Why Multi-step Is Hard
TL;DR
A simple e-commerce order — charge card, reserve inventory, schedule shipping, send confirmation — looks like five lines of code. In a distributed system, each of those steps can fail independently, leaving your order in an impossible half-completed state. The core difficulty is that business logic (what should happen) gets hopelessly tangled with infrastructure concerns (retries, crashes, timeouts, compensation), creating an operational nightmare that only gets worse as you add steps.
Six Little Lines of Fail
Jimmy Bogard gave a famous talk with this title. The premise is brutally simple: write the code for placing an order.
def place_order(order):
charge_payment(order)
reserve_inventory(order)
schedule_shipping(order)
send_confirmation_email(order)
update_order_status(order, "completed")
Five function calls. Reads like a recipe. Ship it.
Except every single line is a network call to a different service. And networks lie, crash, timeout, duplicate, and reorder. That innocent-looking code is a minefield.
The Happy Path Is a Fairy Tale
Here's what the flow looks like when everything works:
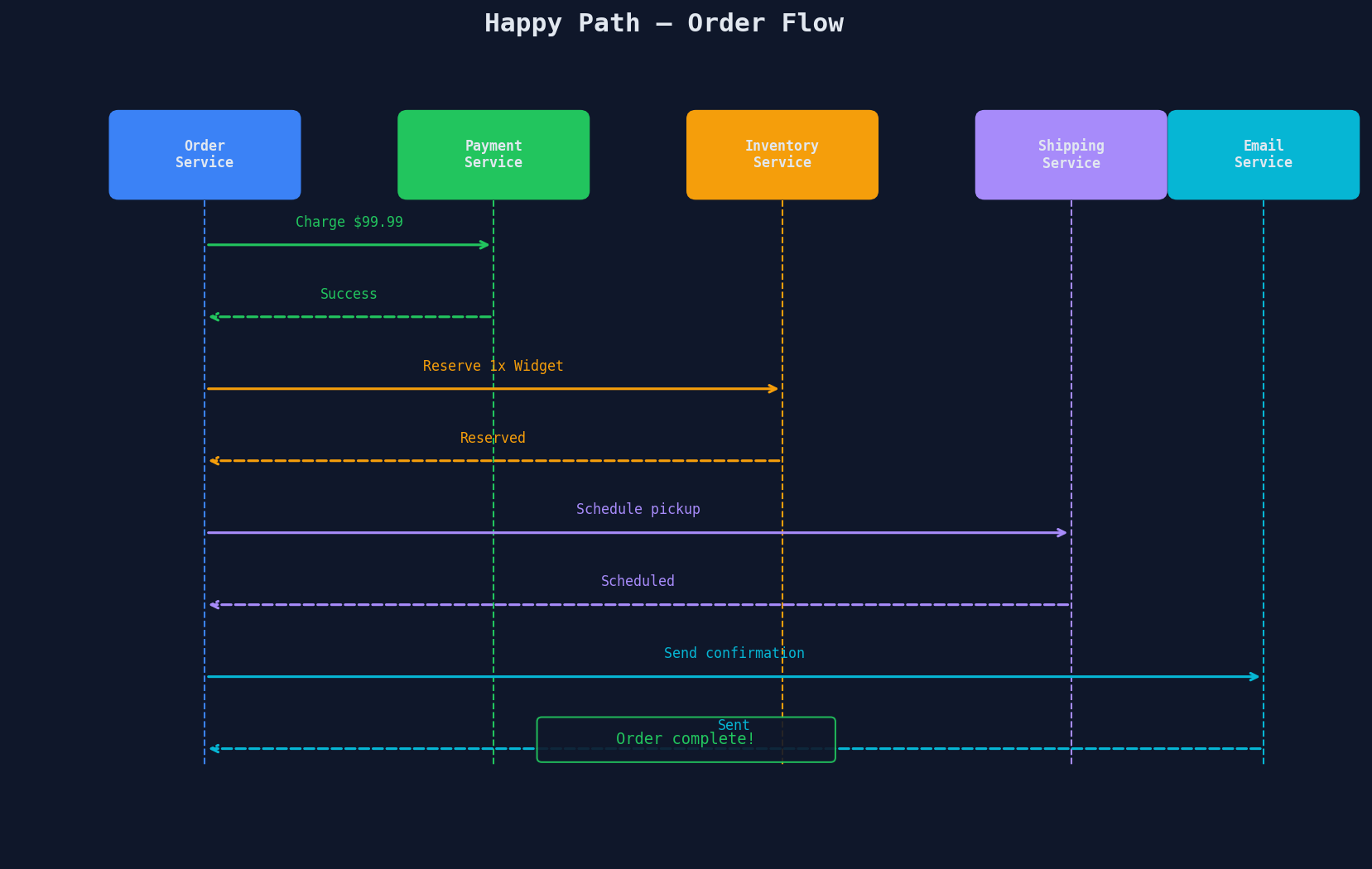
Beautiful. Now let's ruin it.
