The Relational Model
TL;DR
SQL is the default choice for 90% of system design problems. Modern relational databases scale horizontally with read replicas, connection pooling, partitioning, and tools like Vitess. The myth that "SQL doesn't scale" died years ago — Facebook, Uber, Stripe, and Airbnb all run on SQL at massive scale.
The Restaurant That Already Has Everything
Imagine you're opening a restaurant and someone tells you: "Don't use a kitchen — kitchens can't handle more than 50 orders per night." Meanwhile, every Michelin-star restaurant on the planet uses a kitchen. They just upgraded their equipment, hired more cooks, and organized their workflow.
That's the story of relational databases. For years, the tech industry repeated the mantra that SQL doesn't scale. And for years, the largest companies on Earth kept choosing SQL anyway — because the problem was never the model. It was how you operate it.
The relational model is your kitchen. It's the most versatile, best understood, and most battle-tested data model in existence. Your job in a system design interview is to start here, and only leave when you have a ~~specific reason~~ to leave.
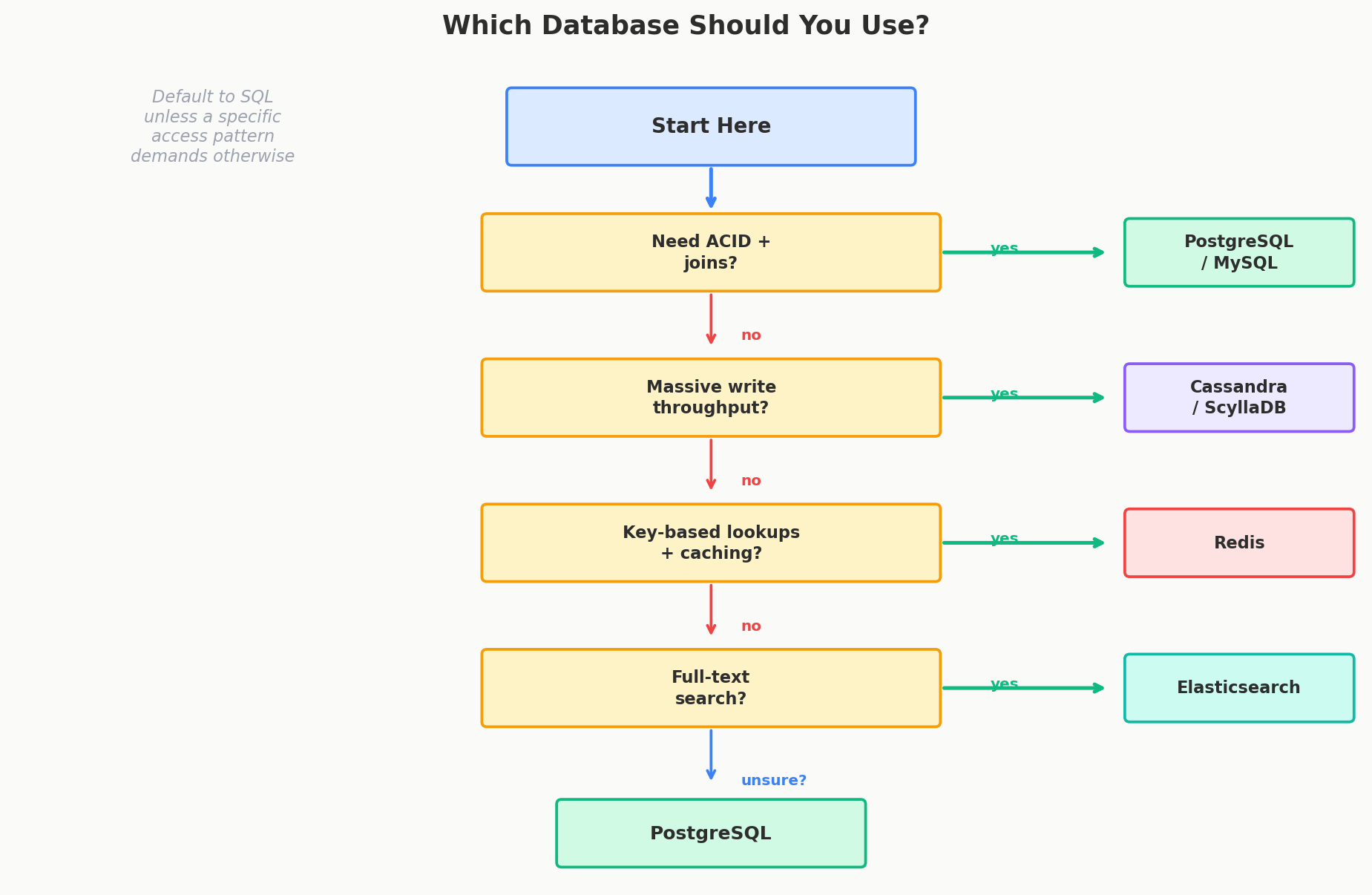
Why SQL Is the Default
The relational model gives you something no other model does out of the box: ~~ACID guarantees~~.
