APIs at Scale
TL;DR
Studying how companies like Stripe, GitHub, Netflix, and Twilio design their APIs teaches you patterns that impress in interviews. Stripe is the gold standard for REST, GitHub pioneered public GraphQL, Netflix popularized the BFF pattern, and Twilio shows how to design for developer experience.
The best way to understand good API design is to study the APIs that millions of developers actually use. These companies have made mistakes, learned from them, and iterated into designs that handle billions of requests daily.
Stripe: The Gold Standard of REST
If you study one API, make it Stripe. Their API is widely considered the best-designed REST API in the industry, and for good reason.
What Makes Stripe Special
Versioning that never breaks clients: Stripe takes a radically different approach to versioning. Every API version is supported forever. When you create an account, you're pinned to the current version. Stripe can release breaking changes, but they only affect newly created accounts.
# Your requests always use your pinned version
curl https://api.stripe.com/v1/charges \
-H "Authorization: Bearer sk_live_..." \
-H "Stripe-Version: 2024-04-10" # Pin to specific version
Behind the scenes, Stripe maintains a chain of version transformations. A request from a 2020 API version passes through each transformation layer until it reaches the current internal representation.
Idempotency keys for safe retries:
POST /v1/charges
Idempotency-Key: unique-request-id-abc123
{
"amount": 2000,
"currency": "usd",
"source": "tok_visa"
}
If the network fails and the client retries with the same Idempotency-Key, Stripe returns the original response without charging the card again. This is critical for financial operations.
Consistent resource naming: Every Stripe resource follows the same pattern: plural nouns, predictable CRUD operations, nested sub-resources.
GET /v1/customers
POST /v1/customers
GET /v1/customers/{id}
PUT /v1/customers/{id}
DELETE /v1/customers/{id}
GET /v1/customers/{id}/charges # Sub-resource
POST /v1/customers/{id}/charges
Expansion for flexible data fetching: Instead of returning flat IDs, Stripe lets you expand nested resources inline:
# Without expansion — returns customer ID only
GET /v1/charges/ch_123
{ "customer": "cus_456" }
# With expansion — returns full customer object
GET /v1/charges/ch_123?expand[]=customer
{ "customer": { "id": "cus_456", "name": "Jane Doe", "email": "..." } }
This solves the under-fetching problem without needing GraphQL.
Structured error responses:
{
"error": {
"type": "card_error",
"code": "card_declined",
"message": "Your card was declined.",
"param": "source",
"decline_code": "insufficient_funds"
}
}
Every error has a type, code, human-readable message, and the specific param that caused the issue.
Interview Tip
Mentioning Stripe's idempotency keys or expansion pattern in an interview shows you've studied real-world API design, not just textbook examples.
GitHub: REST v3 + GraphQL v4
GitHub is a fascinating case study because they maintain both REST and GraphQL APIs publicly.
REST v3: HATEOAS in Practice
GitHub's REST API is one of the few large-scale APIs that implements HATEOAS (Hypermedia as the Engine of Application State). Every response includes links to related resources:
{
"id": 1,
"name": "octocat/Hello-World",
"url": "https://api.github.com/repos/octocat/Hello-World",
"issues_url": "https://api.github.com/repos/octocat/Hello-World/issues{/number}",
"pulls_url": "https://api.github.com/repos/octocat/Hello-World/pulls{/number}",
"commits_url": "https://api.github.com/repos/octocat/Hello-World/commits{/sha}"
}
This means clients can discover the API by following links, rather than hardcoding URLs. The pattern is seeing a resurgence because autonomous AI agents can navigate APIs by following HATEOAS links without needing documentation.
GraphQL v4: Why They Added It
GitHub added GraphQL because their mobile and web apps needed radically different data:
The REST problem:
# To show a repo page, the web UI needs:
GET /repos/octocat/Hello-World # Basic info
GET /repos/octocat/Hello-World/readme # README content
GET /repos/octocat/Hello-World/topics # Topics
GET /repos/octocat/Hello-World/languages # Language breakdown
GET /repos/octocat/Hello-World/releases # Latest release
# 5 separate HTTP requests!
The GraphQL solution:
query {
repository(owner: "octocat", name: "Hello-World") {
name
description
readme: object(expression: "HEAD:README.md") { ... on Blob { text } }
repositoryTopics(first: 10) { nodes { topic { name } } }
languages(first: 5) { nodes { name } }
releases(first: 1) { nodes { name tagName } }
}
}
One request. Exactly the data needed. No over-fetching.
Interview Tip
GitHub maintaining both REST and GraphQL is a perfect example of "use the right tool for the job." Mention this when discussing protocol tradeoffs.