Every Line Is a Failure Point
Mark every transition in that sequence where something can go wrong:
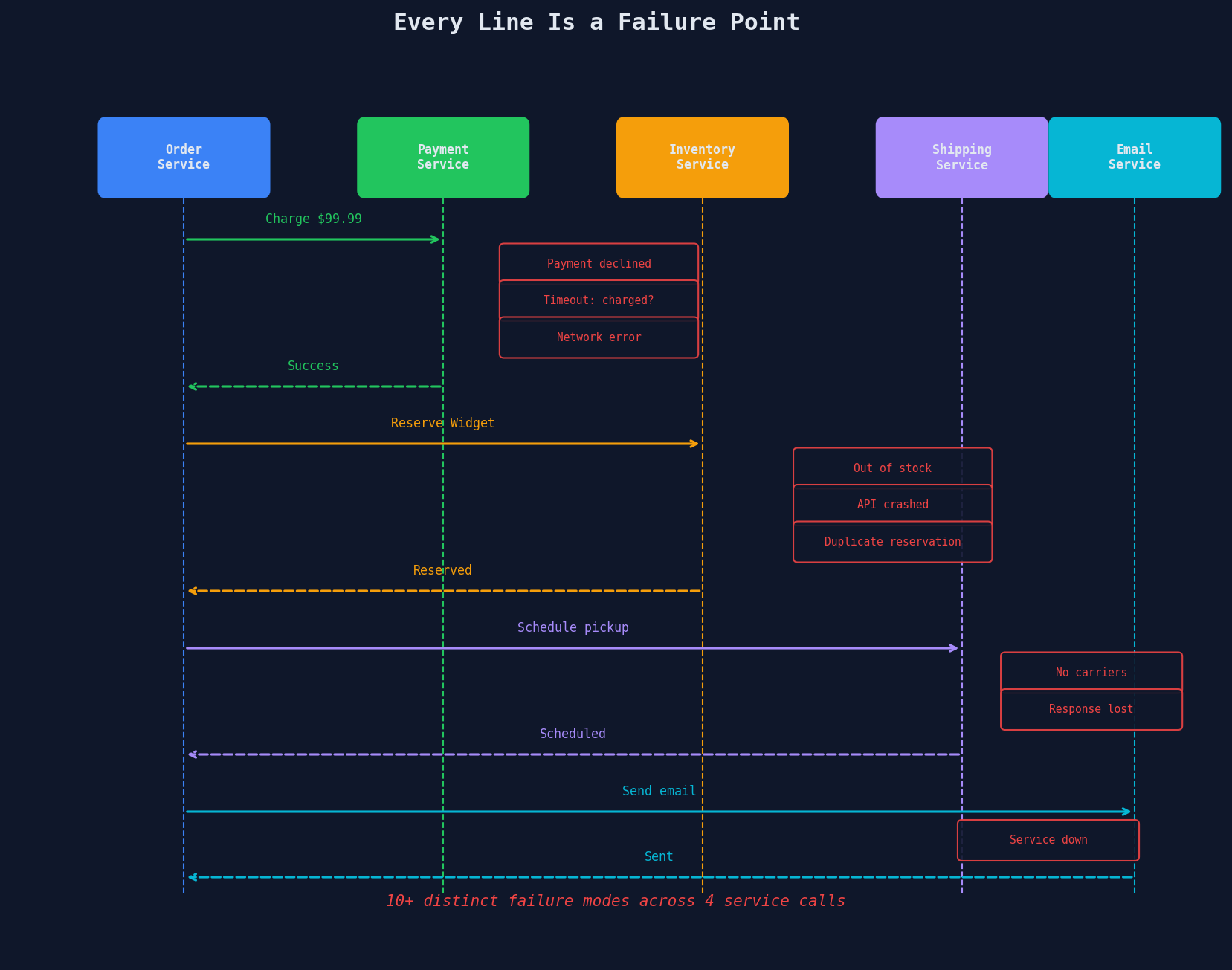
Count the failure modes: at least ten distinct things can go wrong. And those are just the obvious ones. We haven't even talked about the Order Service itself crashing between steps.
The Three Killer Scenarios
Scenario 1: Payment Succeeds, Inventory Fails
The customer's credit card is charged $99.99. Then the inventory service reports "out of stock." Now you have a charged customer with no product to send them.
What should happen? Refund the payment. But what if the refund call also fails? What if it times out — did the refund go through or not? You've escalated from one failure to a cascading mess.
Timeline of Pain:
─────────────────────────────────────────────
t1: Charge card → $99.99 deducted ✓
t2: Reserve inventory → OUT OF STOCK ✗
t3: Refund card → TIMEOUT ???
─────────────────────────────────────────────
Customer sees: $99.99 charged, no order, no refund
Support ticket incoming.
Scenario 2: Server Crashes Between Steps
Your Order Service process dies after charging the payment but before reserving inventory. The customer's money is gone. There's no record of where the workflow stopped. When the server restarts, it has no idea this order was in flight.
This is the durability problem. In-memory state is ephemeral. If your workflow lives only in a running process, a crash erases it from existence.