Atomicity — A bank transfer either moves money from account A to account B, or it doesn't happen at all. No half-transfers.
Consistency — Foreign keys, unique constraints, and check constraints enforce your business rules at the database level. Your application can have bugs, but the database won't let invalid data through.
Isolation — Two concurrent transactions don't step on each other. User A buying the last concert ticket doesn't corrupt the data when User B tries to buy it at the same time.
Durability — Once a transaction commits, it's committed. Even if the server crashes one millisecond later, your data survives.
This matters more than most engineers realize. When Stripe processes a payment, they need to guarantee that the charge, the ledger entry, and the balance update all happen atomically. If any one of those fails, money goes missing. ACID is not optional for financial systems — it's the foundation.
Interview Tip
When you pick a relational database in an interview, say why. "I'm choosing PostgreSQL here because we need strong consistency for financial transactions — we can't tolerate a scenario where a payment is recorded but the balance isn't updated." That shows you're making a deliberate choice, not just defaulting.
The Companies That Prove SQL Scales
Let's kill the myth with data:
| Company | Scale | Database | How They Scale It |
|---|---|---|---|
| 2+ billion users | MySQL | TAO layer: graph-like API on top of MySQL shards | |
| Uber | Millions of rides/day | MySQL | Schemaless: append-only layer on top of MySQL |
