionate traffic. If Taylor Swift (user_id: 12345) lives on Shard 7, and she has 80 million followers who all check her latest post at once — Shard 7 is in trouble while other shards sit at 10% CPU.
This isn't a distribution problem. The key itself is hot.
Time-Based Hot Spots
If you shard by time range (messages from March on Shard 3, April on Shard 4), all new writes hit the current month's shard. The newest shard gets 100% of write traffic while historical shards get only reads.
Solutions
Salting the shard key:
Append a random suffix to hot keys. user:12345 becomes user:12345:0, user:12345:1, ..., user:12345:9. Reads scatter across 10 shards and merge results. Writes distribute evenly.
The trade-off: reads for that key are now 10x more expensive (scatter-gather). Only worth it for the hottest keys.
Request coalescing (Discord's approach): When 1,000 users request the same channel's messages simultaneously, the data services layer coalesces them into a single database read and fans the result out to all 1,000 requestors. The database sees 1 query instead of 1,000.
This is an application-layer solution, not a database solution — and it was one of the most impactful changes in Discord's architecture.
Dedicated shards: Move the hottest keys to their own dedicated shard with more resources. A directory-based sharding approach makes this possible — update the lookup table to route celebrity user IDs to beefier hardware.
Sharded counters:
Instead of one like_count field that every like contends for, split it into N counter shards. Each like increments a random shard. Total count = sum of all shards. Eliminates write contention.
import random
NUM_SHARDS = 10
def increment_likes(post_id):
shard = random.randint(0, NUM_SHARDS - 1)
db.execute(
"UPDATE like_counters SET count = count + 1 WHERE post_id = %s AND shard = %s",
post_id, shard
)
def get_likes(post_id):
rows = db.execute("SELECT SUM(count) FROM like_counters WHERE post_id = %s", post_id)
return rows[0] # one query, but no write contention
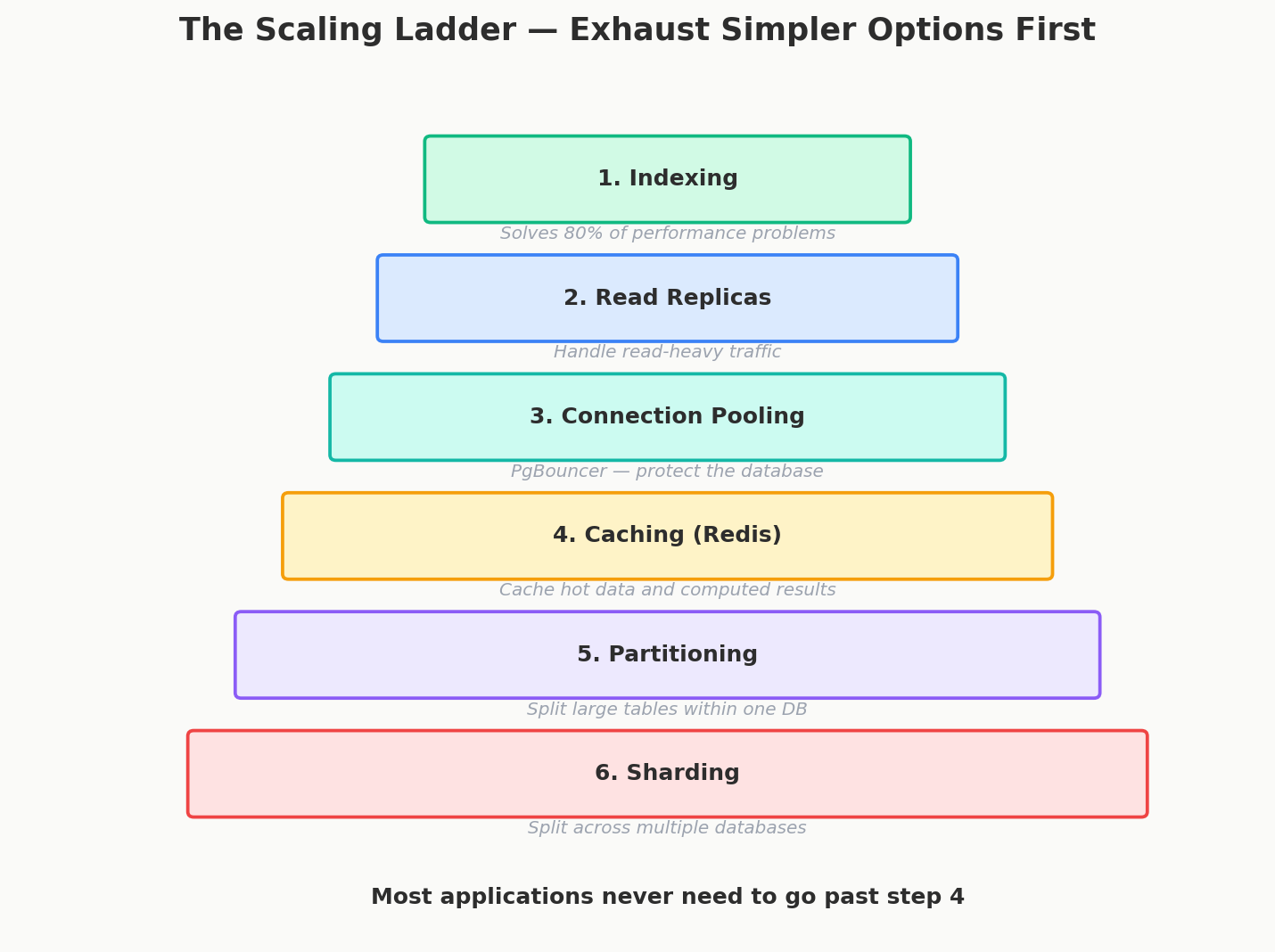
The Alternatives Ladder
Before sharding, exhaust every simpler option. Each step solves a class of problems with less complexity than sharding:
Level 1: Indexing
└─ Query slow? Add the right index. Solves 80% of performance problems.
Level 2: Read Replicas
