Social Media at Scale
TL;DR
Facebook stores the social graph in sharded MySQL with a caching layer (TAO), not a graph database. Twitter uses a hybrid fan-out strategy — push for normal users, pull for celebrities — with 105TB of Redis. The common lesson: simple data models with smart caching beat exotic databases.
Facebook TAO — The Social Graph on MySQL
The Problem
Facebook's social graph — users, friendships, likes, comments, shares — is one of the largest datasets on Earth. In 2012, their previous solution (a memcached layer over MySQL) had two issues:
- Thundering herds: When a cached item expired, hundreds of simultaneous requests hit MySQL
- Stale data: Inconsistencies between cache and database were hard to detect and fix
They needed a purpose-built system that understood the graph semantics of their data.
The Data Model
TAO (The Associations and Objects) models everything as two primitives:
Objects (nodes): Users, posts, photos, pages. Each has a 64-bit ID and a set of key-value pairs.
Associations (edges): Friendships, likes, comments, tags. Each has a source object, destination object, type, timestamp, and key-value metadata.
Object: User{id: 1, name: "Alice", type: "user"}
Object: Post{id: 500, text: "Hello!", type: "post"}
Association: (User:1) ──AUTHORED──► (Post:500) [time: 2024-03-15]
Association: (User:2) ──LIKED──► (Post:500) [time: 2024-03-16]
This is a graph data model — but it's not stored in a graph database. It's stored in sharded MySQL.
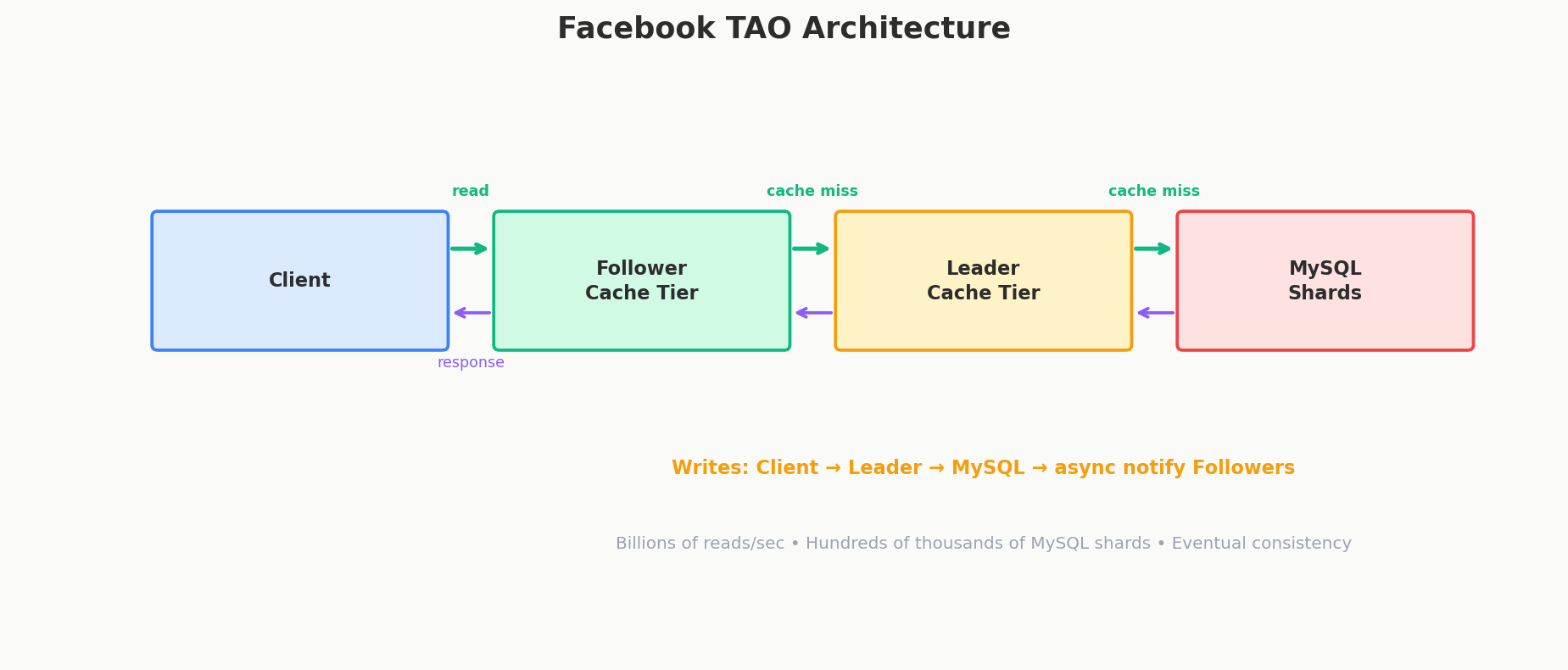
Architecture
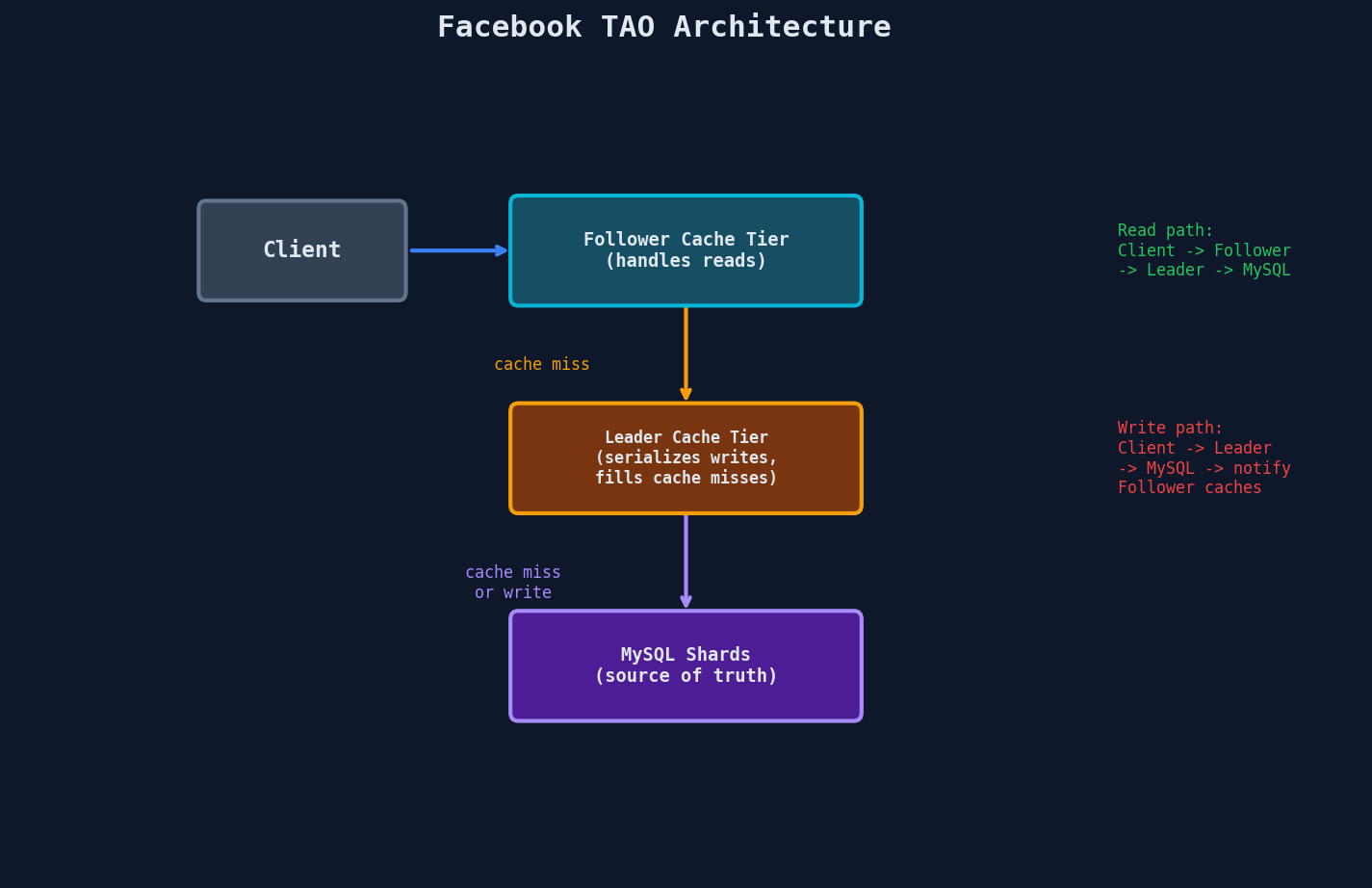
Read path: Client → Follower cache → (miss) → Leader cache → (miss) → MySQL
Write path: Client → Leader cache → MySQL → async notify Follower caches
Key Design Decisions
Eventual consistency: Leader caches update Follower caches asynchronously. A user on the US East Coast might see a like count of 42 while a user on the West Coast sees 41 — for a second or two. For social media, this is perfectly acceptable.