| Stripe | Billions of API calls/year | PostgreSQL | Sharding, read replicas, careful indexing |
| Airbnb | Millions of listings | MySQL/PostgreSQL | Read replicas, service-oriented architecture |
| GitHub | 100M+ repositories | MySQL | Vitess for horizontal sharding |
Notice the pattern. These companies didn't abandon SQL — they built infrastructure to scale it. The database engine itself was never the bottleneck.
How Modern SQL Actually Scales
Read Replicas
The simplest scaling technique. Most applications are read-heavy (90%+ reads). Writes go to a single primary. Reads are distributed across replicas.
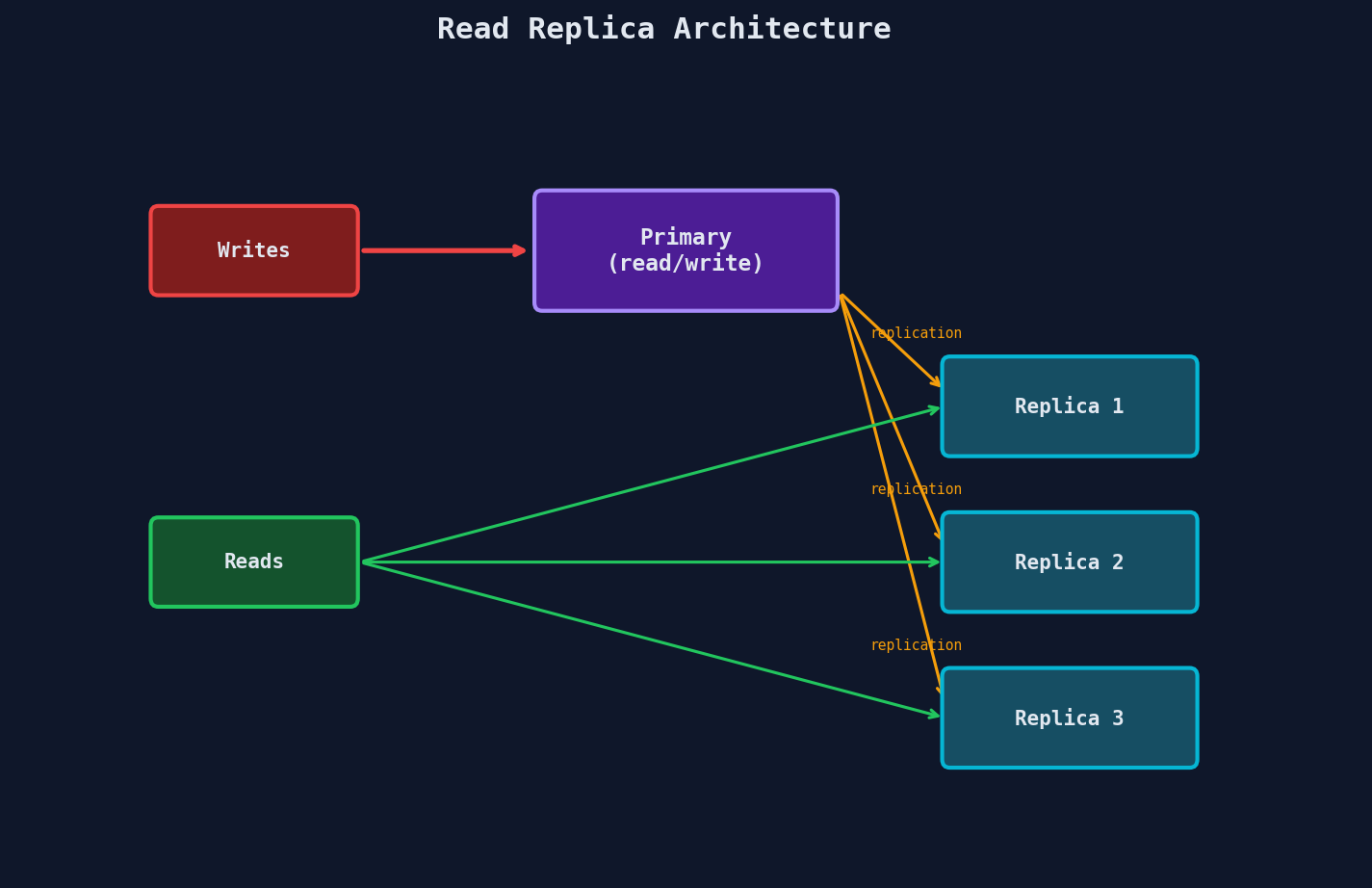
Stripe uses this pattern. Their primary PostgreSQL instance handles writes, while read replicas serve the dashboard, analytics, and reporting queries. This alone gets you surprisingly far.
The trade-off: ~~replication lag~~. A write to the primary might take 10-100ms to propagate to replicas. For most features this is invisible. For critical reads (like checking a balance right after a transfer), you read from the primary.
Connection Pooling (PgBouncer)
A single PostgreSQL instance can handle around 300-500 connections before context switching between connections eats your CPU. But a microservices architecture might have hundreds of services each opening connections.
PgBouncer sits between your application and PostgreSQL, multiplexing thousands of application connections into a much smaller pool of database connections.