└─ Read-heavy? Add replicas. Split reads to replicas, writes to primary.
Level 3: Partitioning (single machine)
└─ Table too large? Use PostgreSQL PARTITION BY. Faster scans, easier maintenance.
Level 4: Caching
└─ Hot data? Add Redis. Cache computed results, session data, rate limiting.
Level 5: Connection Pooling
└─ Too many connections? Add PgBouncer. Multiplex client connections.
Level 6: Sharding
└─ Exhausted everything above? Now consider sharding.
Level 7: NewSQL
└─ Need sharding without the pain? Consider CockroachDB or Spanner.
Each level is cheaper and less risky than the next. Most applications never need to go past Level 4.
When NOT to Shard
| Signal | Why You Shouldn't Shard |
|---|---|
| Data fits on one machine | Sharding adds complexity with zero benefit |
| Read replicas handle the load | Reads are the bottleneck, not writes or storage |
| Caching solves the hot path | Redis is simpler than resharding your database |
| You need complex cross-shard transactions | Distributed transactions across shards are painful |
| Your team doesn't have the expertise | Operational complexity of sharding is significant |
| A NewSQL database would work | CockroachDB/Spanner auto-shard for you |
Interview Tip
The most impressive thing you can say in an interview about sharding is "I'd try these alternatives first." Walk through the ladder: "First I'd optimize indexes, add read replicas for read load, add caching for hot paths, and partition the largest tables. If we're still hitting limits — then I'd shard by user_id using hash-based sharding with consistent hashing." That shows you understand sharding is a last resort, not a first instinct.
Quick Recap
| Challenge | Cause | Solution |
|---|---|---|
| Cross-shard queries | Data split across machines | Co-location, denormalization, search index |
| Cross-shard joins | Related tables on different shards | Shard by same key, application-level joins |
| Celebrity hot spots | One key gets massive traffic | Salting, request coalescing, dedicated shards |
| Time-based hot spots | All writes hit newest shard | Composite keys (user_id + time_bucket) |
| Premature sharding | Sharding before simpler solutions | Exhaust the alternatives ladder first |
Further reading: For quick-reference summaries, see the standalone Sharding and Consistent Hashing articles.