Shard assignment baked into object IDs: The shard number is embedded in the 64-bit object ID itself. No lookup table needed — the system can compute which shard holds any object directly from its ID.
Scale: Billions of reads per second, millions of writes per second, hundreds of thousands of MySQL shards.
The Lesson
"Even Facebook's graph database is built on sharded MySQL with a smart caching layer."
The takeaway isn't "use MySQL for everything." It's that a simple data model with a well-designed caching layer outperforms exotic databases for most workloads. Facebook didn't need graph traversal algorithms for their primary use cases — they needed fast key-value lookups for "get Alice's friends" and "get likes on this post."
Twitter Timeline — The Fan-Out Problem
The Problem
When you open Twitter, your home timeline shows recent tweets from everyone you follow. How do you build that?
There are two approaches, and Twitter has used both.
Fan-Out on Write (Push Model)
When a user tweets, immediately push that tweet into every follower's pre-computed timeline:
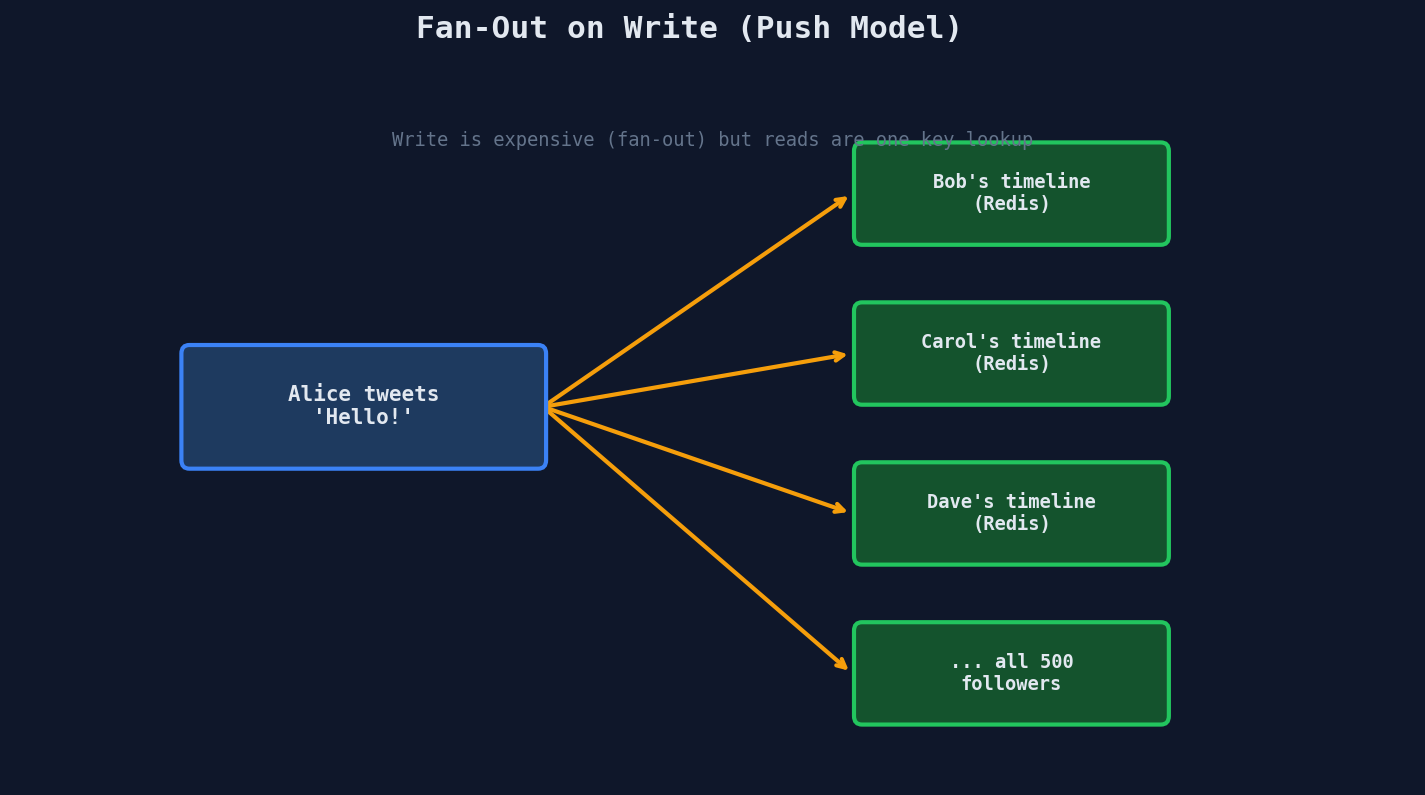
Reading the timeline: Just fetch Bob's pre-built list from Redis. One key lookup. Blazing fast.
def fan_out_on_write(tweet, author_id):
"""Push a tweet into every follower's pre-computed timeline."""