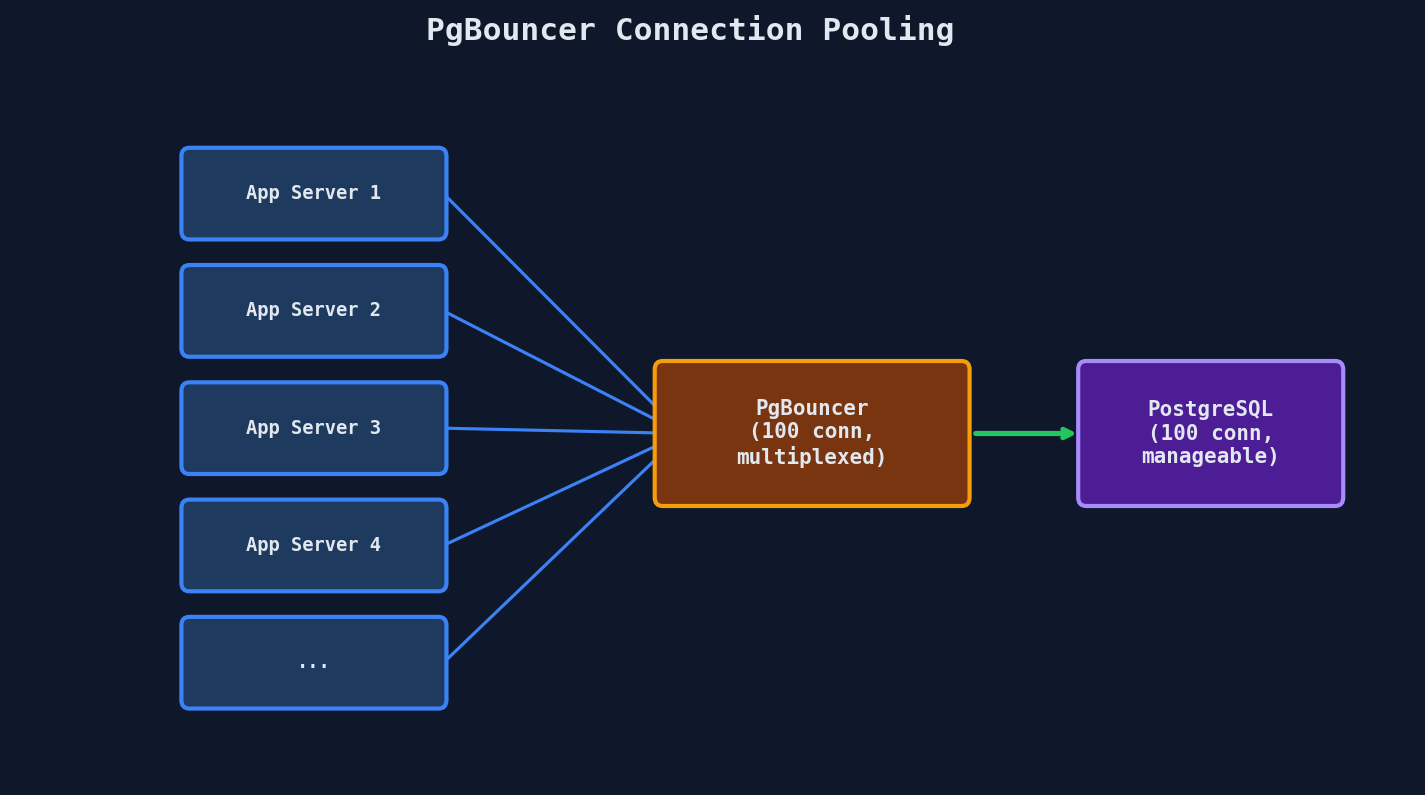
This is table stakes for any production PostgreSQL deployment. Without it, you'll hit connection limits long before you hit actual CPU or I/O limits.
Table Partitioning
When a single table grows to billions of rows, queries slow down even with indexes. Partitioning splits one logical table into multiple physical tables, usually by a range (date) or hash (user ID).
-- Partition orders by month
CREATE TABLE orders (
id BIGINT,
user_id BIGINT,
total DECIMAL(10,2),
created_at TIMESTAMP
) PARTITION BY RANGE (created_at);
CREATE TABLE orders_2025_01 PARTITION OF orders
FOR VALUES FROM ('2025-01-01') TO ('2025-02-01');
CREATE TABLE orders_2025_02 PARTITION OF orders
FOR VALUES FROM ('2025-02-01') TO ('2025-03-01');
Now a query for January orders only scans the January partition. The database prunes irrelevant partitions automatically.
Vitess — Horizontal Sharding for MySQL
Vitess is a database clustering system that sits between your application and MySQL. It was built at YouTube, and now powers GitHub, Slack, and Square.