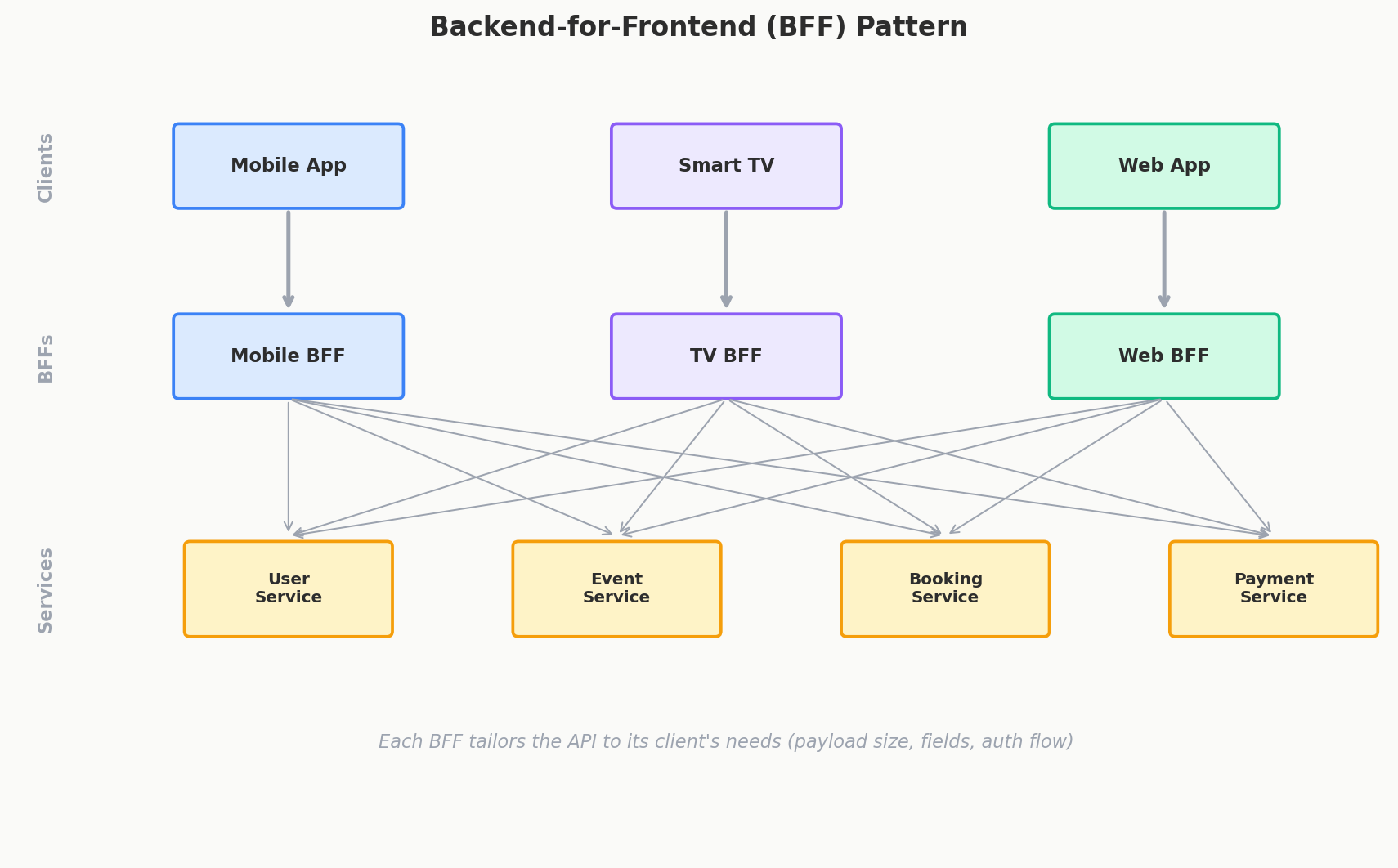
Netflix: The BFF Pattern
Netflix serves content to TVs, phones, tablets, gaming consoles, and web browsers. Each device has wildly different capabilities, screen sizes, and network constraints. Their API architecture reflects this reality.