followers = db.execute("SELECT follower_id FROM follows WHERE user_id = %s", author_id)
pipe = redis.pipeline()
for fid in followers:
pipe.lpush(f"timeline:{fid}", json.dumps(tweet)) # prepend to timeline
pipe.ltrim(f"timeline:{fid}", 0, 799) # keep latest 800
pipe.execute() # one round-trip for all
def read_timeline(user_id):
return redis.lrange(f"timeline:{user_id}", 0, 49) # top 50, sub-millisecond
The infrastructure: Twitter stored pre-computed timelines in Redis clusters. At peak: 105TB of RAM across the Redis fleet, serving 39 million queries per second.
The Celebrity Problem
When Taylor Swift tweets, the system needs to push to 80 million followers' timelines simultaneously. That fan-out job saturated the write path for 3-5 seconds, delaying delivery of every other tweet in the system.
The math is brutal: if each timeline write takes 0.01ms, 80 million writes take 800 seconds. Even parallelized across hundreds of machines, it's a massive burst of work.
Fan-Out on Read (Pull Model)
The alternative: don't pre-compute anything. When Bob opens his timeline, query all users Bob follows and merge their recent tweets:
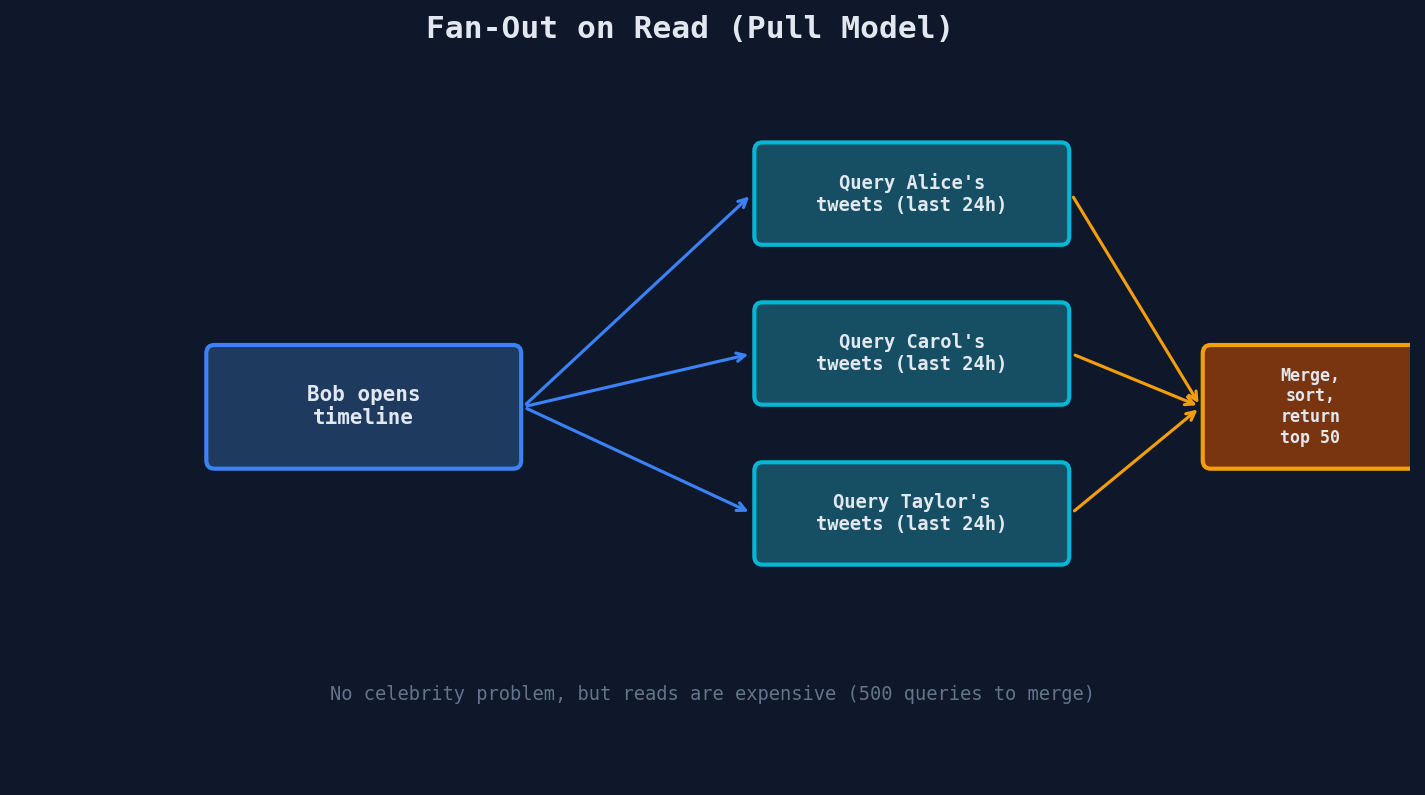
No celebrity problem: Taylor's tweets are stored once. No matter how many followers, the write is one operation.
But reads are expensive: If Bob follows 500 people, that's 500 queries to merge. Slow.