Scenario 3: A Human Is in the Loop
The shipping step requires a warehouse worker to physically pick the item off a shelf. That takes hours, not milliseconds. Your API call is going to sit there with an open HTTP connection for... three hours?
No. You need asynchronous handoffs, callbacks, timers, and timeout policies. Suddenly your "five lines of code" needs to handle time scales from milliseconds to days.
The Timeout Trap
When a service call times out, you don't know if the operation succeeded or failed. Maybe the payment went through and the response got lost. Maybe the payment service is still processing. Retrying might double-charge the customer. Not retrying might leave them uncharged. Timeouts are the worst failure mode because they give you zero information.
The Root Cause: Tangled Concerns
Pull back and look at what happened to our five-line function. To handle failures properly, it needs:
| Concern | What It Adds |
|---|---|
| Retries | Retry logic for each step, with backoff and jitter |
| Idempotency | Ensure retries don't duplicate charges or reservations |
| Compensation | Undo completed steps when a later step fails |
| Persistence | Save progress so crashes don't lose state |
| Timeouts | Handle slow steps that take hours or days |
| Observability | Track which step each order is on |
| Dead letters | Handle permanently failing steps |
| Alerting | Notify humans when automated recovery fails |
That five-line function balloons into something like this:
def place_order(order):
# Check if we already started this order (crash recovery)
state = load_workflow_state(order.id)
if state.step < 1:
for attempt in range(3):
try:
result = charge_payment(order, idempotency_key=order.id)
save_state(order.id, step=1, payment_id=result.id)
break
except Timeout:
if attempt == 2:
mark_failed(order.id, "payment_timeout")
alert_ops_team(order.id)
return
sleep(2 ** attempt) # exponential backoff
if state.step < 2:
for attempt in range(3):
try:
reserve_inventory(order, idempotency_key=order.id)
save_state(order.id, step=2)
break
except OutOfStock:
# Compensate: refund the payment
refund_payment(state.payment_id)
save_state(order.id, step=-1, status="cancelled")
return
except Timeout:
# ... more retry logic ...
pass
# ... 50 more lines of infrastructure plumbing ...
The actual business logic — charge, reserve, ship, email — is buried under an avalanche of infrastructure code. Retries wrap compensation wraps persistence wraps timeout handling. Nobody can read this. Nobody can modify it safely. And it's still probably wrong.
Interview Tip
When you spot a multi-step distributed process in an interview, call it out explicitly: "This workflow spans multiple services, so we need to handle partial failures. Should I walk through the failure modes?" This signals maturity. Junior candidates describe the happy path. Senior candidates immediately think about what breaks.
Why This Gets Exponentially Worse
Every step you add doesn't just add one failure mode — it multiplies them. With N steps, you have:
- N possible crash points (server dies between any two steps)
- N timeout scenarios (any step can hang)
- N compensation actions (each completed step may need undoing)
- N x (N-1) / 2 partial completion states (combinations of done/not-done)
A 10-step workflow has over 1,000 possible failure states. Good luck handling those with if-else chains.
The Fundamental Tension
Here's the core insight that frames the rest of this chapter:
┌─────────────────────────────────────────────────────┐
│ │
│ Business logic says: │
│ "Charge → Reserve → Ship → Confirm → Email" │
│ │
│ Infrastructure reality says: │
│ "Any step can fail, timeout, duplicate, or take │
│ hours. Crashes erase in-memory state. Networks │
│ are unreliable. You must handle every │
│ combination of partial completion." │
│ │
│ The challenge: │
│ Keep these two concerns SEPARATED so your │
│ business logic stays readable and your │
│ infrastructure handling stays robust. │
│ │
└─────────────────────────────────────────────────────┘
This is what the next three lessons solve, each with a different level of sophistication:
| Lesson | Approach | Core Idea |
|---|---|---|
| Lesson 2 | Evolution of solutions | From naive orchestration to event-driven to durable execution |
| Lesson 3 | Workflow orchestration | Temporal, Step Functions, Conductor — frameworks that separate business logic from infrastructure |
| Lesson 4 | Idempotency and compensation | The patterns that make individual steps safe to retry and undo |
The goal is the same in every case: write your business logic as if failures don't exist, and let the infrastructure layer handle the mess.
Quick Recap
| Concept | Key Takeaway |
|---|---|
| Six lines of fail | Simple sequential code hides catastrophic distributed failure modes |
| Payment + inventory mismatch | Partial completion leaves the system in an inconsistent state |
| Server crash | In-memory workflow state is lost forever on crash |
| Human-in-the-loop | Some steps take hours/days, not milliseconds |
| Tangled concerns | Business logic drowns in retry/compensation/persistence code |
| Exponential blowup | N steps create 2^N possible failure states |
Interview Tip
The phrase "partial failure" is your best friend in system design interviews. Distributed systems don't fail cleanly — they fail partially. One service succeeds while another times out. Saying "we need to handle partial failures across these services" immediately tells the interviewer you understand the fundamental challenge of distributed workflows.