Backend for Frontend (BFF)
Instead of one API for all clients, Netflix builds a dedicated backend for each client type:
┌─────────┐ ┌──────────┐ ┌───────────────┐
│ TV App │────→│ TV BFF │────→│ │
└─────────┘ └──────────┘ │ │
│ Microservices │
┌─────────┐ ┌──────────┐ │ (Catalog, │
│ Mobile │────→│Mobile BFF│────→│ Profiles, │
└─────────┘ └──────────┘ │ Recs, ...) │
│ │
┌─────────┐ ┌──────────┐ │ │
│ Web │────→│ Web BFF │────→│ │
└─────────┘ └──────────┘ └───────────────┘
Each BFF: - Aggregates data from multiple microservices - Shapes responses for its specific client's needs - Handles client-specific logic (e.g., image sizes for TV vs mobile) - Can be owned by the client team, not the backend team
GraphQL Federation
Netflix evolved their BFF approach using GraphQL federation. Each team owns a slice of the overall schema:
# Catalog team owns:
type Movie {
id: ID!
title: String!
releaseYear: Int!
}
# Recommendations team extends:
extend type Movie {
personalScore: Float! # Predicted match score
similarTitles: [Movie!]! # "Because you watched..."
}
# The gateway composes both into a single schema
This lets teams work independently while presenting a unified API to clients.
Zuul Gateway
All requests pass through Zuul, Netflix's API gateway, which handles: - Routing to the right BFF - Authentication and rate limiting - Request/response filtering - Canary deployments (route 1% of traffic to new version) - Logging and metrics
Interview Tip
The BFF pattern is the answer when an interviewer says "we have very different mobile and web clients." It shows you understand that one-size-fits-all APIs create problems at scale.
Twilio: Developer Experience First
Twilio's API success comes from obsessing over developer experience. They treat their API like a product, not just an interface.
Resource-Oriented URLs
# Send an SMS
POST /2010-04-01/Accounts/{AccountSid}/Messages.json
{
"To": "+15558675310",
"From": "+15017122661",
"Body": "Hello from Twilio!"
}
Webhooks for Async Operations
When an SMS is delivered or a call completes, Twilio doesn't force you to poll. Instead, you configure a webhook URL, and Twilio sends you the event:
# Your webhook endpoint receives:
POST /my-webhook
{
"MessageSid": "SM123",
"MessageStatus": "delivered",
"To": "+15558675310"
}
This is a common pattern for APIs that involve external systems (payment processors, messaging, email).
Consistent Error Codes
{
"code": 21211,
"message": "The 'To' number +1555867531 is not a valid phone number.",
"more_info": "https://www.twilio.com/docs/errors/21211",
"status": 400
}
Every error has a unique numeric code and a link to detailed documentation. This makes debugging incredibly fast.
Slack: Event-Driven Architecture
Slack's API combines multiple protocols for different use cases:
- REST (Web API): CRUD operations — create channels, send messages, manage users
- WebSockets (RTM API): Real-time message events for bots
- Events API: Webhook-based events (preferred over WebSockets for scalability)
- OAuth: Scoped access tokens for third-party apps
Scoped Access
Slack's OAuth tokens have granular scopes:
# A bot that only reads messages in channels it's been added to:
scope: channels:read,channels:history
# A full admin integration:
scope: admin,channels:manage,users:read,chat:write
This is a great example of the principle of least privilege in API auth.
Google Cloud: REST + gRPC Dual Stack
Google Cloud exemplifies the mixed-protocol pattern — REST for public-facing APIs, gRPC for internal communication.
Public APIs: REST with JSON
GET https://compute.googleapis.com/compute/v1/projects/{project}/zones/{zone}/instances
Authorization: Bearer ya29.access-token
Internal Services: gRPC with Protocol Buffers
Between Google's internal services, everything communicates via gRPC. The .proto files serve as contracts, and code is auto-generated in whatever language each team prefers.
API Design Guide
Google publishes their API Design Guide — a comprehensive document covering naming conventions, error handling, and resource modeling. It's one of the best resources for learning API design principles.
Lessons for Your Interviews
| Company | Key Pattern | When to Mention |
|---|---|---|
| Stripe | Idempotency keys, expansion, versioning | Payment systems, e-commerce |
| GitHub | HATEOAS, dual REST+GraphQL | Developer tools, platforms with diverse clients |
| Netflix | BFF pattern, GraphQL federation | Streaming, multi-device platforms |
| Twilio | Webhooks, error documentation | Messaging, async operations |
| Slack | Event-driven, scoped OAuth | Chat, collaboration, bot platforms |
| REST public + gRPC internal | Any microservices architecture |
You don't need to memorize all of these. Pick 2-3 that are relevant to the system you're designing and reference them naturally in your interview.
Interview Expectations: Junior vs. Senior
- Junior/Mid-level: Solves scalability by "adding more servers" or a generic load balancer without going into the API impact.
- Senior/Staff: Understands that API gateways are critical at scale for cross-cutting concerns (auth, rate limiting, routing). Discusses circuit breakers applied at the API level to prevent cascaded failures across microservices, and bulkheading to isolate resource-heavy endpoints from fast endpoints.