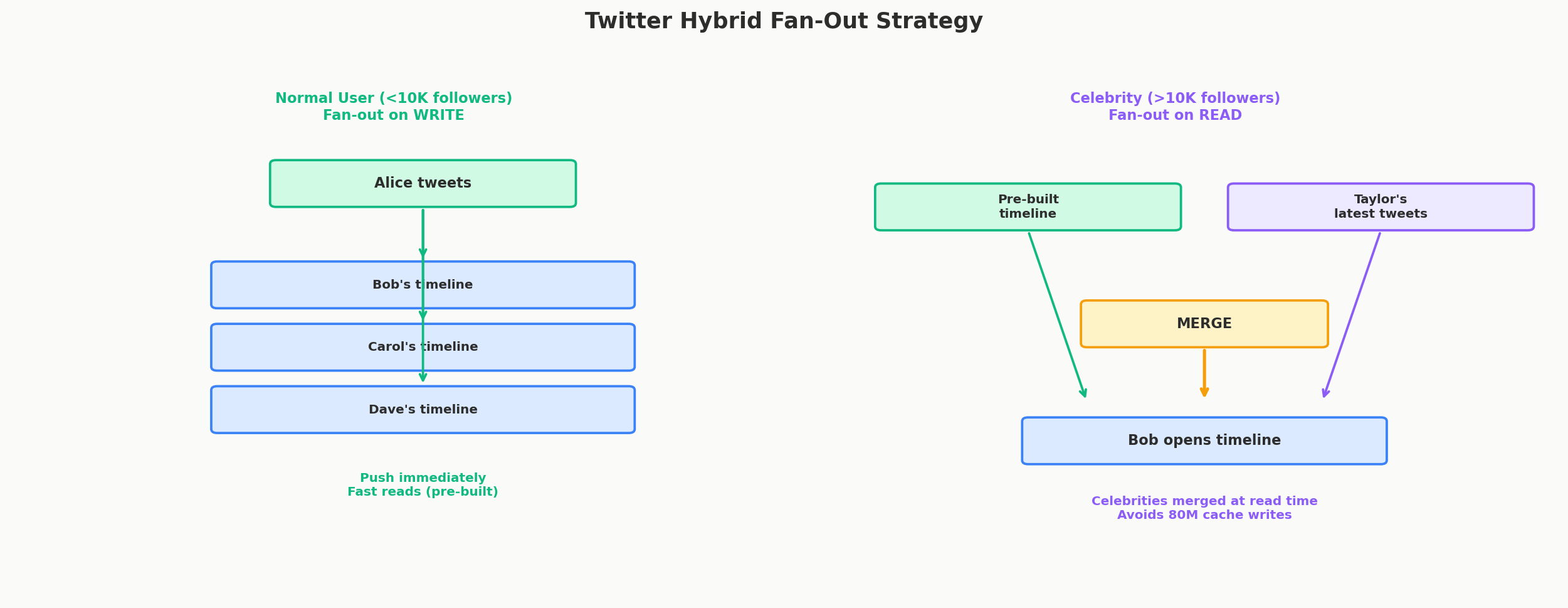
The Hybrid Solution (What Twitter Actually Does)
Twitter uses both strategies, split by follower count:
| User Type | Strategy | Threshold |
|---|---|---|
| Normal users (< ~10K followers) | Fan-out on write | Tweets pushed to followers' timelines |
| Celebrities (> ~10K followers) | Fan-out on read | Tweets merged at read time |
When Bob opens his timeline: 1. Fetch his pre-computed timeline from Redis (contains tweets from normal users he follows) 2. Fetch recent tweets from the handful of celebrities he follows 3. Merge and display
This hybrid eliminates the celebrity problem while keeping reads fast for the majority of users.
Interview Tip
If you're designing a social media feed, always mention the hybrid approach. "For users with fewer than 10K followers, I'd fan out on write into a Redis timeline. For high-follower accounts, I'd merge their posts at read time. This avoids the celebrity problem while keeping reads fast." That's the mature answer.
Instagram Feed — Ranking Changes Everything
Instagram's feed architecture is similar to Twitter's but with a crucial difference: the feed isn't chronological.
Instagram uses a machine learning ranking model to determine which posts appear in your feed and in what order. This changes the data model:
- Pre-computed timelines can't be fully ranked until read time (ranking depends on recency, your engagement patterns, and real-time signals)
- The "candidate set" (posts that could appear) is computed via fan-out, but the ordering is computed at read time
- This means a hybrid fan-out + ranking pipeline, not a pure pre-computed list
The Lesson
The data model serves the product requirements, not the other way around. Instagram needed ranking, so their data model evolved to support a candidate generation + ranking pipeline. Twitter needed chronological ordering (initially), so pure fan-out worked.
Common Patterns Across All Three
| Pattern | |||
|---|---|---|---|
| Primary storage | Sharded MySQL | Various + Redis | Various + Redis |
| Caching | Two-tier (leader + follower) | Redis timelines | Redis + CDN |
| Consistency | Eventual | Eventual | Eventual |
| Celebrity handling | N/A (graph is symmetric) | Hybrid fan-out | Hybrid fan-out |
| Data model | Objects + Associations | Tweets + Timelines | Posts + Ranking pipeline |
Quick Recap
| Company | Key Insight |
|---|---|
| Facebook TAO | Graph model on sharded MySQL + cache. Simple model, smart caching. |
| Hybrid fan-out. Push for normal users, pull for celebrities. | |
| Fan-out for candidates, ranking at read time. Data model serves the product. |