It handles what application-level sharding makes painful: - Automatic shard routing — queries are routed to the correct shard based on the sharding key - Online schema changes — ALTER TABLE on a billion-row table without downtime - Connection pooling — built-in, like PgBouncer but for MySQL - Cross-shard queries — scatter-gather across shards when needed (expensive, but possible)
NewSQL — Distributed SQL That Just Works
If you want SQL semantics with automatic horizontal scaling, NewSQL databases eliminate the need for manual sharding.
CockroachDB: Uses Raft consensus to replicate data across nodes. Automatically splits ranges when they get too large. Feels like a single PostgreSQL instance, but data is distributed across a cluster.
Google Spanner: Uses TrueTime (atomic clocks + GPS) to provide ~~external consistency~~ — the strongest consistency guarantee possible in a distributed system. Used internally by Google for AdWords, Google Play, and Cloud Spanner.
Both support standard SQL, full ACID transactions, and scale horizontally by adding nodes. The trade-off is latency — distributed consensus adds milliseconds per transaction compared to a single-node database.
When Relational Is NOT the Right Choice
SQL is the default, but it's not always the answer. Here are the specific situations where you should reach for something else:
| Scenario | Why SQL Struggles | Better Option |
|---|---|---|
| Very high write throughput (100K+ writes/sec) | Single-primary bottleneck | Wide-column (Cassandra, ScyllaDB) |
| Rapidly evolving schema | ALTER TABLE on large tables is expensive | Document store (MongoDB, DynamoDB) |
| Simple key-value lookups with sub-millisecond latency | SQL parsing overhead is unnecessary | Key-value (Redis, DynamoDB) |
| Full-text search with ranking | SQL LIKE is slow, no relevance scoring | Search engine (Elasticsearch) |
| Deeply nested, hierarchical data | Joins get expensive at many levels | Document store or graph database |
The key phrase is "specific access pattern." Don't pick MongoDB because "we might need flexibility later." Pick it because your data is genuinely hierarchical and you've identified that joins would be expensive for your primary access pattern.
Blob and Object Storage — Where Large Files Go
One critical pattern that comes up in almost every media-heavy design (Instagram, YouTube, Dropbox): don't store large binary files in your relational database.
Images, videos, PDFs, and other large blobs belong in object storage (Amazon S3, Google Cloud Storage, Azure Blob Storage), not in PostgreSQL. Your relational database stores the metadata — filename, owner, upload timestamp, content type — with a URL pointing to the object in S3.
users table: id, username, avatar_url → "s3://bucket/avatars/user-42.jpg"
posts table: id, user_id, caption, media_url → "s3://bucket/posts/post-500.mp4"
Why not store blobs in the database? - A 5MB image in a PostgreSQL row bloats the table, slows backups, and wastes buffer pool memory - S3 is designed for durability (99.999999999% — eleven nines), cheap storage, and high throughput - CDN integration: serve media from edge locations worldwide via pre-signed URLs
The pattern: PostgreSQL for metadata + relationships, S3 for binary payloads, CDN for delivery.
Interview Tip
Whenever your system design involves images, videos, or file uploads, immediately say: "I'll store the file in S3 and keep a reference URL in the database. For delivery, I'd put a CDN in front of S3 with pre-signed URLs for access control." This is expected — skipping it is a red flag.
Interview Tip
If an interviewer pushes back with "but what about scale?", don't panic. Walk through the scaling playbook: read replicas first, then connection pooling, then partitioning, then sharding via Vitess or migrating to NewSQL. Most systems never need to go past step two. Showing you understand ~~when~~ each step is necessary is more impressive than jumping straight to Cassandra.
Quick Recap
| Concept | Key Point |
|---|---|
| ACID | Atomicity, Consistency, Isolation, Durability — SQL gives you all four by default |
| Read Replicas | Scale reads horizontally; writes still go to the primary |
| Connection Pooling | PgBouncer multiplexes connections; essential for production PostgreSQL |
| Partitioning | Split large tables by range or hash for faster queries |
| Vitess | Horizontal sharding for MySQL; used by GitHub, Slack, YouTube |
| NewSQL | CockroachDB, Spanner — distributed SQL with ACID and automatic scaling |
| When to leave SQL | High write throughput, flexible schema, key-value access, full-text search |